大家好,我是技福的小咖老师。
ChatGPT 发布以来,蹿红的速度比马斯克设计的火箭还快。据报道,ChatGPT在开放试用的短短几天里,就吸引了超过 100 万互联网注册用户。ChatGPT如同是“搜索引擎+社交软件”的结合体,能够在实时互动的过程中获得问题的合理答案。
公众一直在玩ChatGPT,ChatGPT 实际是如何工作的呢?虽然其内部实现的细节尚未公布,但从最近的研究中,我们还是可以一窥其基本原理的。内容比较多我们分两次给大家讲解。
什么是ChatGPT ?
ChatGPT 是OpenAI的最新语言模型,是基于GPT-3.5(Generative Pre-trained Transformer 3.5)架构开发的对话AI模型。与许多大型语言模型类似,ChatGPT能够生成多种风格和不同目的的文本,但具有更高的精度、细节和连贯性。它代表了OpenAI大语言模型系列的下一代,它的设计重点是交互式对话。
OpenAI使用RLHF(Reinforcement Learning from Human Feedbac,人类反馈强化学习)技术对 ChatGPT 进行了训练,并且 使用监督学习和强化学习的组合来调优 ChatGPT。该方法在训练中使用了训练师的反馈,用以最小化有害、失真或是有偏见的内容输出。

大型语言模型中的能力与一致性
Capability vs Alignment in Large Language Models
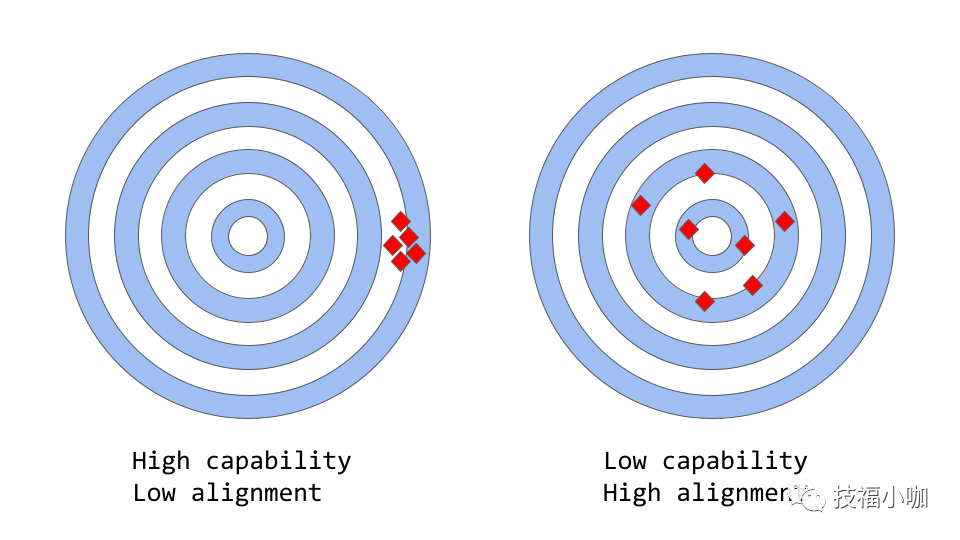
alignment vs capability" can be thought of as a more abstract analogue of "accuracy vs precision
在机器学习时,模型的能力是指模型执行特定任务或任务集的能力。模型的能力通常通过以下方式进行评估:如何优化其目标函数,定义模型目标的数学表达式。例如,用于预测股票价格的而设计的模型,可能有一个目标函数,用于衡量模型预测的准确性。如果模型能够准确预测股票价格随时间的变化,那么它将被视为具有较高的执行能力的模型。
一致性关注的是我们实际上希望模型做什么。它提出的问题是“目标函数是否符合我们的意图”,并且基于模型的目标和行为,在多大程度上与我们人类的价值观和和期望一致。举个简单的例子,假设我们要训练一个鸟类分类器,把鸟类分类为“麻雀”或“知更鸟”,并使用对数损失为训练目标,尽管我们的最终目标是很高的分类精度。该模型可能具有较低的对数损失,即模型的能力较强,但精度较差,这就是一个不一致的例子。模型可以优化培训目标,但与我们的最终目标不一致。

然而,在实际应用中,这些模型的目的是执行某种形式的有价值的认知工作,这些模型的训练方式与我们希望使用它们的方式之间存在着明显的分歧。尽管从数学上讲,机器计算的单词序列的统计分布可能是一种高效的选择,但实际上,我们会通过选择最适合给定情境的文本序列来生成语言,并使用我们的背景知识和常识来指导这一过程。当语言模型用于需要高度信任或可靠性的应用程序(如对话系统或智能个人助理)时,这可能会成为一个问题。
虽然在过去几年里,这些基于大量数据训练的模型变得极为复杂、强大,但当应用于实际人们生活生产时,它们往往无法发挥出潜力。大型语言模型中的一致性问题通常表现为:
缺乏有效帮助
-- 没有遵循用户的明确指示。
虚构幻象
-- 模型会虚构不存在或错误的事实。
缺乏可解读性
-- 人们很难理解模型是如何得出特定决策或预测结果的。
训练内容偏见有害
-- 经过有偏见、有害数据训练的语言模型,可能会在输出中重现这些数据,即使没有明确指示这样做。
但具体来说,一致性问题是从何处来的?它是语言模型的训练方式本身就容易产生不一致吗?
语言模型训练策略如何产生
How language model training strategies can produce misalignment
Next-token-prediction 和 masked-language-modeling 是用于训练语言模型的核心技术,例如:在第一种方法中,模型被赋予一系列单词(或“标记”,即部分单词)作为输入,并被要求预测序列中的下一个单词。假如给模型输入句子
"The cat sat on the"
它可能会预测下一个单词为「mat」、「chair」或「floor」,因为在前面的上下文中,这些单词出现的可能性很高;语言模型实际上能够预估输入内容前面的序列,每个可能使用的单词的可能性。

masked-language-modeling 方法是 Next-token-prediction 的变体,其中输入句子中的一些词被替换为特殊标记,例如 [MASK]。然后,模型被要求预测应该插入的正确单词。如果给模型一个句子:
“The [MASK] sat on the ”
它可能会预测下一个单词是「cat」、「dog」, 或 「rabbit」。
这些目标函数的一个优点是,它允许模型学习语言的统计结构,例如常见的单词序列和单词用法模式。这通常有助于模型生成更自然更流畅的文本,并且是每个语言模型预培训阶段的一个重要步骤。
然而这些目标函数也可能导致问题,主要是因为模型不能区分重要错误和不重要错误。举个简单的例子,如果给模型输入句子:
"The Roman Empire [MASK] with the reign of Augustus."
它可能会预测 MASK 位置应该填入「began」或「ended」,因为这两个词的出现的可能性在之前都是很高的。

一般来说,这些训练策略可能会导致语言模型在一些更复杂的任务时不一致,因为一个模型仅被训练用来预测文本序列中的下一个词,可能不一定能学习到其含义的更高级表达。因此,该模型很难推广到需要更深入理解的语言任务。
研究人员和开发人员正在研究各种方法,来解决大型语言模型中的一致性问题。ChatGPT 基于最初的 GPT-3 模型,开始使用了人类反馈来指导学习过程,对其进行进一步的训练,来解决模型的不一致问题。所使用的具体技术就是前面提到的 RLHF。ChatGPT 是第一个将此技术用于实际生活模型的第一个案例。
那么ChatGPT 是如何利用人类反馈来解决一致性问题的呢?咱们下期继续讲解
大家如果有想讨论的内容,欢迎留言!关注技福小咖,请帮忙点赞分享,您的支持是我们最大的动力!
参考内容:
How ChatGPT actually works