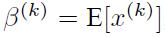今天我们将尝试了解如何使我们的模型在推理上更快一点。
使用 Batch Normalization 作为提高泛化能力的一种方式浪费了大量的网络。 但是在推理过程中,批量归一化被关闭,而是使用近似的每个通道均值和方差。 很酷的是,我们可以通过 1x1 卷积实现相同的行为。 更好的是将Batch Normalization 与前面的卷积合并。
Batch Normalization
假设 x x x 是要归一化的激活信号。 给定一组来自一个batch中不同样本的此类信号 x 1 , x 2 , . . . , x n x_1,x_2,...,x_n x1,x2,...,xn,归一化如下:
x ^ i = γ x i − μ σ 2 + ϵ + β = γ x i σ 2 + ϵ + β − γ μ σ 2 + ϵ \hat x_i = \gamma \frac{x_i-\mu}{\sqrt{\sigma^2+\epsilon} }+\beta= \frac{\gamma x_i}{\sqrt{\sigma^2+\epsilon}} +\beta- \frac{\gamma \mu}{\sqrt{\sigma^2+\epsilon}} x^i=γσ2+ϵxi−μ+β=σ2+ϵγxi+β−σ2+ϵγμ
这里 μ \mu μ 和 σ 2 \sigma^2 σ2 为这个batch上计算得到的均值和方差(在B,H,W维度上计算,每个channel单独计算),而 ϵ \epsilon ϵ 是防止除零所设置的一个极小值, γ \gamma γ 是比例参数,而 β \beta β 是平移系数。在训练过程中, μ \mu μ 和 σ \sigma σ 在当前batch上计算:
μ = 1 n ∑ x i σ 2 = 1 n ∑ ( x i − μ ) 2 \mu = \frac{1}{n} \sum x_i \\ \sigma^2=\frac{1}{n}\sum(x_i-\mu)^2 μ=n1∑xiσ2=n1∑(xi−μ)2
参数 γ \gamma γ 和 β \beta β 与网络的其他参数一起通过梯度下降缓慢学习。 在测试期间,通常不会在一个batch图像上运行网络。 因此,不能使用前面提到的 μ \mu μ 和 σ \sigma σ 公式。 相反,我们使用他们在训练期间通过exponential moving average计算的估计值 μ ^ \hat \mu μ^ 和 σ ^ 2 \hat \sigma^2 σ^2
如今,批量归一化主要用于卷积神经网络中。 在此设置中,输入特征图的每个通道 c c c 都有均值 μ c \mu_c μc 和方差估计 σ c 2 \sigma_c^2 σc2 、平移 β c \beta_c βc 和比例参数 γ c \gamma_c γc
融合方案
对于一个形状为 C × H × W C \times H \times W C×H×W的特征图 F F F,记归一化结果 F ^ \hat F F^,计算如下:

上式为 f ( x ) = W x + b f(x)=Wx+b f(x)=Wx+b的形式,可以看成 1 × 1 1 \times 1 1×1卷积,由于BN层常常在Conv层之后,可以将两操作合并。
融合BN和卷积
- w B N ∈ R C × C \mathbf w_{BN} \in \mathbb R^{C \times C} wBN∈RC×C 和 b B N ∈ R C \mathbf b_{BN} \in \mathbb R^{C } bBN∈RC 是
BN的参数 - w c o n v ∈ R C × C p r e . k 2 \mathbf w_{conv} \in \mathbb R^{C \times C_{pre}.k^2} wconv∈RC×Cpre.k2和 b c o n v ∈ R C \mathbf b_{conv} \in \mathbb R^C bconv∈RC是
Conv层的参数 - F p r e v F_{prev} Fprev是卷积的输入
- C p r e v C_{prev} Cprev:输入层的通道数量
- k k k:卷积核大小
将 F p r e v F_{prev} Fprev的每个 k × k k \times k k×k部分reshape为一个维度为 k 2 . C p r e v k^2.C_{prev} k2.Cprev 的向量 f i , j f_{i,j} fi,j,因此Conv层加BN层的操作为:
f ^ i , j = W B N . ( W c o n v . f i , j + b c o n v ) + b B N \hat {\mathbf f}_{i,j}=\mathbf W_{BN} . (\mathbf W_{conv}.\mathbf f_{i,j}+\mathbf b_{conv})+\mathbf b_{BN} f^i,j=WBN.(Wconv.fi,j+bconv)+bBN
因此,我们可以用具有以下参数的单个卷积层替换这两层:
- 滤波器权重 W W W: W = W B N . W c o n v \mathbf W=\mathbf W_{BN}. \mathbf W_{conv} W=WBN.Wconv
- 偏置bias: b = W B N . b c o n v + b B N \mathbf b=\mathbf W_{BN}. \mathbf b_{conv}+ \mathbf b_{BN} b=WBN.bconv+bBN
pytorch实现:
nn.Conv2d参数:
- 滤波器权重, W \mathbf W W:
conv.weight - bias, b \mathbf b b:
conv.bias
nn.BatchNorm2d参数:
- scaling, γ \gamma γ:
bn.weight
shift, β \beta β:bn.bias - mean estimate, μ ^ \hat \mu μ^:
bn.running_mean - variance estimate, σ 2 \sigma^2 σ2:
bn.running_var - ϵ \epsilon ϵ(for numerical stability)::
bn.eps
代码实现:
import torchimport torchvisiondef fuse(conv, bn):fused = torch.nn.Conv2d(conv.in_channels,conv.out_channels,kernel_size=conv.kernel_size,stride=conv.stride,padding=conv.padding,bias=True)# setting weightsw_conv = conv.weight.clone().view(conv.out_channels, -1)w_bn = torch.diag(bn.weight.div(torch.sqrt(bn.eps+bn.running_var)))fused.weight.copy_( torch.mm(w_bn, w_conv).view(fused.weight.size()) )# setting biasif conv.bias is not None:b_conv = conv.biaselse:b_conv = torch.zeros( conv.weight.size(0) )b_bn = bn.bias - bn.weight.mul(bn.running_mean).div(torch.sqrt(bn.running_var + bn.eps))fused.bias.copy_( b_conv + b_bn )return fused# Testing# we need to turn off gradient calculation because we didn't write ittorch.set_grad_enabled(False)x = torch.randn(16, 3, 256, 256)resnet18 = torchvision.models.resnet18(pretrained=True)# removing all learning variables, etcresnet18.eval()model = torch.nn.Sequential(resnet18.conv1,resnet18.bn1)f1 = model.forward(x)fused = fuse(model[0], model[1])f2 = fused.forward(x)d = (f1 - f2).mean().item()print("error:",d)
参考:https://learnml.today/speeding-up-model-with-fusing-batch-normalization-and-convolution-3