ChatGPT的access_token获取(最新!!!)
序言
最近在搞移动应用开发,心血来潮写了个chatGPT的app,但是接口只能用官网提供的,我自己的号没有免费额度,朋友的号也就5$的额度,用不了几下就没有了,于是我准备会一会这个chatGPT!
登录流程分析
1.准备工作
首先复制下面这个链接并进入,并打开抓包工具(F12),如图所示,把Cookie给删除掉
https://chat.openai.com/auth/login?iss=https%3A%2F%2Fauth0.openai.com%2F

删除完成以后点击Log in按钮,此时查看网络抓包数据如下所示:

我们观察到请求的内容有这些:csrf, auth0?prompt=login, authorize?client_id=..., identifier?state=hKF...,至此我们准备工作已经完毕。
2.获取csrfToken
我们就按顺序看一下,首先是csrf,这时候肯定有人问为什么不看providers?哈,因为它没什么用。

观察发现里面就是GET请求,但是这时候我点击预览却看不到数据,于是我就去ApiFox上测了一下这个接口,发现请求到的是个csrfToken,如下图:

好家伙,你小子深藏不露,浏览器抓包都看不见你,给我逮到了!
3.获取authorize_url
在上一步中我们拿到了csrfToken,那么他有什么用呢?这时候我们该看下一个了auth0?prompt=login,点击这个请求,我们可以看到如下图所示:
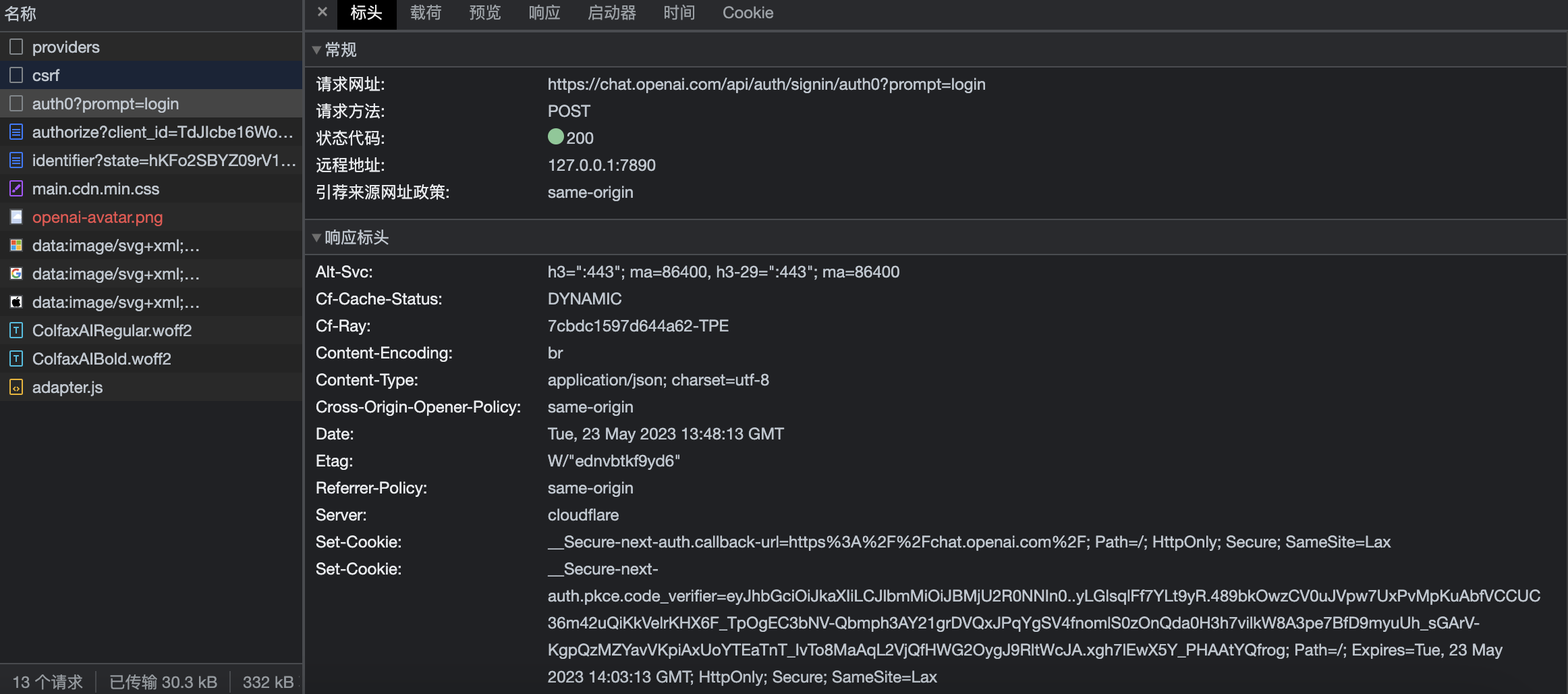
注意,这里是POST方法了,我们查看载荷,发现它带着如下参数:

惊喜这不就来了?大大的csrfToken在这摆着,懂了吧?这时候我点预览想查看响应数据,好家伙,又是无法加载响应数据,于是我只好去ApiFox里请求,但是我发现返回的是一大串html,嘶,怎么回事?经过我的比对,headers都一样了还是请求不到,于是我抱着试一试的心态用python来请求,打印结果惊喜的发现,有返回值,还是个url!

此时我们可以对比一下抓包抓到的url,发现这个url就是authorize那一大串那个,nice!又近了一步。
4.获取identify_url
有了上一步得到的authorize那个url,我们在抓包工具点击查看他的内容如下图:
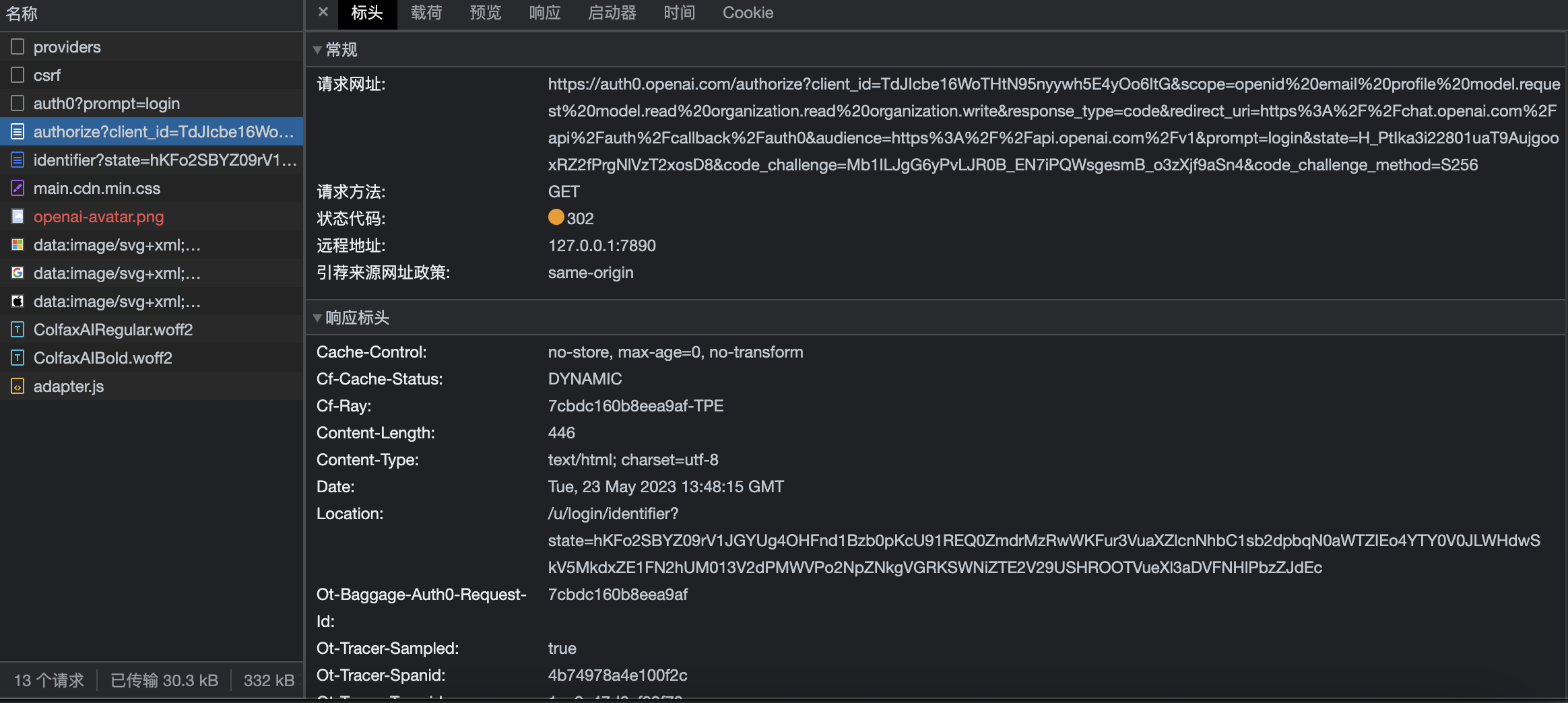
可以看到,他的状态代码是302,这是什么意思呢?302状态码代表了重定向,可以看到响应标头里面有个键的名称叫Location:,后面那个值就是重定向所指向的url。我们看左侧的列表名称里面,发现authorize下面就有个identifier,对比一下发现,这就是重定向后的链接,所以这一步我们需要拿到的就是响应头里面的Location的值。在python中实现后经过拼接url可以得到如图所示:

到这里为止,我们已经完成了一半的工作量噢~惊不惊喜?
5.获取password_url
上一步我们得到了identifier_url,此时页面的内容如图所示
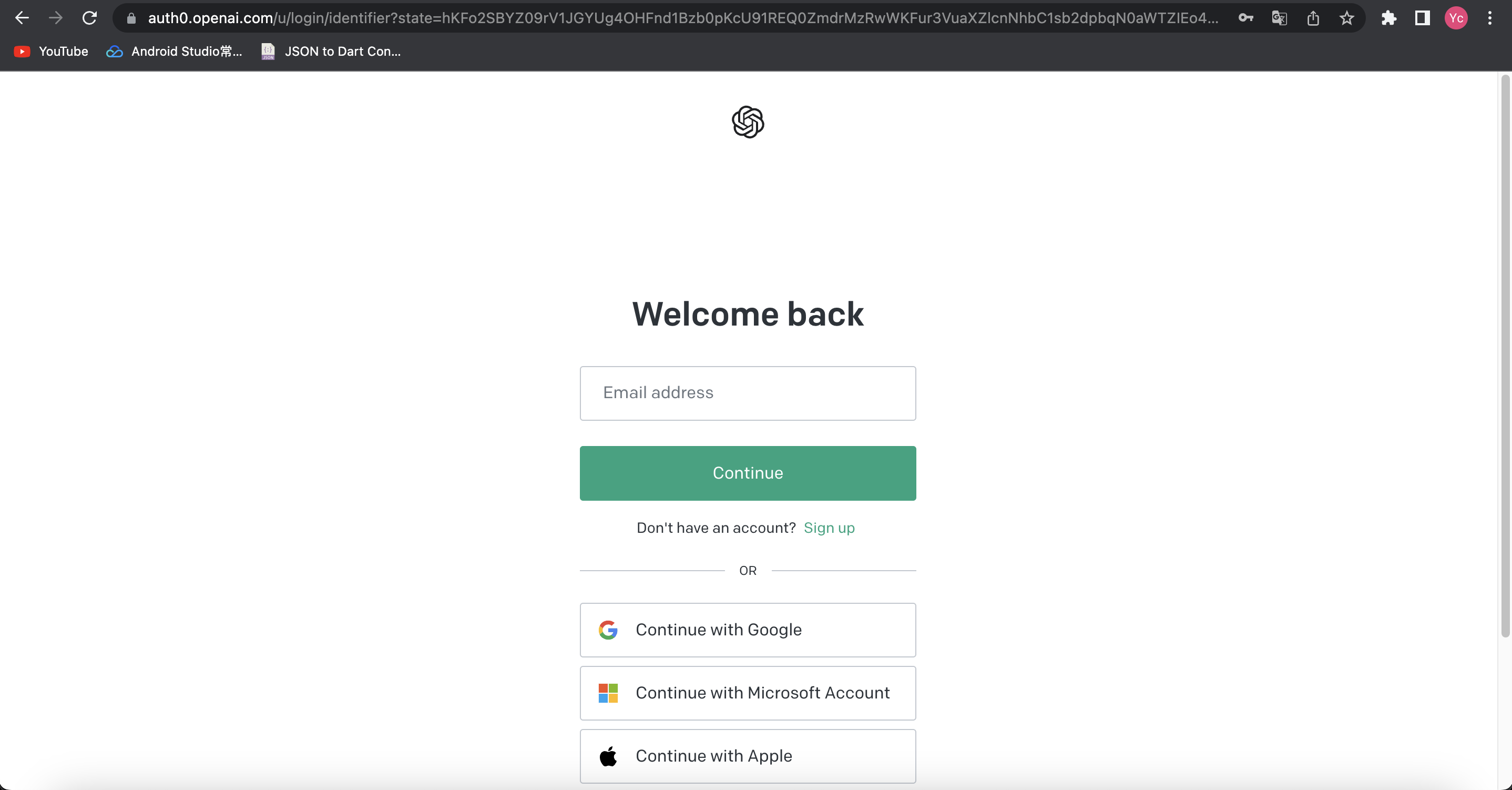
此时我们输入自己账号,点击continue,与此同时查看抓包内容,如下图所示:

可以发现这个identifier(我们刚刚拿到的链接)进行了302重定向!我查看载荷发现,他带上了如下的参数:

我们发现这个链接带上了自己url后面那一大串state参数,还有我们输入的username,以及其他的参数(我也不知道有什么用,不用管照着填就行)。参数看完了,那看看响应头吧。此时可以看到,响应头里有个Location参数,后面那一串就是重定向后的url,可以发现这就是下面的password那一串url的地址,讲到这,你有没有觉得这就像是个套娃哈哈哈,一层接一层的慢慢来。同样的使用python代码我成功提取到了他的password那一串url。
6.获取resume_url
我们首先登录一下自己的chatGPT账号,经过抓包可以看到如下列表:
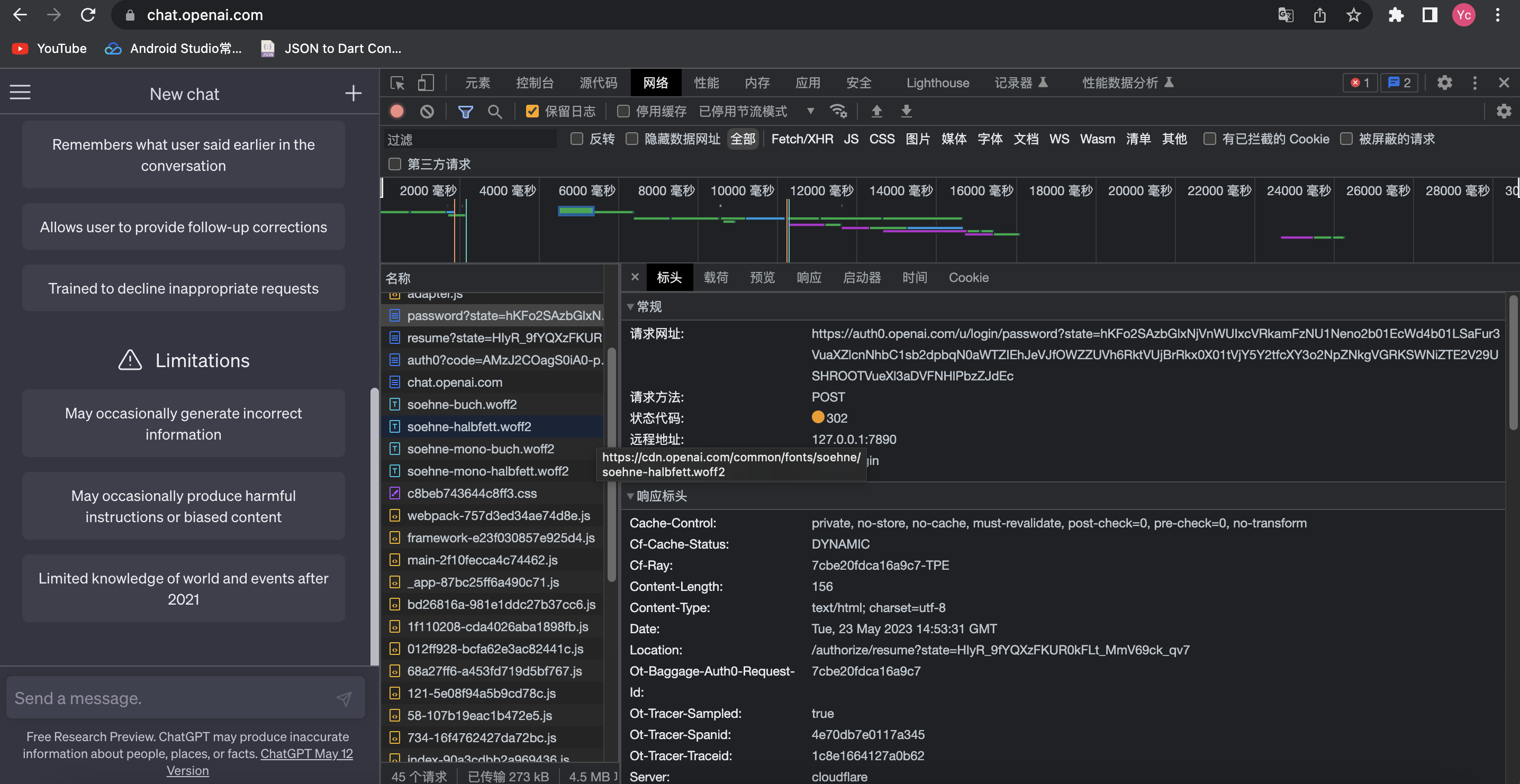
好家伙这password还是个重定向,同样发现重定向后的链接就是resume那一串,所以我们可以类比上面identifier的方式照做,获取到resume到那一串url。
7.获取auth0_url
我们点击resume那个url可以看到如下图所示:

他重定向后的链接就是他下方的auth0链接,chatGPT你可真行啊,没完没了的套娃!同理我们继续拿到auth0的链接。
8.获取chat_openai_url
继续往下推导,我们同样可以请求到chat.openai.com这个url。至此,我们已经清楚了从登录开始到进入页面的整个流程,这时候大家应该比较疑惑,最后拿到个html有啥用啊?我token呢?别急,好戏马上来。
接口跳转揭密
阅读下方内容前请先把你的cookie给清了!!!如果刚刚你按照上面8步流程走了一遍,那么现在你就要删除cookie,准备工作中有介绍如何删除。
正式开始
我们回到一开始,仔细想想我是不是说要把cookie给清空了,是的没错!最关键的点就在这个cookie,回到login这个url这里,查看此时的cookie我们可以发现:

嘶,请求响应中附带有cookie,我们在查看标头内容可以看到有set-cookie的键名称,而那个就是图上所显示的响应Cookie,当然这个看不出来什么,我们看下一个session这个附带的cookie,可以发现:

噢,这个请求的链接也有响应的cookie,有意思,那么我们往下继续看csrf附带的cookie,如图:

有意思!一层套一层,chatGPT你是懂套娃的。我们继续往下一一排查,如下:
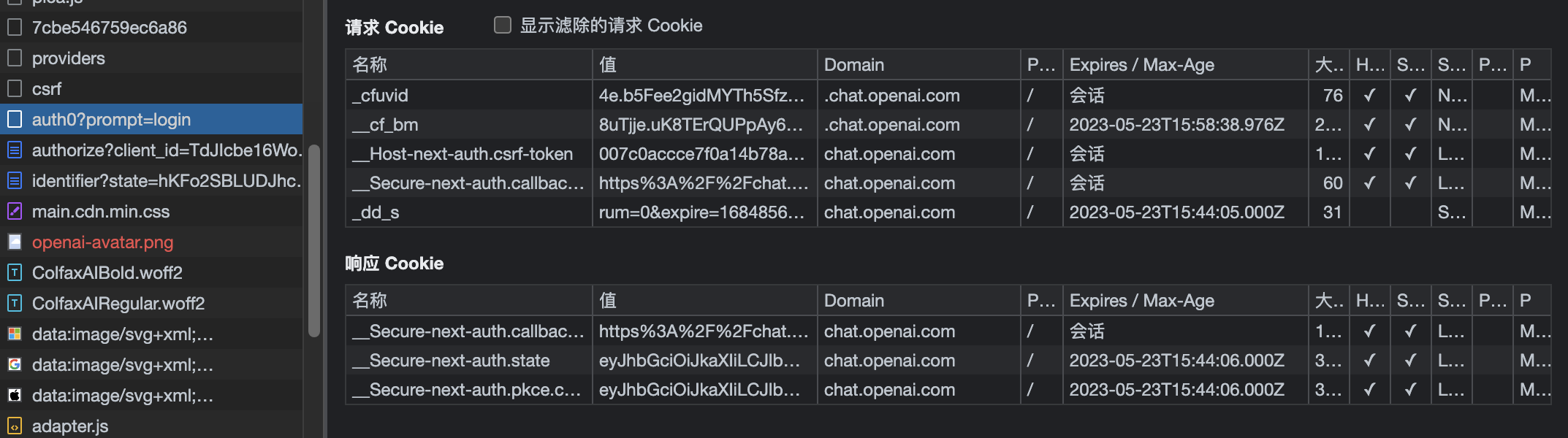

在这会发现,这次没带cookie,但是得到响应的cookie,继续往下看:

在这会发现,嘶怎么请求cookie只有这几个,那之前的cookie比如_dd_s,_cfuvid等等那些之前响应得到的cookie去哪里了?你可以理解为cookie有个列表,类似于map一样,键值对,请求的时候只需要拿我需要用的那几个就可以了。


在这发现,__cf_bm已经有了,那响应得到的这个__cf_bm在哪?没错,直接替换了原来的内容,讲到这里你有没有恍然大悟?下面我把所有的流程全部放出来,大家可以自行比对一下每一步的cookie。


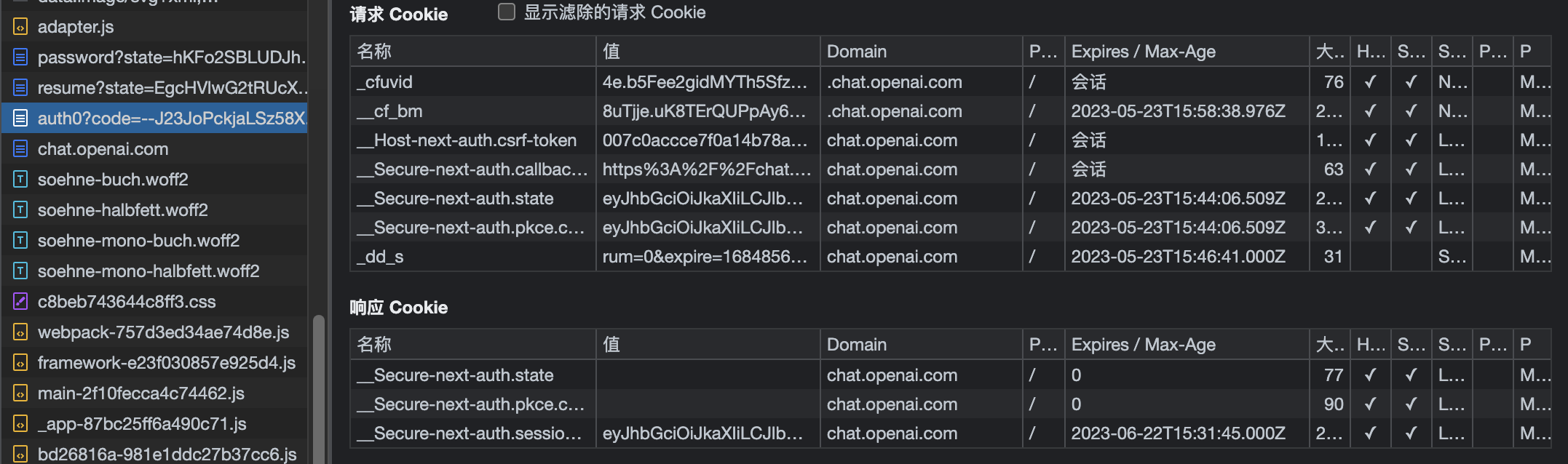

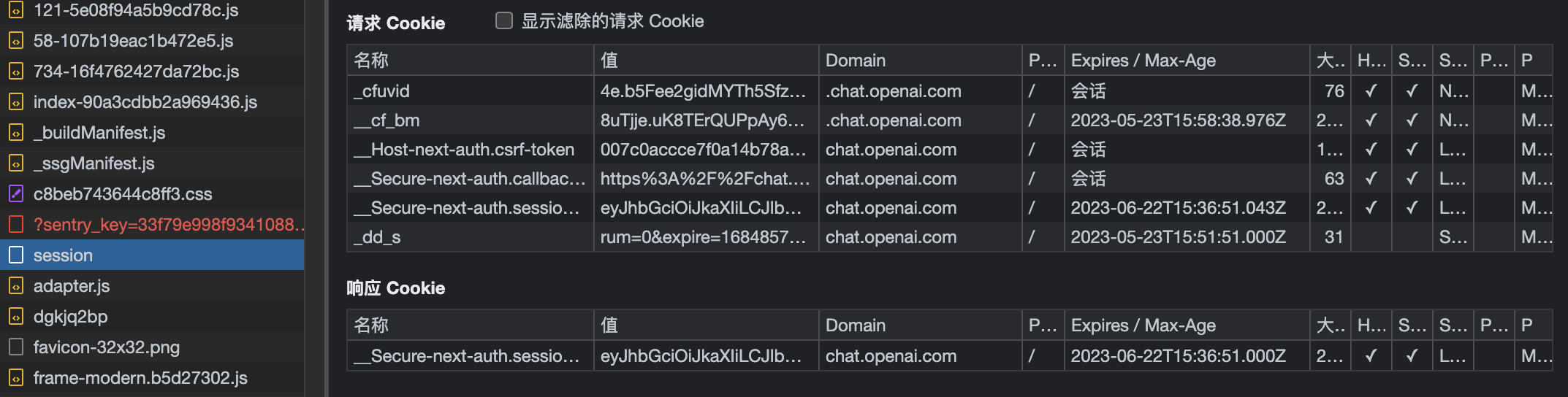
到这为止,就是所有的流程,这时候我们最关心的token就来了,点击session的响应数据我们看到如下:
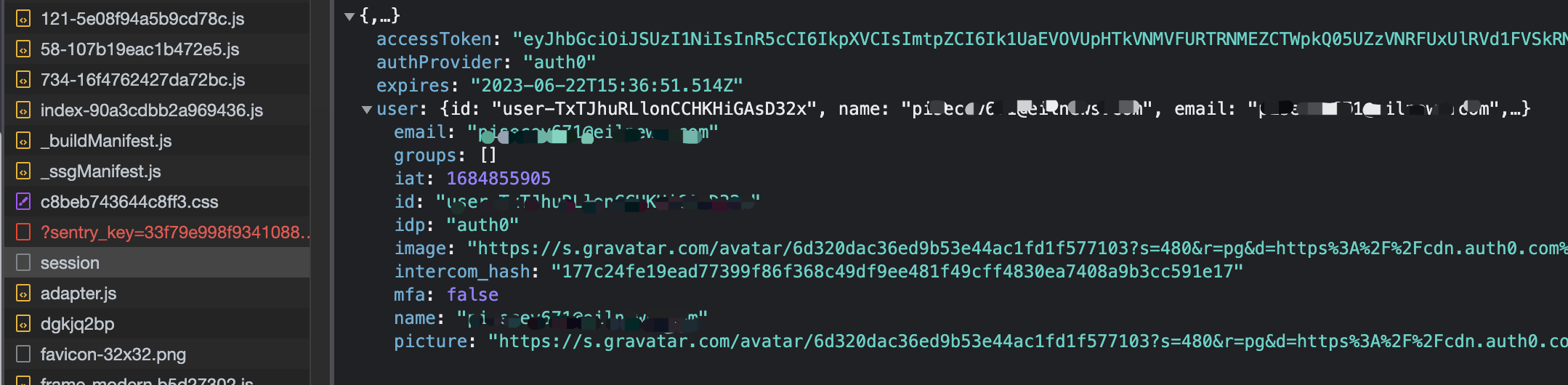
woc!token来了,经历这么多步的来回跳转,我们终于找到了token。想必大家已经熟悉了整个登录到获取token的过程了吧,简单来讲,我们每一步跳转,都需要携带必要的参数和请求头,请求头里最关键的就是cookie了,每次请求都影响下一步的cookie,所以我们一步步的分析查看,搞清楚整个流程,思路这里已经解答完毕,接下来上代码。
代码分析
在上面的揭密中我们提到了cookie,我们可以模拟一下浏览器,新建一个cookie_list来存储所有的cookie,这时我们实现一个函数可以新增并且更新cookie_list的内容,代码如下:
# 存储cookie,可以新增并且更新,这里的cookies指的是请求后的响应头里的cookie def add_or_update_cookie_list(cookies, cookie_list):# new_cookie即将cookie_list中所有的cookie转化成请求携带的cookie字符串格式new_cookie = ""if cookies != "":for name, value in cookies.items():cookie_list[name] = valuefor key, value in cookie_list.items():# cookie的格式就是name=value;name=value...new_cookie = new_cookie + key + "=" + value + ";"return new_cookie
按照顺序来,我们首先请求csrf_token,本来就是个get请求没什么难度,于是我用request库进行请求,但是死活403,我百思不得其解,用浏览器还有ApiFox请求都成功,后来经过查资料发现,这大概率是因为“原生模拟浏览器 TLS/JA3 指纹的验证”问题,于是我找到了解决办法:
使用curl_cffi库解决
pip install curl_cffi
from curl_cffi import requests url = "xxx" ... ... res = requests.get(url=url, impersonate="chrome101", headers=headers) print(res.text)
使用这个库以后成功解决!我们继续看代码:
# 获取csrf_token
def csrf_token_get(cookie_list):try:csrf_url = "https://chat.openai.com/api/auth/csrf"res = requests.get(url=csrf_url, impersonate="chrome101")csrfToken = res.json()['csrfToken']if res.status_code == 200:# 打印日志,可以去掉loggerConfig.Log.log.info(f"获取csrfToken成功! {csrfToken}")# 将响应头的cookie还有cookie_list传入add_or_update_cookie_list中更新cookie_list内容csrf_cookies = add_or_update_cookie_list(res.cookies, cookie_list)# 保证cookie结尾没有";"csrf_cookies = csrf_cookies[:-1]return csrf_cookies, csrfTokenexcept:# 打印日志,可以去掉loggerConfig.Log.log.warning("Error: 请求失败!")
拿到csrfToken以后我们该获取authorize_url了,代码如下:
def auth_post(csrf_cookies, csrf_token, cookie_list):try:# 我们每次都把上一步得到的cookie传给下一个请求,即使cookie比实际上请求需要的cookie内容多一些也无妨auth0_url = f"https://chat.openai.com/api/auth/signin/auth0?prompt=login"headers = {"Origin": "https://chat.openai.com","Cookie": csrf_cookies,"Referer": "https://chat.openai.com/auth/login?sso","User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"}data = {"callbackUrl": "/","csrfToken": csrf_token,"json": "true"}res = requests.post(url=auth0_url, headers=headers, data=data, impersonate="chrome101")auth_cookie = res.cookies# 更新cookie_listadd_or_update_cookie_list(auth_cookie, cookie_list)# 请求成功if res.status_code == 200:print(res.text)login_url = res.json()['url']# 打印日志loggerConfig.Log.log.info(f"获取auth_url成功! {login_url}]")return login_urlelse:# 打印日志loggerConfig.Log.log.warning(f"Error: Response<{res.status_code}>")except:# 打印日志loggerConfig.Log.log.warning("Error: 请求失败!")
接下来是获取identifier_url,代码如下:
def login_indentify(url, cookie_list):try:headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36",}res = requests.get(url=url, headers=headers, allow_redirects=False, impersonate="chrome101")if res.status_code == 302:# 获取响应头cookie,并处理成请求头cookie的格式set_cookie_string = res.cookiesnew_cookie = add_or_update_cookie_list(set_cookie_string, cookie_list)new_cookie = new_cookie[:-1]
# 获取state参数值location = res.headers['location']state = location.split("state=")[1]
# identify请求地址,此地址用来验证账号identify_url = "https://auth0.openai.com" + res.headers['location']loggerConfig.Log.log.info(f"获取identify_url成功! {identify_url}")
return state, new_cookie, identify_urlelse:loggerConfig.Log.log.warning(f"Error: Response<{res.status_code}>")except:loggerConfig.Log.log.warning("Error: 请求失败!")
我们拿到了identifier_url以后该拿到password_url了,代码如下:
def username_identify(state, new_cookie, identify_url):try:# 这里的username换成你自己的就可以data = {"state": state,"username": "xxx","js-available": "true","webauthn-available": "true","is-brave": "false","webauthn-platform-available": "true","action": "default"}headers = {"Sec-Fetch-Site": "same-origin","Cookie": new_cookie,"Origin": "https://auth0.openai.com","Referer": identify_url,"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"}res = requests.post(url=identify_url, data=data, headers=headers, impersonate="chrome101",allow_redirects=False)if res.status_code == 302:password_url = "https://auth0.openai.com" + res.headers['location']loggerConfig.Log.log.info(f"获取password_url成功! {password_url}")return password_url, state, new_cookieelse:loggerConfig.Log.log.warning(f"Error: Response<{res.status_code}>")except:loggerConfig.Log.log.warning("Error: 请求失败!")
继续按照顺序来,获取resume_url,代码如下:
def password_identify(password_url, state, new_cookie, cookie_list):try:# 账号密码输入自己的就可以data = {"state": state,"username": "xxx","password": "xxx","action": "default"}headers = {"Sec-Fetch-Site": "same-origin","Cookie": new_cookie,"Origin": "https://auth0.openai.com","Referer": password_url,"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"}res = requests.post(url=password_url, headers=headers, data=data, impersonate="chrome101",allow_redirects=False)if res.status_code == 302:resume_url = "https://auth0.openai.com" + res.headers['location']loggerConfig.Log.log.info(f"获取resume_url成功! {resume_url}")password_set_cookie = res.cookiesnew_cookie = add_or_update_cookie_list(password_set_cookie, cookie_list)new_cookie = new_cookie[:-1]return resume_url, new_cookieelse:loggerConfig.Log.log.warning(f"Error: Response<{res.status_code}>")except:loggerConfig.Log.log.warning("Error: 请求失败!")
下一步要拿到auth0_url(代码里面我写的是callback_url),代码如下:
def resume_url_get(resume_url, new_cookie, cookie_list):try:headers = {"Cookie": new_cookie,"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"}res = requests.get(url=resume_url, headers=headers, impersonate="chrome101", allow_redirects=False)if res.status_code == 302:callback_url = res.headers['location']loggerConfig.Log.log.info(f"获取callback_url成功! {callback_url}")callback_url_set_cookie = res.cookiesadd_or_update_cookie_list(callback_url_set_cookie, cookie_list)new_cookie = new_cookie[:-1]return callback_url, new_cookieelse:loggerConfig.Log.log.warning(f"Error: Response<{res.status_code}>")except:loggerConfig.Log.log.warning("Error: 请求失败!")
然后我们拿chat_openai_url,(坚持住,马上结束了!)代码如下:
def callback_url_get(callback_url, new_cookie, cookie_list):try:headers = {"Cookie": new_cookie,"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"}res = requests.get(url=callback_url, headers=headers, impersonate="chrome101", allow_redirects=False)if res.status_code == 302:chat_openai_url = res.headers['location']loggerConfig.Log.log.info(f"获取chat_openai_url成功! {chat_openai_url}")chat_openai_cookies = res.cookiesadd_or_update_cookie_list(chat_openai_cookies, cookie_list)else:loggerConfig.Log.log.warning(f"Error: Response<{res.status_code}>")except:loggerConfig.Log.log.warning("Error: 请求失败!")
最后一步!拿token!代码如下:
def get_access_token(cookie_list):try:cookies = add_or_update_cookie_list("", cookie_list)cookies = cookies[:-1]headers = {"Cookie": cookies,"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"}session_url = "https://chat.openai.com/api/auth/session"res = requests.get(url=session_url, headers=headers, impersonate="chrome101")if res.status_code == 200:loggerConfig.Log.log.info("获取accessToken成功!")return res.json()['accessToken']else:loggerConfig.Log.log.warning(f"Error: Response<{res.status_code}>")except:loggerConfig.Log.log.warning("Error: 请求失败!")
至此,chatGPT的access_token就可以拿到了,哎真的是,openai真会玩套娃,跳来跳去的。
总结
心路历程
我当时在一步步的分析请求的时候可遭老罪了,一个个的对比查看,无数次的实验,看了无数遍的报错,403,但是出来数据的那一刻整个人都是无比兴奋的,而且由于科学上网的问题,经常要等好久的响应,也有很多的429,哎不过还是很高兴,毕竟努力得到的一定的成果!
经验总结
通过这次的逆向,我对爬虫的掌握又高了一个层次(针对我自己,我很菜),知道以后可以对着cookie来当突破口,包括了解到了模拟浏览器指纹验证这种以前根本不知道的反爬虫机制,收获满满!