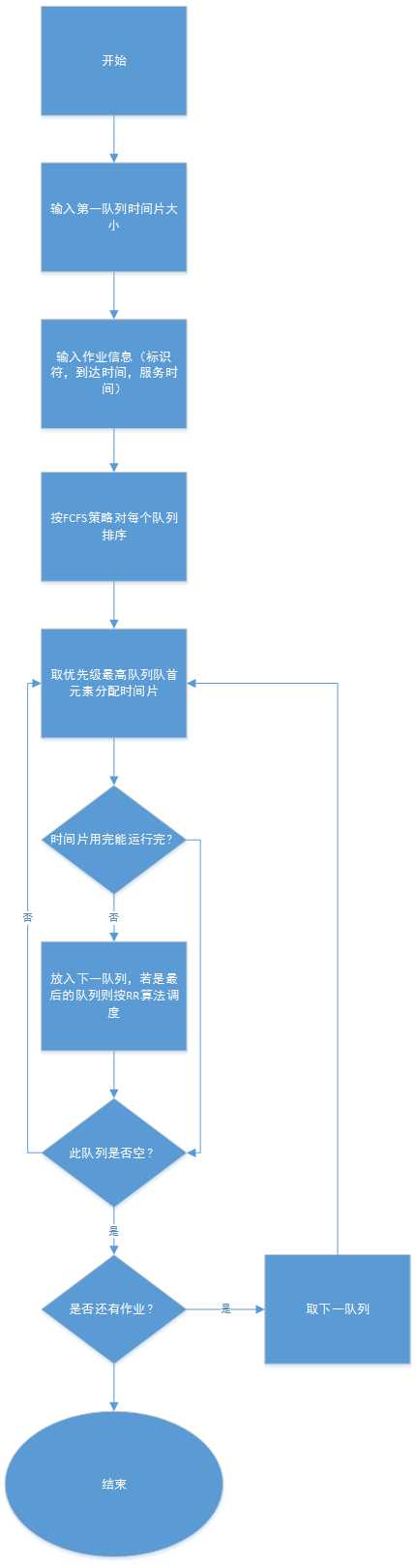
文章目录
- 前言
- 一、需求背景
- 二、坑
- 2.1 坑一
- 2.2 坑二
- 总结
前言
记录下在公司做需求时must_not踩的坑
一、需求背景
要去做人才库的一个排除项:排除x个月面试不通过。实际上的dsl语句则对应的是must_not。且内部要包含两个元素:x个月、面试不通过(C、D)取交集。
二、坑
2.1 坑一
目标测试数据为:
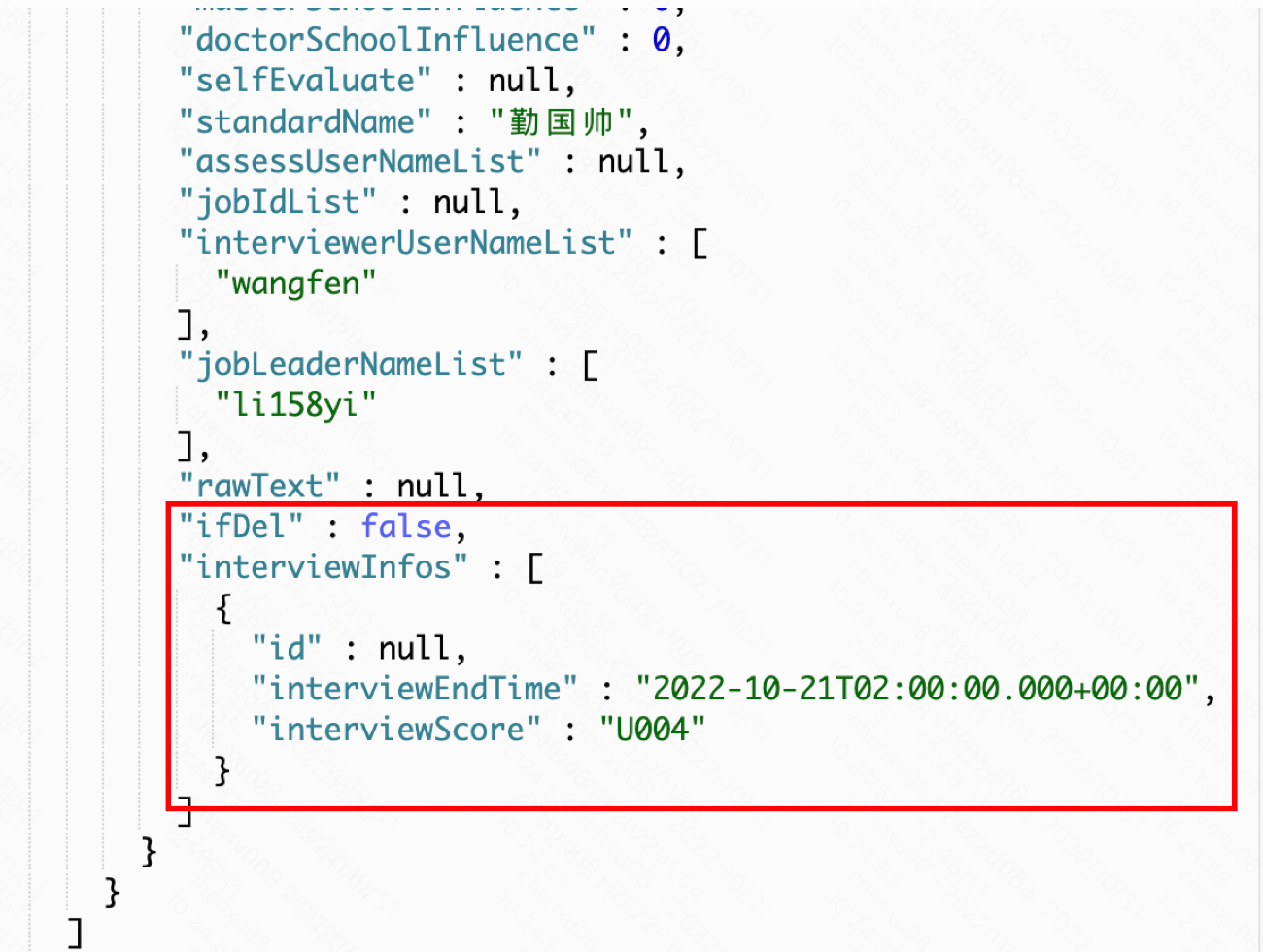
这是一条面试时间为10.21、且面评不合格的一条数据。
一开始拼接的dsl语句为(to默认为当前时间戳):
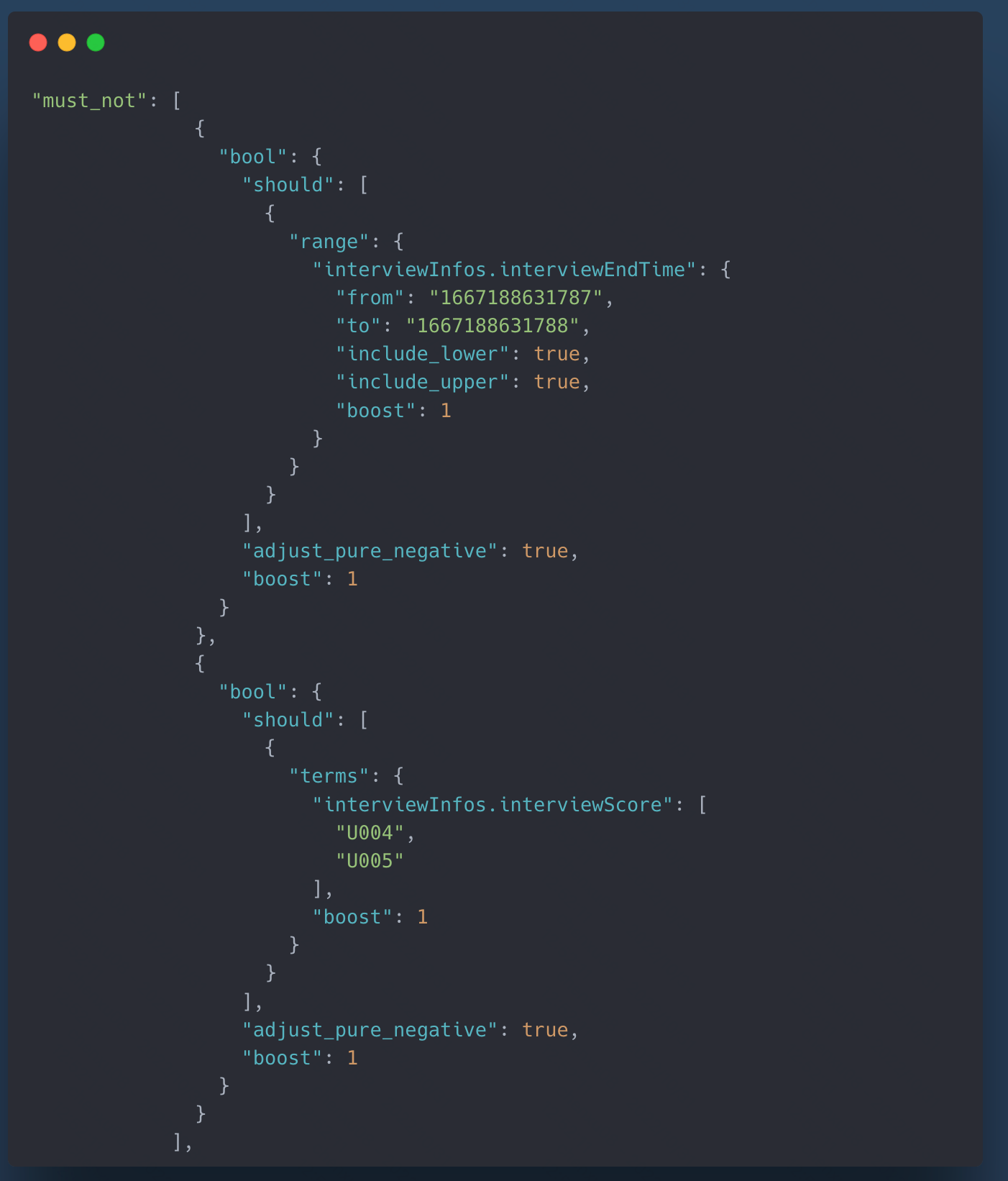
- 在must_not中同时拼接两个条件:1毫秒前面试不通过的,按理来说应该出现目标数据。可是确没有命中。
- 接下来开始排查,将下面关于面试不通过的去掉:
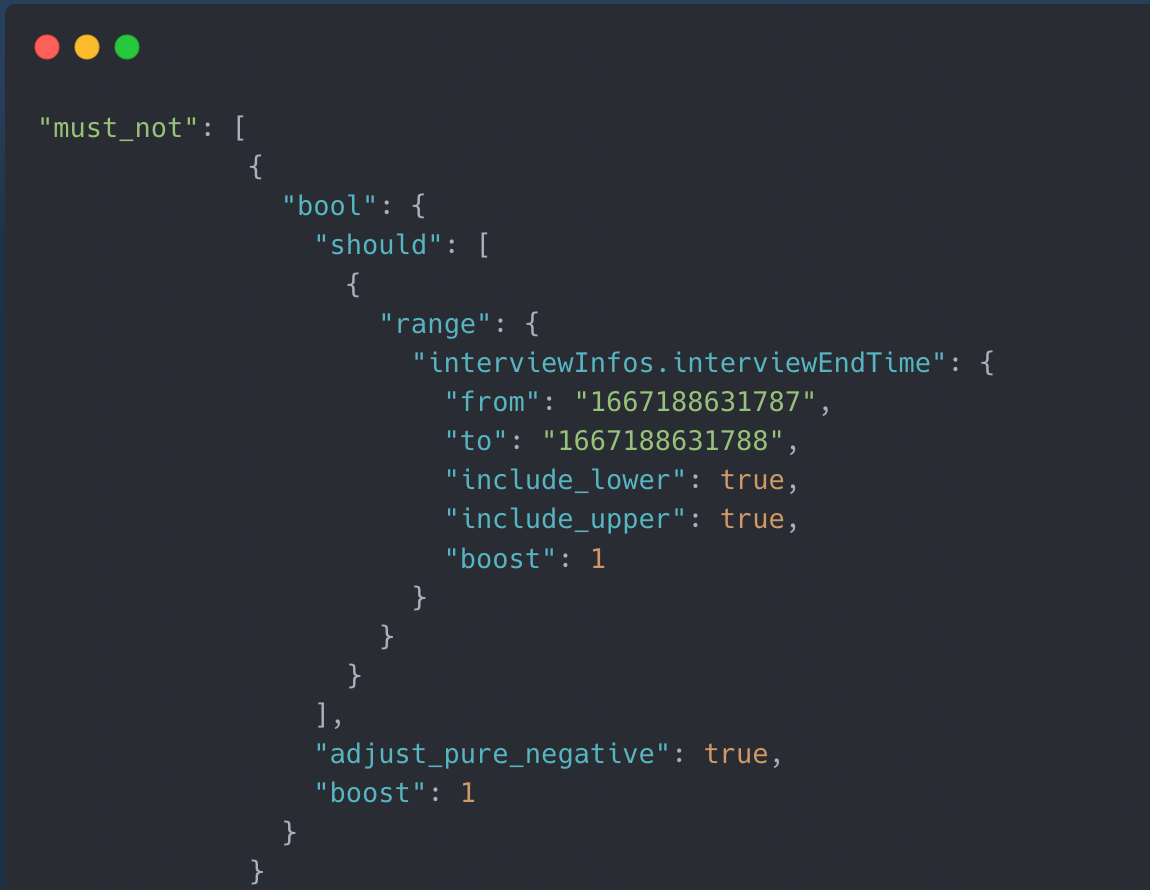
发现可以hit:
再换成将上面的时间去掉,发现找不到,符合预期结果。
那么可以猜想:内层单个的should都生效了,问题点出现在了外层的must_not联合的作用上。
直观点表示就是预期本来是这样的:

可是实际上却变成了这样:
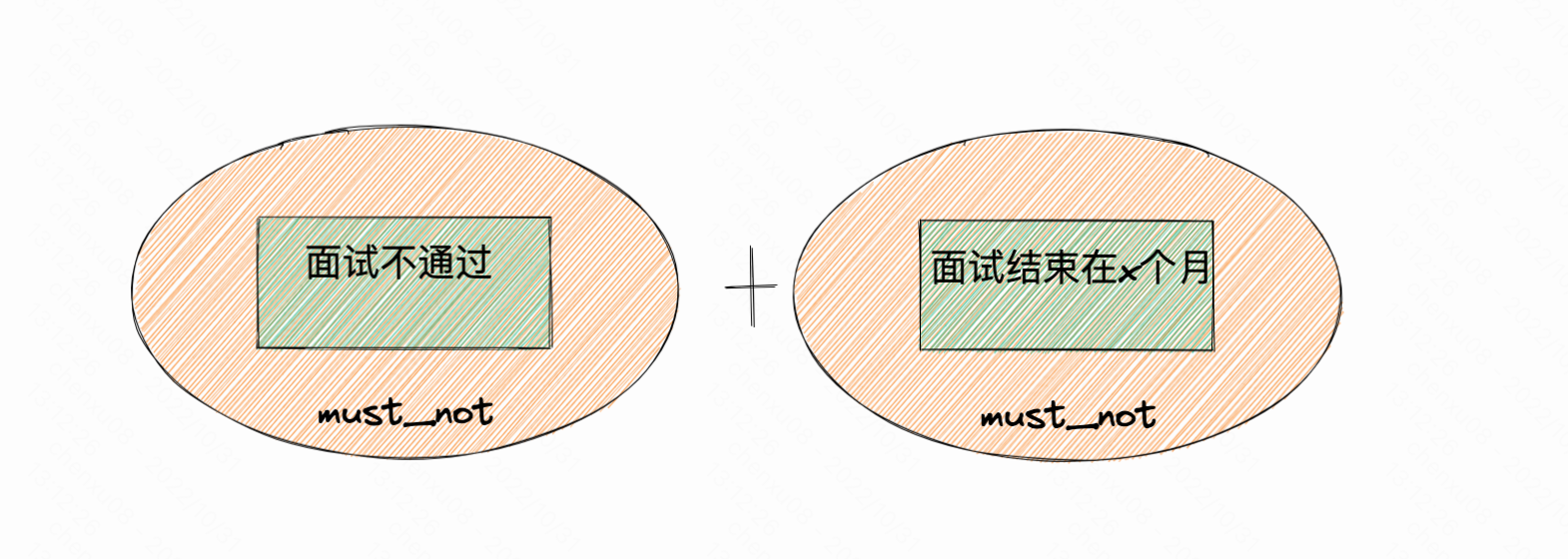
以至于这条数据在内层因为面试不通过就被筛出来了,而无关面试结束在x个月。最后再来一个must_not导致无法hit。
- 那么为了验证我们的猜想可以做这样的操作:
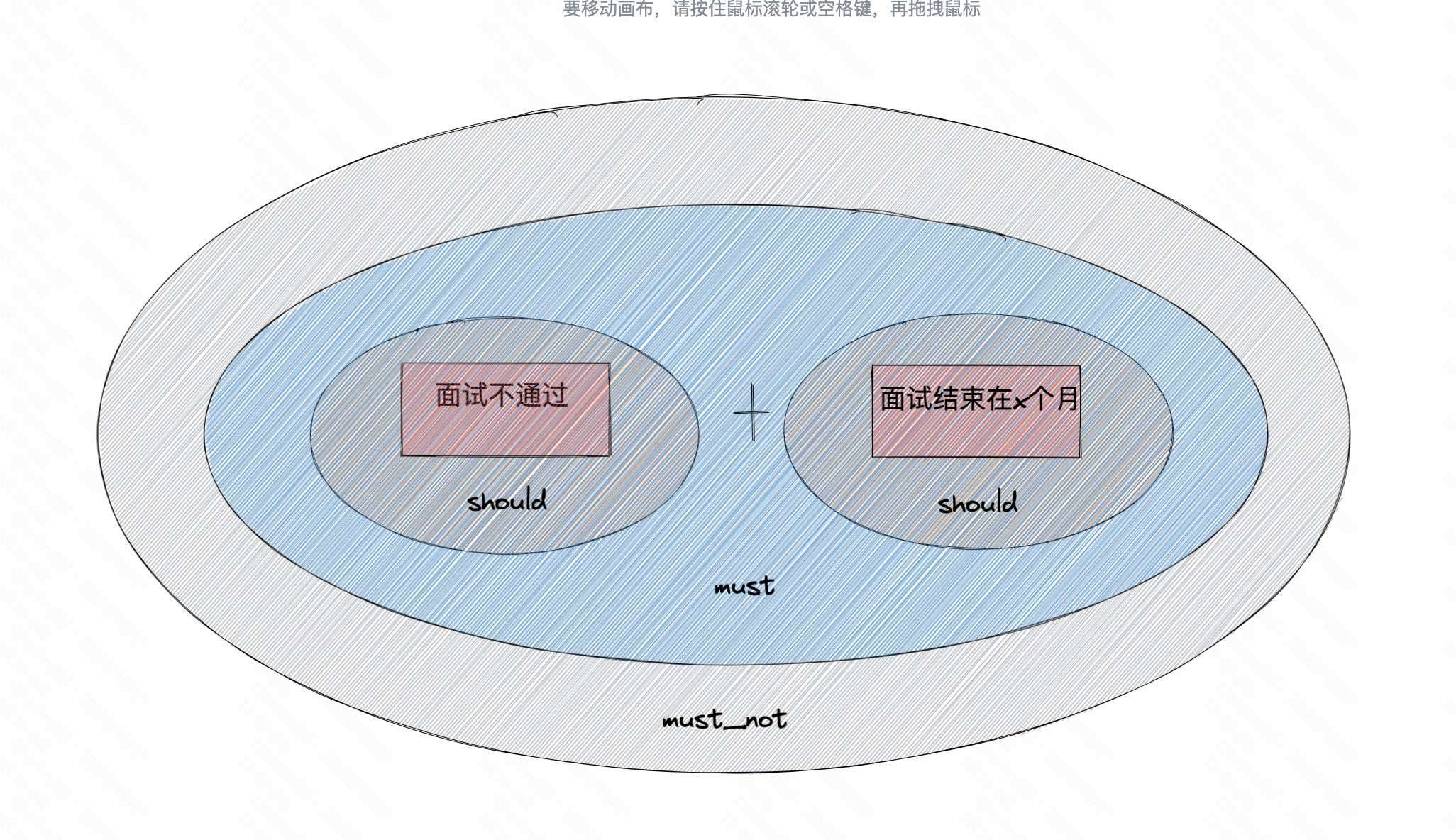
也就是在之间再通过must将两者关联起来,再来一个must_not。对应的dsl语句为:
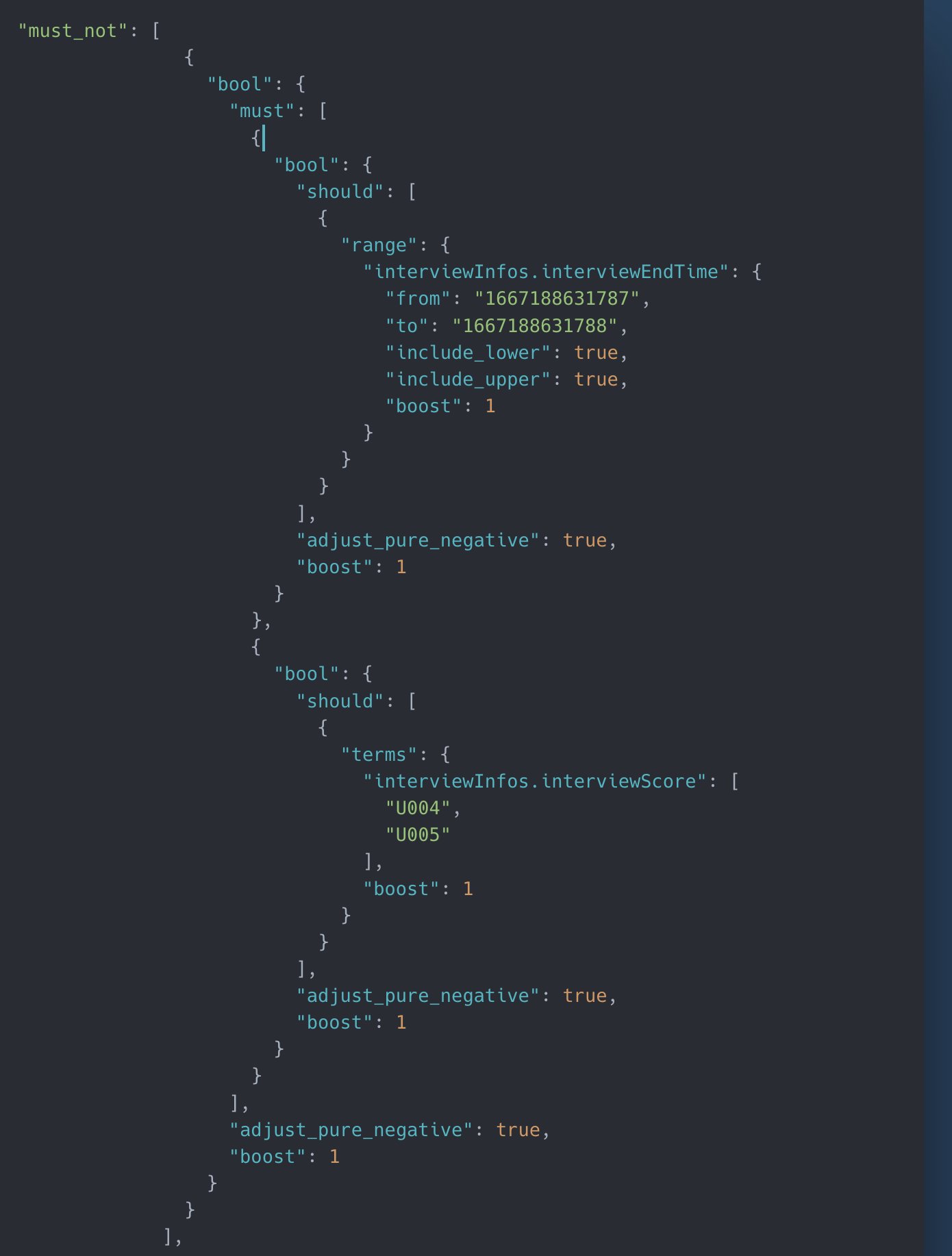
这时候再来试一次:
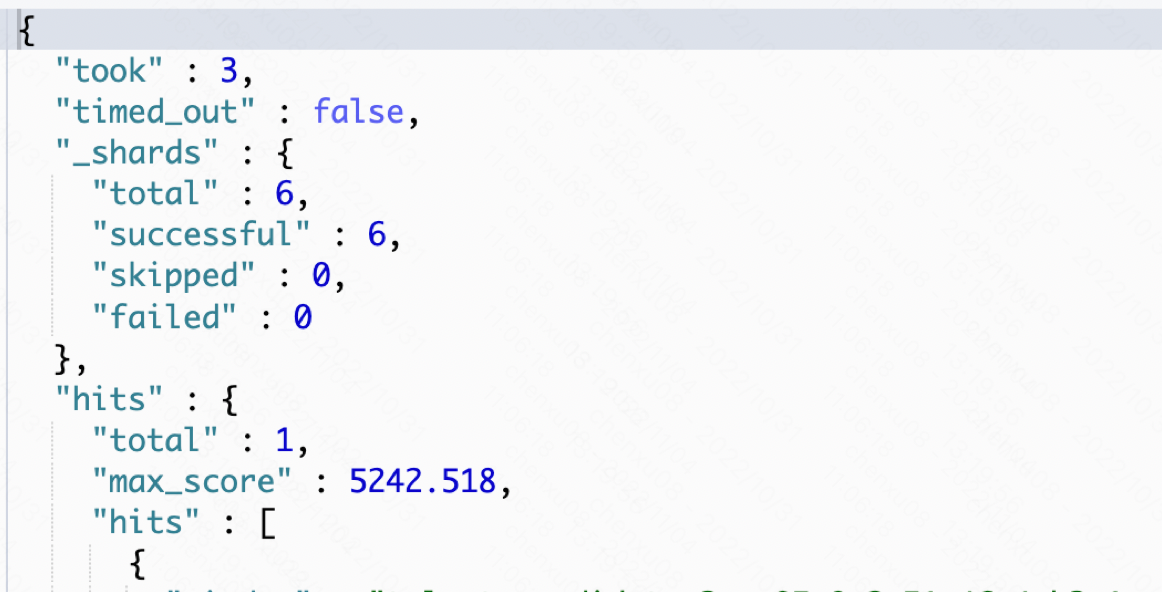
发现可以命中的到,而改大时间范围:
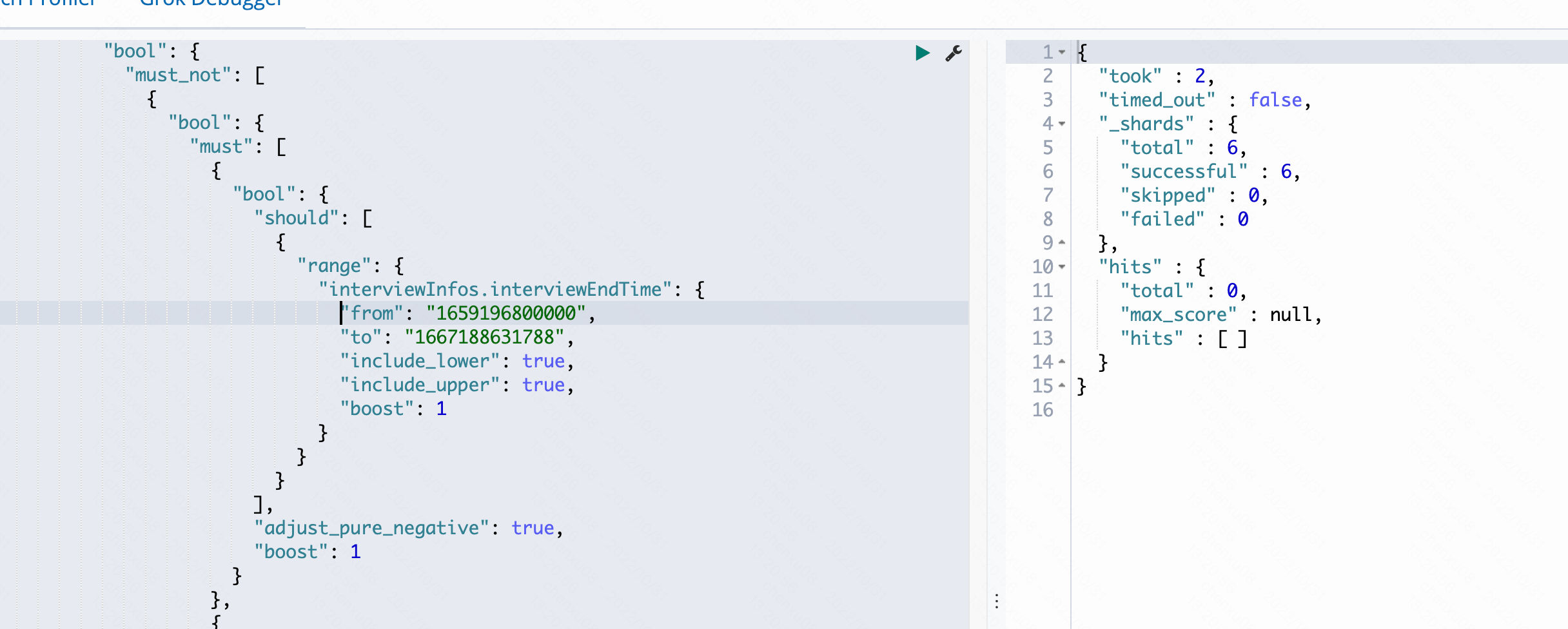
发现已经搜索不到了。这时就可以得出结论。 - 对于must_not中有多个must或者should(如果是should得保证同级没must具体见官方文档),他其实是must_not:must + must_not:must。而不是内层先进行包含,最后再进行must_not。如果要实现内层包含。则应该内层嵌套一个must进行联合。
2.2 坑二
- 还是对于同一个需求,虽然改好了上面的漏洞。但是其实还是有一个问题:上面的数据其实为在nested列表对象下长度为1的一条数据。那么试想一下换另外一条数据呢?
例如:

那么这条数据如果在面试在超过这个时间不通过的情况下对于上面的数据理应不该被搜出来。
可是如果是用刚刚拼接好的完整dsl:
"nested": {"query": {"bool": {“must_not": [{"bool": {"must": [{"bool": {"should": [{"range": {"interviewInfos.interviewEndTime": {"from": "1651388570","to": "1667185560684","include_lower": true,"include_upper": true,"boost": 1}}}],"adjust_pure_negative": true,"boost": 1}},{"bool": {"should": [{"terms": {"interviewInfos.interviewScore": ["U004","U005"],"boost": 1}}],"adjust_pure_negative": true,"boost": 1}}]}}],"adjust_pure_negative": true,"boost": 1}},"path": "interviewInfos","ignore_unmapped": false,"score_mode": "max","boost": 0}"nested": {"query": {"bool": {“must_not": [{"bool": {"must": [{"bool": {"should": [{"range": {"interviewInfos.interviewEndTime": {"from": "1651388570","to": "1667185560684","include_lower": true,"include_upper": true,"boost": 1}}}],"adjust_pure_negative": true,"boost": 1}},{"bool": {"should": [{"terms": {"interviewInfos.interviewScore": ["U004","U005"],"boost": 1}}],"adjust_pure_negative": true,"boost": 1}}]}}],"adjust_pure_negative": true,"boost": 1}},"path": "interviewInfos","ignore_unmapped": false,"score_mode": "max","boost": 0}
但是结果是会hit,而不会被排除。
那么接下来继续排查,排查的一个关键点在于我直接把最外层的must_not直接改成must。
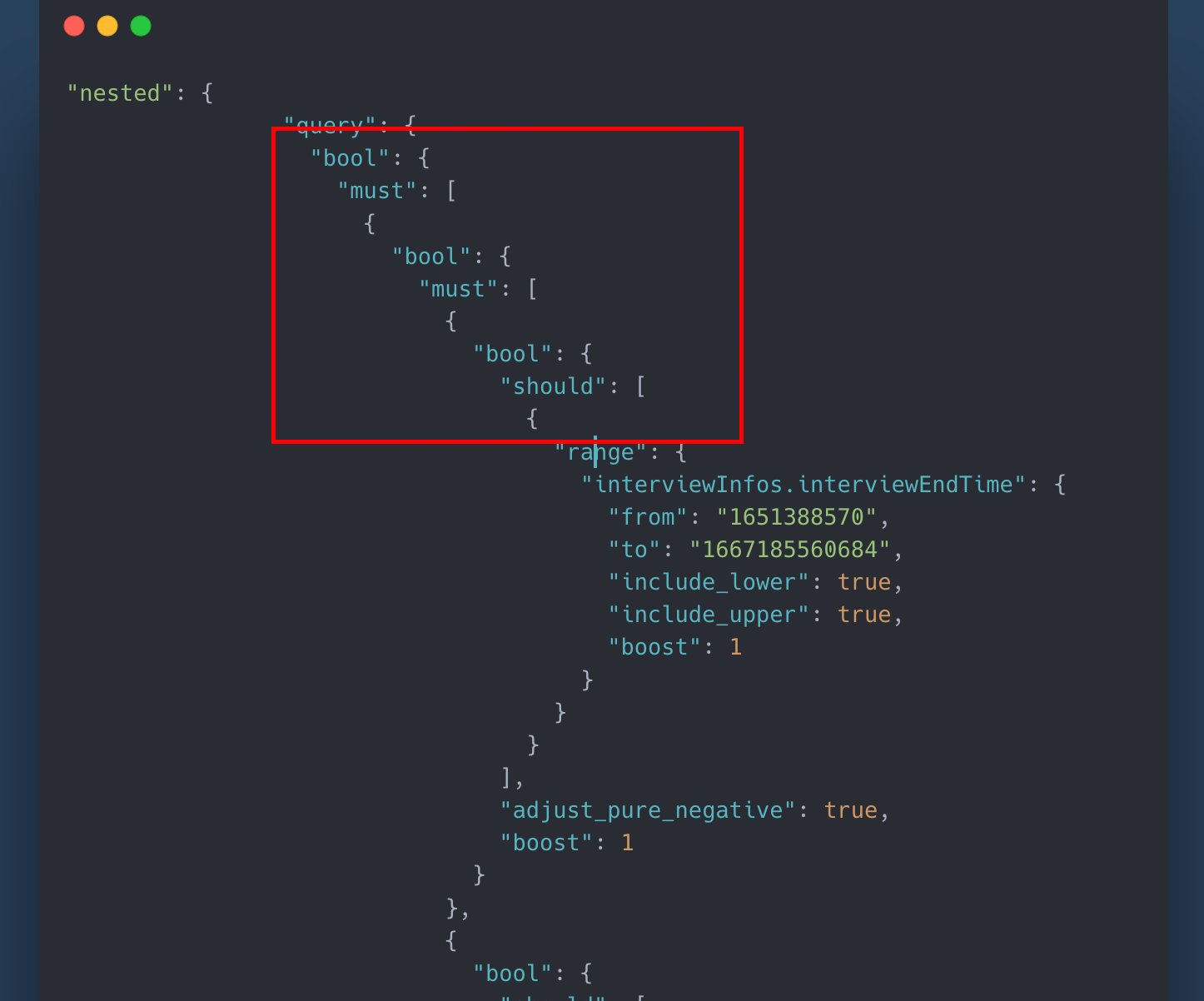
发现直接取反后的结果竟然也是被hit到了,也就是最外层的must/must_not的结果失效了。
那么比对一下两者数据的差别:在于nested的数据长度上。
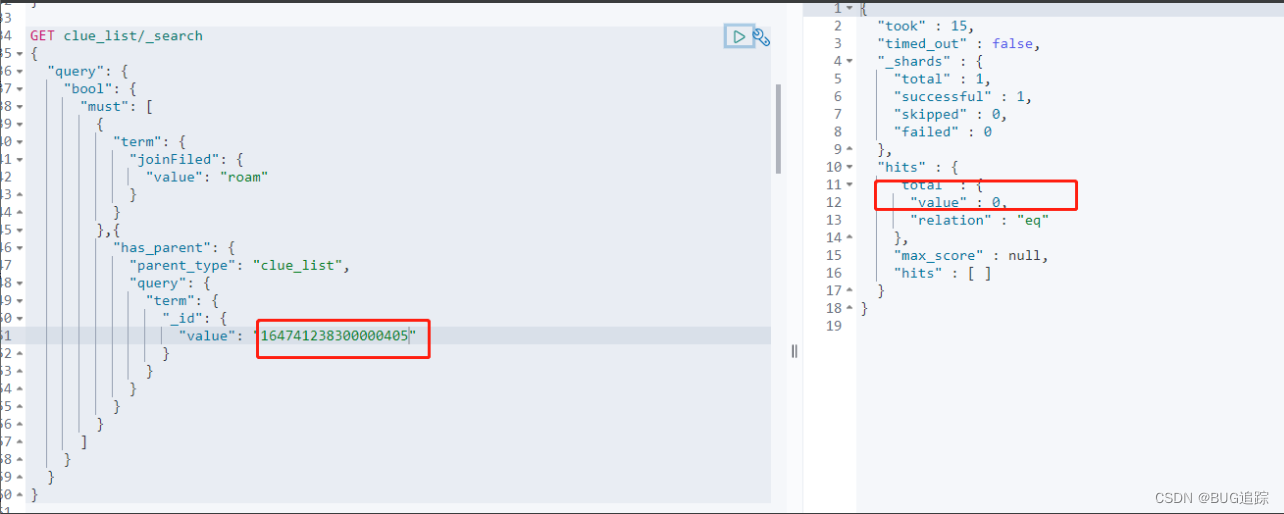
那么可以得到一个猜想:关于nested内的must,must_not,最终只是hit其中一段元数据。也就是虽然这个数据被排除了,但是这个nested列表中的第二条、第三条… hit了,那么这个候选人依旧可以选出来。也就是说红框这部分被搜索出来了:
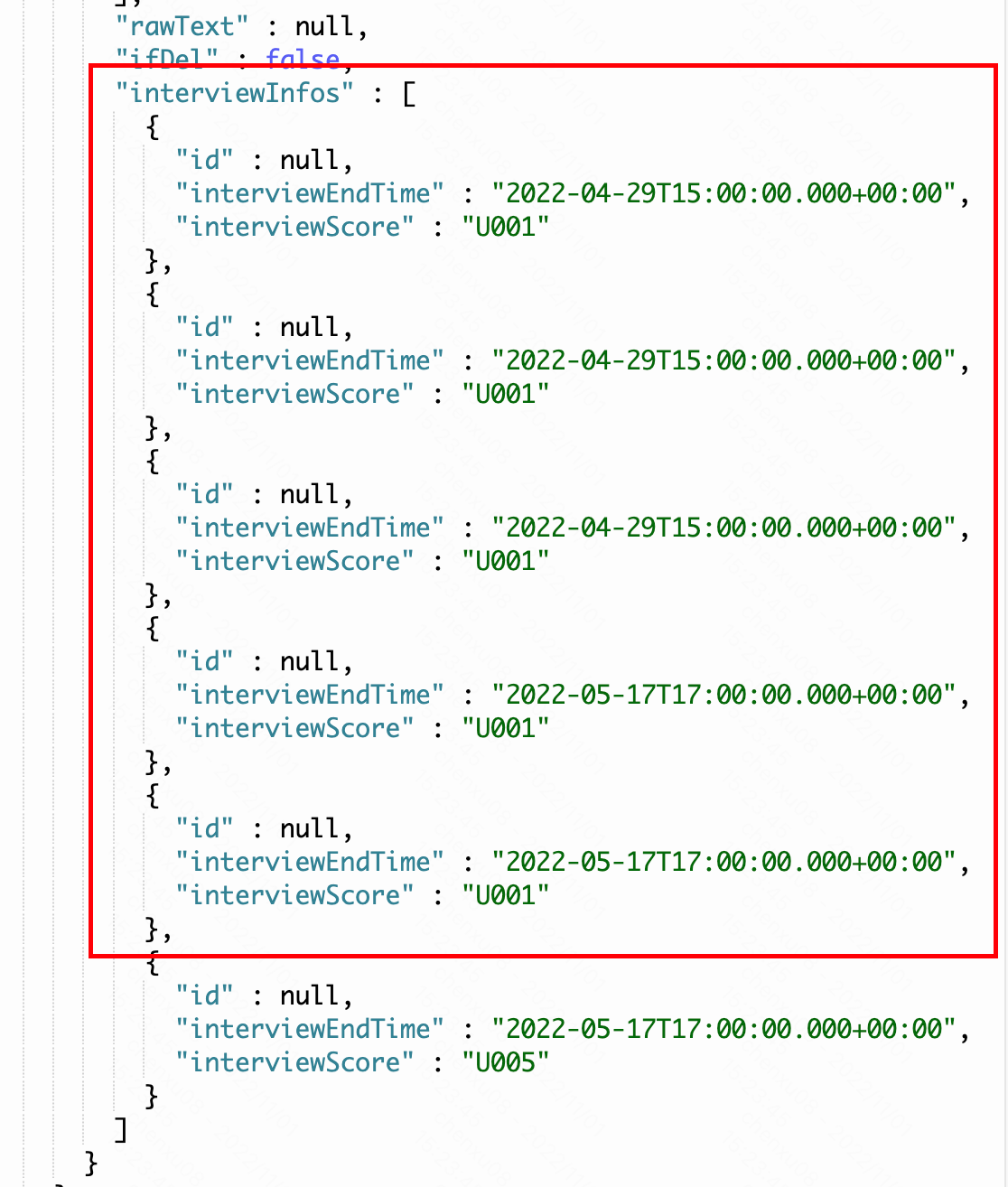
如果想要排除这个人,那么可以猜想需要直接把must_not放在nested外面。也就是:
"must_not": [{ "nested": {"query": {"bool": {"must": [{"bool": {"must": [{"bool": {"should": [{"range": {"interviewInfos.interviewEndTime": {"from": "1667203393540","to": "1667203393541","include_lower": true,"include_upper": true,"boost": 1}}}],"adjust_pure_negative": true,"boost": 1}},{"bool": {"should": [{"terms": {"interviewInfos.interviewScore": ["U004","U005"],"boost": 1}}],"adjust_pure_negative": true,"boost": 1}}]}}],"adjust_pure_negative": true,"boost": 1}},"path": "interviewInfos","ignore_unmapped": false,"score_mode": "max","boost": 0}}],
修改发现符合最终需要的结果。
总结
踩了这几个坑,虽然写出来排查的过程很简单,但实际还是挺头疼的,需要不断的进行变量对比。不断的去写dsl语句,最终在文中只是关键的排查点。得到的经验也很简单,要从最里层一层一层的扒。每个must,must_not就像一层层列表便利,只不过每次遍历就是must,must_not中的元素。