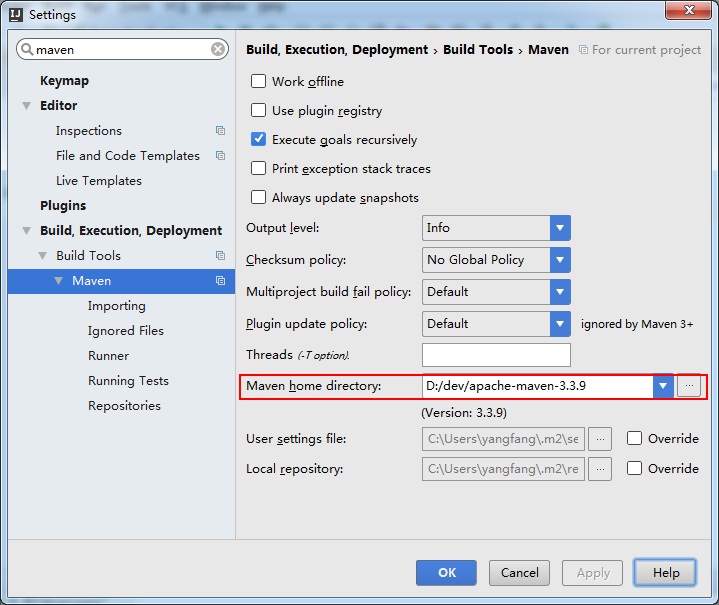
Policy Gradient Methods for Reinforcement Learning with Function Approximation(PG)
在强化学习的算法中存在两种算法,一个是基于价值函数的算法,另一个是基于策略梯度的算法。为什么要提出策略梯度算法呢?
- 基于策略的学习可能会具有更好的收敛性,这是因为基于策略的学习虽然每次只改善一点点,但总是朝着好的方向在改善;而在基于值函数的算法中,价值函数在后期会一直围绕最优价值函数持续小的震荡而不收敛。
- 在对于那些拥有高维度或连续状态空间来说,使用基于价值函数的学习在得到价值函数后,制定策略时,需要比较各种行为对应的价值大小。这样如果行为空间维度较高或者是连续的,则从中比较得出一个有最大价值函数的行为这个过程就比较难了,这时候使用基于策略的学习就高效的多。
- 基于价值函数的学习通常是学不到随机策略的,使用策略梯度算法可以直接输入转态,得到对应动作或者动作的概率分布。
在PG这篇论文中探讨了RL中函数逼近的另一种方法。我们不是近似一个值函数并用它来计算一个确定性策略,而是直接用一个独立的函数逼近器用它自己的参数来近似一个随机策略。例如,策略可以由一个神经网络来表示,该神经网络的输入是状态的表示,其输出是动作选择概率,其权值是策略参数。让![]() 作为策略参数的向量表示,
作为策略参数的向量表示,![]() 表示策略的最终表现。然后,在策略梯度方法中,策略参数的更新与梯度近似成比例。
表示策略的最终表现。然后,在策略梯度方法中,策略参数的更新与梯度近似成比例。
与价值函数方法不同,这里θ![]() 的微小变化只会导致策略和状态分布的微小变化。定义策略的目标函数存在两种,一种是平均报酬公式,另一种是从初始状态
的微小变化只会导致策略和状态分布的微小变化。定义策略的目标函数存在两种,一种是平均报酬公式,另一种是从初始状态![]() 获得的长期回报。
获得的长期回报。
- 平均报酬
![]()
![]()
- 长期报酬回报
![]()
对于上述两种目标函数,梯度均为
![]()
当我们使用函数逼近器fws,a![]() 来模拟Qπs,a
来模拟Qπs,a![]() 时,上式可以改写为:
时,上式可以改写为:
![]()
![]()
![]()
Deterministic Policy Gradient Algorithms(DPG)
策略梯度算法广泛应用于具有连续动作空间的强化学习问题。基本思想是代表策略参数概率分布![]() 。在某个状态下根据参数向量
。在某个状态下根据参数向量![]() 随机选择行动
随机选择行动![]() 。策略梯度算法通常是通过对这种随机策略进行抽样,并根据累积收益的增加来调整策略参数。
。策略梯度算法通常是通过对这种随机策略进行抽样,并根据累积收益的增加来调整策略参数。
在这篇文章中,考虑确定性策略为![]() 。从实际的角度来看,随机策略梯度与确定性策略梯度存在着重要的区别。在随机的情况下,策略梯度在状态空间和动作空间上积分,而在确定性的情况下,它只在状态空间上积分。因此,计算随机策略梯度可能需要更多的样本,特别是在行动空间有多个维度的情况下。为了学习确定性目标策略(利用确定性策略梯度的效率)。我们利用确定性策略梯度推导出一种离线行为批评算法,该算法使用可微分函数逼近器估计行为价值函数,然后在近似行为价值梯度的方向上更新策略参数。
。从实际的角度来看,随机策略梯度与确定性策略梯度存在着重要的区别。在随机的情况下,策略梯度在状态空间和动作空间上积分,而在确定性的情况下,它只在状态空间上积分。因此,计算随机策略梯度可能需要更多的样本,特别是在行动空间有多个维度的情况下。为了学习确定性目标策略(利用确定性策略梯度的效率)。我们利用确定性策略梯度推导出一种离线行为批评算法,该算法使用可微分函数逼近器估计行为价值函数,然后在近似行为价值梯度的方向上更新策略参数。
- Stochastic Policy Gradient 理论
评价表现目标方程为:
![]()
![]()
根据策略梯度理论(PG),最基本的策略梯度计算方程为如下
![]()
![]()
利用这个方程,可以通过策略梯度来调整参数![]() 来以优化最终的表现。但是问题在于还需要估计
来以优化最终的表现。但是问题在于还需要估计![]() 的值。
的值。
- Stochastic Actor-Critic 算法
Actor-Critic是基于策略理论的常用框架。Actor会通过计算上述方程来调整策略函数πθs![]() 的参数θ
的参数θ![]() 。由于真实的动作价值函数
。由于真实的动作价值函数 ![]() 是未知的,我们使用一个参数化的函数近似器
是未知的,我们使用一个参数化的函数近似器![]() 来代替,并且让Critic使用策略评估算法来估量它。
来代替,并且让Critic使用策略评估算法来估量它。
由于是 ![]() 是近似,使用它会造成与真实值
是近似,使用它会造成与真实值![]() 的偏差。为了消除偏差,
的偏差。为了消除偏差,![]() 应满足两个条件:
应满足两个条件:
![]()
参数w![]() 应该最小化均方误差
应该最小化均方误差
![]()
- Deterministic Policy Gradient理论
对于确定性策略![]() ,定义概率分布
,定义概率分布![]() 以及目标方程:
以及目标方程:
![]()
![]()
那么确定性策略梯度可以推导出如下:
![]()
![]()
- On-Policy Deterministic Actor-Critic
和随机化策略Actor-Critic一样,确定性策略也包含两部分,Critic估计行为价值函数,Actor估计行为价值函数的梯度。Actor根据上面的方程调整![]() 的参数
的参数![]() ,并且用
,并且用![]() 来逼近真实值。例如,Critic使用Sarsa更新来评估动作价值函数:
来逼近真实值。例如,Critic使用Sarsa更新来评估动作价值函数:
![]()
![]()
![]()
- Off-Policy Actor-Critic
我们称已探索过的轨迹为已知策略![]() ,未探索过的为目标策略
,未探索过的为目标策略![]() 。在off-policy中表现目标方程定义为:目标策略的状态价值函数在已知策略上的状态分布上取平均:
。在off-policy中表现目标方程定义为:目标策略的状态价值函数在已知策略上的状态分布上取平均:
![]()
![]()
对其进行微分即得到off-policy策略梯度:
∇θJβπθ≈S A ρβs∇θπθa|sQπs,adads
![]()
![]()
这个近似式去掉了一个依赖动作价值梯度的项![]() 。
。
- Off-Policy Deterministic Actor-Critic
现在要用off-policy的方法去让智能体通过随机已知策略![]() 生成的轨迹学习确定目标策略
生成的轨迹学习确定目标策略![]() 。
。
定义目标方程以及策略梯度:
![]()
![]()
![]()
同样确定性策略梯度中也丢弃了依赖于动作价值梯度的项:![]() 。
。
这里,用一个可微的动作价值函数![]() 来代替真实的动作价值函数
来代替真实的动作价值函数![]() ,需要同时满足两个条件:
,需要同时满足两个条件:
![]()
![]()
![]()
![]()
并且让Critic通过已知策略生成的轨迹来评估它。比如使用Q-learning:
![]()
![]()
![]()
Asynchronous Methods for Deep Reinforcement Learning(A3C)
深度强化学习最近被人发现貌似不太稳定,有人提出很多改善的方法,这些方法有很多共同的地方:一个online的agent碰到的观察到的数据序列是非静态的,然后就是,online的RL更新是强烈相关的。通过将agent的数据存储在一个 experience replay 单元中,数据可以从不同的时间步骤上,批处理或者随机采样。这种方法可以降低不平稳性,然后去掉了更新的相关性,但是与此同时,也限制了该方法只能是 off-policy 的 RL 算法。
Experience replay 有如下两个缺点:
1. 每一次交互都会耗费更多的内存和计算;
2. 需要 off-policy 的学习算法从更老的策略中产生的数据上进行更新。
本文中我们提出了一种很不同的流程来做 DRL。不用 experience replay,而是以异步的方式,并行执行多个 agent,在环境中的多个示例当中。这种平行结构可以将 agent的数据“去相关(decorrelates)”到一个更加静态的过程当中去,因为任何给定的时间步骤,并行的agent都会经历不同的状态。这个简单的想法确保了一个更大的范围,基础的 on-policy RL 算法,如:Sarsa,n-step methods,以及 actor-critic 方法,以及 off-policy 算法,如:Q-learning,利用CNN可以更加鲁棒和有效的进行应用。
本文的并行RL结构也提供了一些实际的好处,前人的方法都是基于特定的硬件,如GPUs或者大量分布式结构,本文的算法可以在单机上用多核 CPU 来执行。取得了比 之前基于 GPU 的算法 更好的效果,(A3C)算法的效果更优秀。
one-step Q-learning 是朝着one-step返回![]() 的方向去更新动作值函数
的方向去更新动作值函数![]() 。但是利用one-step方法的缺陷在于:得到一个奖励r
。但是利用one-step方法的缺陷在于:得到一个奖励r![]() 仅仅直接影响了 得到该奖励的状态动作对
仅仅直接影响了 得到该奖励的状态动作对![]() 的值。其他状态动作对的值仅仅间接的通过更新
的值。其他状态动作对的值仅仅间接的通过更新![]() 来影响。这就使得学习过程缓慢,因为许多更新都需要传播一个奖赏值给相关进行的状态和动作。
来影响。这就使得学习过程缓慢,因为许多更新都需要传播一个奖赏值给相关进行的状态和动作。
一种快速的传播奖赏的方法是利用n-step returns。 在n-step Q-learning中,Qs,a![]() 是朝向 n-step return
是朝向 n-step return ![]() 进行更新。这样就使得一个奖赏
进行更新。这样就使得一个奖赏![]() 直接地影响了n个正在进行的状态动作对的值。这也使得给相关 状态动作对的奖赏传播更加有效。
直接地影响了n个正在进行的状态动作对的值。这也使得给相关 状态动作对的奖赏传播更加有效。
另外就是定义了“优势函数”,即:利用Q值减去状态值,定义为:
![]()
这种方法也可以看做是actor-critic结构,其中,策略π![]() 可以看做是actor,bt
可以看做是actor,bt![]() 是critic。
是critic。
我们在这里介绍A3C算法,其中维持一个策略![]() 以及一个估计值函数
以及一个估计值函数![]() 。就像我们的n步q学习的变体一样,我们的角色-批评家的变体也在前视图中起作用并使用相同的n步返回组合来更新策略和值函数。当迭代步数达到
。就像我们的n步q学习的变体一样,我们的角色-批评家的变体也在前视图中起作用并使用相同的n步返回组合来更新策略和值函数。当迭代步数达到![]() 或者到达终止状态时,更新策略和值函数。我们通常使用一个卷积神经网络有一个softmax输出策略
或者到达终止状态时,更新策略和值函数。我们通常使用一个卷积神经网络有一个softmax输出策略![]() 和一个线性输出的价值函数
和一个线性输出的价值函数![]() ,共享所有非输出层参数。
,共享所有非输出层参数。
下面简单介绍一下使用n步回报的A3C算法步骤:
(1) 假设全局和线程内部的策略模型参数向量分别为'![]() ;全局和线程内部的价值模型参数:
;全局和线程内部的价值模型参数:![]() ;设置全局变量
;设置全局变量![]() ;
;
(2) 初始化线程步数计数器![]() ;
;
(3)重新设置全局策略模型参数的梯度![]() ,设置全局价值模型参数梯度
,设置全局价值模型参数梯度![]() ;
;
(4) 同步全局和线程内部的策略模型参数![]() ,同步全局和线程内部的价值模型参数
,同步全局和线程内部的价值模型参数![]() ;
;
(5)设置![]() ,并获得初始状态
,并获得初始状态![]() ;
;
(6)在状态![]() 通过策略模型
通过策略模型![]() 选择动作
选择动作![]() ,并执行该动作;
,并执行该动作;
(7) 通过步骤(6)获得对应的奖赏值![]() ,并达到新的状态
,并达到新的状态![]() ;
;
(8) 更新参数![]() ,
,![]() :
: ![]() ;
;
(9) 判断![]() 是否为终止状态或者
是否为终止状态或者![]() ,如果满足上述条件跳转到步骤(6),否则跳出循环,执行步骤(10);
,如果满足上述条件跳转到步骤(6),否则跳出循环,执行步骤(10);
(10) 计算每一次采样的价值:
![]()
(11)设置变量![]() ;
;
(12)设置变量![]() ,如果i
,如果i![]() 不等于
不等于![]() ,进行下一步,否则跳转到步骤(17);
,进行下一步,否则跳转到步骤(17);
(13) 设置![]() ;
;
(14) 计算积累策略模型参数![]() 的梯度:
的梯度:![]() ;
;
(15) 计算积累价值模型参数![]() 的梯度
的梯度 ![]() ;
;
(16) 跳转到步骤(12);
(17) 对全局模型θ和![]() 进行异步更新:
进行异步更新:![]() ;
;
(19) 判断![]() 是否大于
是否大于![]() ,如果是则跳出循环,否则跳到步骤(3)。
,如果是则跳出循环,否则跳到步骤(3)。
Continuous Control With Deep Reinforcement Learning(DDPG)
虽然DQN算法目前在RL游戏领域表现良好,但是DQN在解决高维观测空间的问题时,只能处理离散的低维动作空间。许多有趣的任务,尤其是身体控制任务,有连续的(实值)和高维的行动空间。DQN不能直接应用于连续域,因为它依赖于找到使动作值函数最大化的动作,而在连续值情况下,每一步都需要迭代优化过程。
我们称之为深度DDPG (Deep DPG)的model-free方法可以为所有人学习竞争策略,我们的任务使用低维观测(例如笛卡尔坐标或关节角度)使用相同的超参数和网络结构。在许多情况下,我们还能够直接从像素中学习良好的策略,再次保持超参数和网络结构不变。
以往的实践证明,如果只使用单个”Q神经网络”的算法,学习过程很不稳定,因为Q网络的参数在频繁梯度更新的同时,又用于计算Q网络和策略网络的梯度。基于此,DDPG分别为策略网络、Q网络各创建两个神经网络拷贝,一个叫做online,一个叫做target:
![]()
![]()
在训练完一个mini-batch的数据之后,通过SGA/SGD算法更新online网络的参数,然后再通过soft update算法更新 target 网络的参数。soft update是一种running average的算法:
![]()
DDPG算法的步骤如下: