文章目录
- 常用的数据同步方案
- 数据库迁移场景
- 数据同步场景
- 应用代码中同步
- 定时任务同步
- 通过MQ实现同步
- 通过CDC实现实时同步
- CDC(change data capture,数据变更抓取)
- Canal
- 基于日志增量订阅&消费支持的业务
- 工作原理
- Mysql主备复制实现
- Canal架构
- Canal是怎么假装成是Mysql Slave的?
- Canal是怎么解析binlog的?
- Quick Start
- 准备
- 启动
- 变更分发
- 总结
常用的数据同步方案
Q:大家知道的数据库同步方案或者工具有哪些?
数据库迁移场景
以Mysql数据库迁移为例,数据库常用迁移方案有停机迁移和平滑迁移。
平滑迁移又分为双写和CDC(数据变更抓取)。
双写:即所有写入操作同时写入旧表和新表,这种方式可以完全控制应用代码如何写数据库,听上去简单明了。但它会引入复杂的分布式一致性问题:要保证新旧库中两张表数据一致,双写操作就必须在一个分布式事务中完成,而分布式事务的代价太高了。
CDC:通过数据源的事务日志抓取数据源变更解决数据同步问题
数据同步场景
微服务开发环境下,为了提高搜索效率,以及搜索的精准度,会大量使用Redis、MongoBD等NoSQL数据库,也会使用大量的Solr、Elasticsearch等全文检索服务。那么,这个时候,就会有一个问题需要我们来思考和解决:那就是数据同步的问题!如何将实时变化的数据库中的数据同步到Redis/MongoBD或者Solr/Elasticsearch中呢?
应用代码中同步
在增加、修改、删除之后,执行操作ES的逻辑代码。例如下面的代码片段。
public ResponseResult updateStatus(Long[] ids, String status){try{taskService.updateStatus(ids, status);if("status_success".equals(status)){List<Task> itemList = taskService.getTaskList(ids, status);//数据写入esesClient.importList(itemList);//数据写入redis
// redisTemplate.save(itemList);return new ResponseResult(true, "修改状态成功")}}catch(Exception e){return new ResponseResult(false, "修改状态失败");}
}
优点:
实施起来比较简单,简单服务里面常用的方式。
缺点:
代码耦合度高。
和业务逻辑同步执行,效率变低。
Q:这里有一个问题想和大家讨论一下,对于一个方法里既有数据库的操作又有同步调用http/rpc接口的方法,如何保证一致性?
比如下面这个场景:
一个售后工单的处理,首先需要经过【客诉系统】,然后需要转到【工单系统】生成一个工单,方法逻辑大概如下:
@Transactional
public void handleKeSU(Integer orderId) {//调用http接口插入工单httpClient.saveGongDan(orderId);//修改客诉单状态为【已转工单】updateKeSuStatus(orderId);
}
因为流程问题,客诉单状态修改和工单系统生成工单需要一致,即工单生成成功,则客诉单状态修改成功,工单生成失败,则客诉单修改失败。
解决方案:将http调用放到本地数据库修改后面,依据事物回滚。
这样还有什么问题?当http调用响应时间超时,其实调用方工单已经生成成功,但是本地调用响应超时抛出异常导致回滚。
定时任务同步
在数据库中执行完增加、修改、删除操作后,通过定时任务定时的将数据库的数据同步到ES索引库中。
定时任务技术有:SpringTask,Quartz,XXLJOB。
这里执行定时任务时,需要注意的一个技巧是:第一次执行定时任务时,从MySQL数据库中以时间字段进行倒序排列查询相应的数据,并记录当前查询数据的时间字段的最大值,以后每次执行定时任务查询数据的时候,只要按时间字段倒序查询数据表中的时间字段大于上次记录的时间值的数据,并且记录本次任务查询出的时间字段的最大值即可,从而不需要再次查询数据表中的所有数据。
注意:这里所说的时间字段指的是标识数据更新的时间字段,也就是说,使用定时任务同步数据时,为了避免每次执行任务都会进行全表扫描,最好是在数据表中增加一个更新记录的时间字段。
优点:
同步ES索引库的操作与业务代码完全解耦。
缺点:
数据的实时性并不高。
通过MQ实现同步
在数据库中执行完增加、修改、删除操作后,向MQ中发送一条消息,此时,同步程序作为MQ中的消费者,从消息队列中获取消息,然后执行同步Solr索引库的逻辑。
我们可以使用下图来简单的标识通过MQ实现数据同步的过程。
我们可以使用如下代码实现这个过程。
public ResponseResult updateStatus(Long[] ids, String status){try{goodsService.updateStatus(ids, status);if("status_success".equals(status)){List<TbItem> itemList = goodsService.getItemList(ids, status);final String jsonString = JSON.toJSONString(itemList);//发送消息jmsTemplate.send(queueSolr, new MessageCreator(){@Overridepublic Message createMessage(Session session) throws JMSException{return session.createTextMessage(jsonString);}});}return new ResponseResult(true, "修改状态成功");}catch(Exception e){return new ResponseResult(false, "修改状态失败");}
}
优点:
业务代码解耦,并且能够做到准实时。目前tk的ES同步用的就是这中方式吧
缺点:
需要在业务代码中加入发送消息到MQ的代码,数据调用接口耦合。
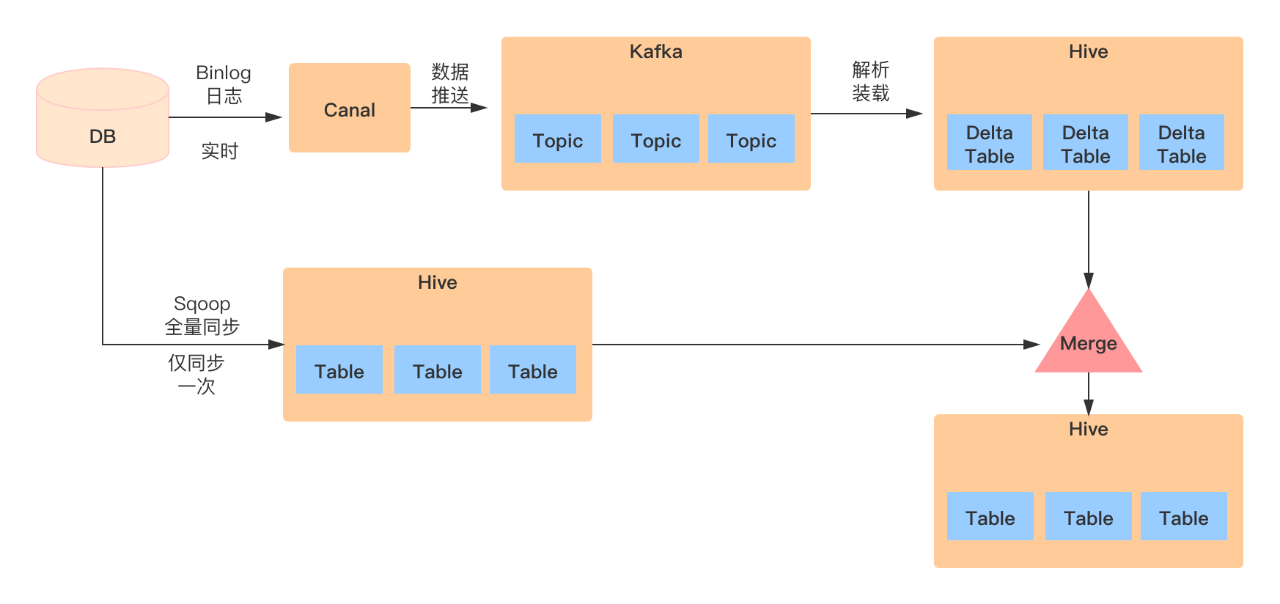
通过CDC实现实时同步
通过CDC来解析数据库的日志信息,来检测数据库中表结构和数据的变化,从而更新ES索引库。
使用CDC可以做到业务代码完全解耦,API完全解耦,可以做到准实时。
CDC(change data capture,数据变更抓取)
通过数据源的事务日志抓取数据源变更,这能解决一致性问题(只要下游能保证变更应用到新库上)。它的问题在于各种数据源的变更抓取没有统一的协议,如
MySQL 用 Binlog,PostgreSQL 用 Logical decoding 机制,MongoDB 里则是 oplog。
-
Canal,阿里开源的基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了mysql。
-
Databus,Linkedin 的分布式数据变更抓取系统。
它的 MySQL 变更抓取模块很不成熟,官方支持的是 Oracle,MySQL 只是使用另一个开源组件 OpenReplicator 做了一个 demo。另一个不利因素 databus 使用了自己实现的一个 Relay 作为变更分发平台,相比于使用开源消息队列的方案,这对维护和外部集成都不友好。 -
Mysql-Streamer,Yelp 的基于python的数据管道。
-
Debezium,Redhat 开源的数据变更抓取组件。
支持 MySQL、MongoDB、PostgreSQL 三种数据源的变更抓取。Snapshot Mode 可以将表中的现有数据全部导入 Kafka,并且全量数据与增量数据形式一致,可以统一处理,很适合数据库迁移;
Canal
canal [kə’næl],译意为水道/管道/沟渠,纯Java开发,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费,
目前canal只能支持row模式的增量订阅(statement只有sql,没有数据,所以无法获取原始的变更日志)
基于日志增量订阅&消费支持的业务
数据库实时备份
多级索引 (卖家和买家各自分库索引)
业务cache刷新
价格变化等重要业务消息
工作原理

- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送 dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)
Mysql主备复制实现
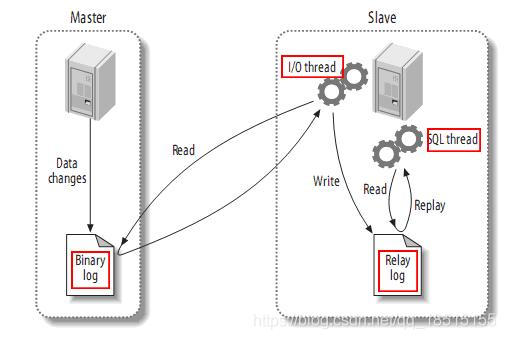
从上层来看,复制分成三步:
- master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events,可以通过show binlog events进行查看);
- slave将master的binary log events拷贝到它的中继日志(relay log);
- slave重做中继日志中的事件,将改变反映它自己的数据;
Canal架构

通过deployer模块,启动一个canal-server,一个cannal-server内部包含多个instance,每个instance都会伪装成一个mysql实例的slave。client与server之间的通信协议由protocol模块定义。client在订阅binlog信息时,需要传递一个destination参数,server会根据这个destination确定由哪一个instance为其提供服务。
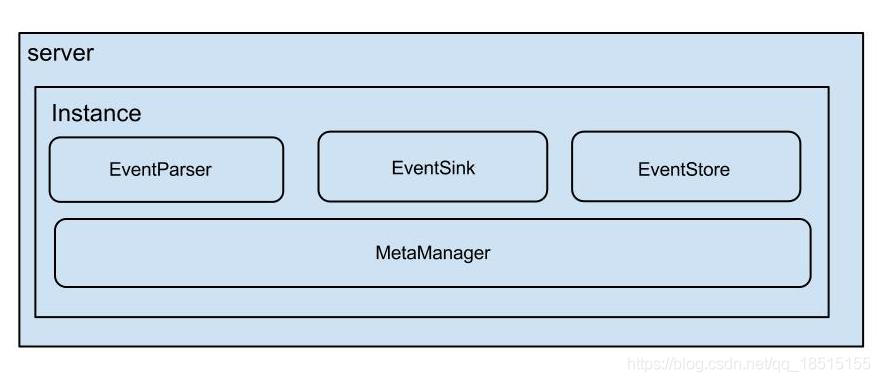
说明:
- server代表一个canal运行实例,对应于一个jvm
- instance对应于一个数据队列(1个server对应1…n个instance)
instance模块:
- eventParser (数据源接入,模拟slave协议和master进行交互,协议解析)
- eventSink (Parser和Store链接器,进行数据过滤,加工,分发的工作)
- eventStore (数据存储,目前只存在内存里)
- metaManager (增量订阅&消费信息管理器)
Canal是怎么假装成是Mysql Slave的?
- 与Mysql Master服务器建立Socket链接;
- 根据Mysql协议规范发送身份认证数据包进行身份认证;
- 根据Mysql协议规范发送slave注册数据包将自己伪装成Mysql Slave;
- 根据Mysql协议规范发送Dump请求,让Master给自己推送Binlog日志;
Canal是怎么解析binlog的?
Mysql Binlog介绍:http://dev.mysql.com/doc/refman/5.5/en/binary-log.html
一个binlog包含一个四字节的模数和一系列描述数据变更的Event,每一个Event又包含header和data两部分,大致结构如下:

基于Row模式的binlog主要包括以下几个Event:
目前canal只能支持row模式的增量订阅(statement只有sql,没有数据,所以无法获取原始的变更日志)
TABLE_MAP_EVENT:描述变更的数据库表
WRITE_ROWS_EVENT:描述插入数据变更
UPDATE_ROWS_EVENT:描述修改数据变更
DELETE_ROWS_EVENT:描述删除数据变更
根据Event的固定结构就可以解析出来相应的数据变更信息。
演示查看binlog:mysqlbinlog --no-defaults --base64-output=decode-rows -v ../data/binlog.000034 | more
Quick Start
准备
对于自建 MySQL , 需要先开启 Binlog 写入功能,配置 binlog-format 为 ROW 模式,my.cnf 中配置如下
[mysqld]
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复
授权 canal 链接 MySQL 账号具有作为 MySQL slave 的权限, 如果已有账户可直接 grant
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
FLUSH PRIVILEGES;
启动
下载 canal, 访问 release 页面 , 选择需要的包下载, 如以 1.1.4 版本为例
wget https://github.com/alibaba/canal/releases/download/canal-1.1.4/canal.deployer-1.1.4.tar.gz
解压缩
mkdir /tmp/canal
tar zxvf canal.deployer-$version.tar.gz -C /tmp/canal
解压完成后,进入 /tmp/canal 目录,可以看到如下结构
drwxr-xr-x 2 jianghang jianghang 136 2013-02-05 21:51 bin
drwxr-xr-x 4 jianghang jianghang 160 2013-02-05 21:51 conf
drwxr-xr-x 2 jianghang jianghang 1.3K 2013-02-05 21:51 lib
drwxr-xr-x 2 jianghang jianghang 48 2013-02-05 21:29 logs
配置修改
vi conf/example/instance.properties
##mysql serverId
canal.instance.mysql.slaveId = 1234
#position info,需要改成自己的数据库信息
canal.instance.master.address = 127.0.0.1:3306
canal.instance.master.journal.name =
canal.instance.master.position =
canal.instance.master.timestamp =
#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#username/password,需要改成自己的数据库信息
canal.instance.dbUsername = canal
canal.instance.dbPassword = canal
canal.instance.defaultDatabaseName =
canal.instance.connectionCharset = UTF-8
#table regex
canal.instance.filter.regex = .\*\\\\..\*
- canal.instance.connectionCharset 代表数据库的编码方式对应到 java 中的编码类型,比如 UTF-8,GBK , ISO-8859-1
- 如果系统是1个 cpu,需要将 canal.instance.parser.parallel 设置为 false
启动
sh bin/startup.sh
查看 server 日志
vi logs/canal/canal.log
2013-02-05 22:45:27.967 [main] INFO com.alibaba.otter.canal.deployer.CanalLauncher - ## start the canal server.
2013-02-05 22:45:28.113 [main] INFO com.alibaba.otter.canal.deployer.CanalController - ## start the canal server[10.1.29.120:11111]
2013-02-05 22:45:28.210 [main] INFO com.alibaba.otter.canal.deployer.CanalLauncher - ## the canal server is running now ......
查看 instance 的日志
vi logs/example/example.log
2013-02-05 22:50:45.636 [main] INFO c.a.o.c.i.spring.support.PropertyPlaceholderConfigurer - Loading properties file from class path resource [canal.properties]
2013-02-05 22:50:45.641 [main] INFO c.a.o.c.i.spring.support.PropertyPlaceholderConfigurer - Loading properties file from class path resource [example/instance.properties]
2013-02-05 22:50:45.803 [main] INFO c.a.otter.canal.instance.spring.CanalInstanceWithSpring - start CannalInstance for 1-example
2013-02-05 22:50:45.810 [main] INFO c.a.otter.canal.instance.spring.CanalInstanceWithSpring - start successful....
修改表数据,查看抓取到的日志
关闭
sh bin/stop.sh
变更分发
抓取到数据变更之后,需要考虑怎么将这些变更分发出去。
再来回顾一下Canal基本架构。
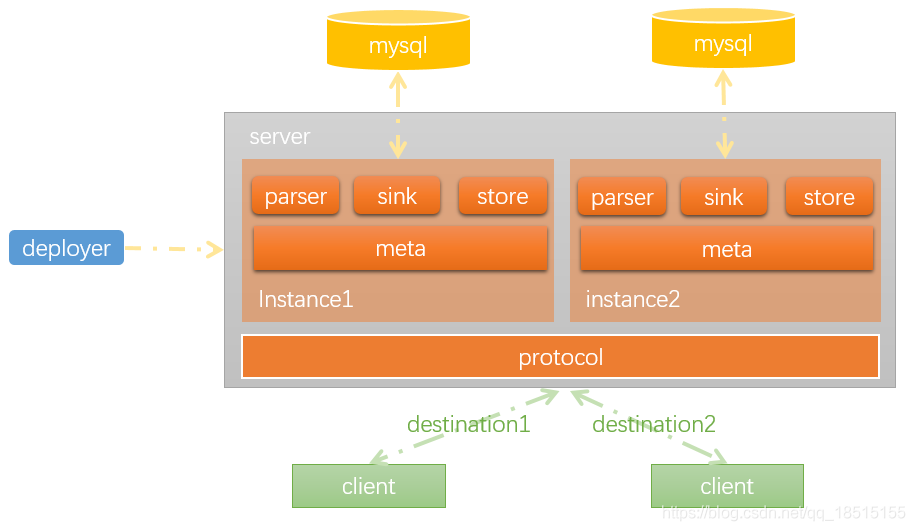
从上图可以看到Canal是Server-Client模式。
Server,主要是解析、分发、存储binlog;
Client,通过ClientAPI你可以从Server获取变更数据;
ClientAdapter,扩展Client的功能,包括将数据同步到RDB,ES,HBASE;
但其实这种Client模式并没有达到真正的解耦,更关键的是目前只有Java语言的Client,为了解决这个问题,大家自然而然想到消息中间件。
事实上,Canal 1.1.1版本以后也是支持在Canal Server解析binlog以后直接将数据投递到Kafka/RocketMQ。
于是就有了下面的同步方案:

总结
本文主要讨论数据同步方案,并对canal做了简单介绍。同时也对binlog的解析和mysql协议简单介绍希望能了解这种CDC的基本原理。