文章目录
- 前言
- 音频播放
- 举个例子:PortAudio
- 回调函数
- 解码与播放
- 优化策略
- 1. 一次性读取音频到内存中
- 2. MMAP
- 3. 音频转码,再接 MMAP
- 4. 解码缓冲
- 总结
- 参考资料
前言
延迟是指信号在系统中传输所需的时间。下面是常见类型的音频应用相关延迟时间:
-
音频输出延迟时间是指从应用生成音频样本到样本通过耳机插孔或内置扬声器播放之间经历的时间。
-
音频输入延迟时间是指设备音频输入装置(例如,麦克风)接收到音频信号到这些音频数据可供应用使用所经历的时间。
-
往返延迟时间是指输入延迟时间、应用处理时间和输出延迟时间的总和。
-
触摸延迟时间是指从用户触摸屏幕到应用接收到触摸事件之间经历的时间。
-
预热延迟时间是指数据第一次在缓冲区加入队列后启动音频管道所需的时间。
对于一些关键场景,具有较低延迟是非常重要的:
- 音乐创建
- 通信
- 虚拟现实
- 游戏
想象你正在玩一款模拟钢琴的游戏,当点击屏幕按钮时,它会发出对应琴键声音。这样的游戏必须运行在较低延迟的环境下,及时地给你声音的反馈,否则会大大降低游戏体验。低延迟就意味在音频线程的操作要快,要更快。
音频播放
本文想要讨论的是如何降低由于音频解码带来播放输出延迟,在这之前,让我们先大致了解系统 API 进行播放音频过程。
简单来说,主要就两部分:
- 音频线程。系统会启动音频线程,它负责将播放的数据传给硬件
- 回调函数。音频线程通过回调函数,获取需要播放的数据

其中音频线程不断地将空的 Buffer 送给回调函数,回调函数负责将 Buffer 填入数据,接着将 Buffer 送入系统进行播放。
举个例子:PortAudio
为了更容易的理解音频播放的过程,我们举一个实际的例子:利用 PortAudio进行音频播放。例子中所有代码在 low_latency_audio_decode 仓库。
PortAudio 是一个简洁的跨平台的音频 I/O 库,目前支持 Windows、Mac OSX、Linux(很遗憾,不支持 Android)。它使用回调机制来处理音频请求。
PortAudio 只需要两步就能进行音频播放:
- 编写回调函数,在回调函数中将需要播放的数据填入 Buffer 中
Pa_OpenStream打开音频流,并注册回调函数。
以 0_playback.cpp 为例,它播放一段正弦波。首先,我们需要设置一些播放参数:
PaStreamParameters outputParameters;Pa_Initialize();//
outputParameters.device = Pa_GetDefaultOutputDevice(); /* default output device */
outputParameters.channelCount = 2; /* stereo output */
outputParameters.sampleFormat = paFloat32; /* 32 bit floating point output */
outputParameters.suggestedLatency = Pa_GetDeviceInfo( outputParameters.device )->defaultLowOutputLatency;
outputParameters.hostApiSpecificStreamInfo = NULL;
接着,通过 Pa_OpenStream 打开音频流,并注册回调函数:
paTestData data;Pa_OpenStream(&stream,NULL, /* no input */&outputParameters,SAMPLE_RATE,FRAMES_PER_BUFFER,paClipOff, /* we won't output out of range samples so don't bother clipping them */patestCallback,&data);
其回调函数为:
static int patestCallback( const void *inputBuffer, void *outputBuffer,unsigned long framesPerBuffer,const PaStreamCallbackTimeInfo* timeInfo,PaStreamCallbackFlags statusFlags,void *userData )
{paTestData *data = (paTestData*)userData;float *out = (float*)outputBuffer;unsigned long i;for( i=0; i<framesPerBuffer; i++ ){*out++ = data->sine[data->left_phase]; /* left */*out++ = data->sine[data->right_phase]; /* right */data->left_phase += 1;if( data->left_phase >= TABLE_SIZE ) data->left_phase -= TABLE_SIZE;data->right_phase += 3; /* higher pitch so we can distinguish left and right. */if( data->right_phase >= TABLE_SIZE ) data->right_phase -= TABLE_SIZE;}return paContinue;
}
核心代码在 for循环中,它将数据填充至 *outputBuffer ,随后系统将播放 *outputBuffer 中音频数据。
OK,关于 PortAudio 的更多细节就不再展开,它不是我们此次的重点,如果你对它有兴趣,欢迎访问官网:PortAudio.com。
回调函数
让我们继续回调函数的话题。
目前主流的平台中,音频播放都是以回调机制进行运行,包括 Android 中的 OpenSL ES、oboe,macOS 中的 Audio Queues、Audio Unit,以及 Windows 中的 AudioClient。关于各个平台的播放、录制实现细节可以参考 superpoweredSDK,它提供了统一的封装接口。
在回调函数中,framesPerBuffer 表明需要数据的大小。在低延迟环境下,framesPerBuffer 通常很小,例如 64、92 等,这样才能保证音频延迟尽量的,在 Android 下你可以调用 android.media.AudioManager.getProperty(java.lang.String) 来查询最合适的大小。
回调函数执行的速度至关重要。举个例子,我们假设系统播放采样率为 44100,Buffer 每次送入的大小为 64 个采样,那么播放这个 Buffer 需要 64/44100 = 1.45ms。
如果回调函数执行时间大于 1.45ms,那么音频播放就会产生杂音,这是因为上一个 Buffer 已经播放完毕,但是下一个 Buffer 还没有准备好,这时候系统没有数据进行播放。这种情况也被成为 “underrun”。
在 1_playback_underrun.cpp 中我们模拟了 “underrun” 的情况,即在回调函数中,主动 sleep(1.2ms),此时播放音频就会出现时不时卡顿的情况。显然地,为了避免出现 underrun,必须让回调函数尽可能快。
解码与播放
在最为朴实无华的场景下,我们从文件中读取数据,进行音频数据解码,最后将数据拷贝到系统缓冲中。以 2_playback_from_decode_file.cpp 为例,其回调函数的耗时包括:
- 文件 I/O 耗时,从文件中读取数据的耗时
- 解码算法耗时,将数据解码为音频采样点的耗时
- 将音频拷贝至系统缓冲的耗时

在 framesPerBuffer=64 下,2_playback_from_decode_file.cpp解码 mp3 文件并播放,在 macOS 2.6 GHz 六核Intel Core i7 下,平均耗时 6us 左右。
对比与 1.45ms(1450us),6us似乎是一个足够快的数字,但在某些复杂场景下,它仍然可以优化。例如某些 DAW 能够同时支持上百轨音频同时播放,假设同时播放 200 个音频文件,那么单单读取、解码音频文件需要耗时约 1200us,这已经快要摸到 “underrun” 的裤脚了,就更别想添加各种效果器了。
此外,还有文件共享的问题。极端情况下,上百个音轨可能同时播放同一个音频文件,如果不进行优化,那么需要对同一段音频重复解码上百次。很明显,重复解码可以通过文件共享来解决。
优化策略
在参考了 JUCE、tracktion_engine 后,总结了一下四种解码优化策略。它们有各自的优点和缺点,适合不同的应用场景。
1. 一次性读取音频到内存中
对于时长较短的音频,可以预先将其解码存放在内存中,用空间换时间,牺牲非实时线程的耗时,来减少音频线程中回调函数的执行时间。

这种情况下,音频线程仅有拷贝数据的耗时。在framesPerBuffer=64下,平均耗时为 0.3us 左右,提升约 20 倍。详细代码在 3_playback_from_memory.cpp。
但对于长音频,或者多音频场景,这种方法会快速消耗系统内存,尤其在 Android、iOS 等移动端设置上,内存显得那么的珍贵,过多消耗内存会产生 OOM 系统奔溃。
2. MMAP
方法 1 会导致内存开销过大,那有啥策略可以减少内存开销同时保持不错的文件读取速度呢?可以考虑使用 MMAP。
啥是 MMAP?
mmap是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系。实现这样的映射关系后,进程就可以采用指针的方式读写操作这一段内存,而系统会自动回写脏页面到对应的文件磁盘上,即完成了对文件的操作而不必再调用read,write等系统调用函数。相反,内核空间对这段区域的修改也直接反映用户空间,从而可以实现不同进程间的文件共享
--------------------------------------------------------------------------------------------认真分析mmap:是什么 为什么 怎么用
使用 MMAP 后,我们可以像操作指针一样访问文件,并且常规文件操作需要从磁盘到页缓存再到用户主存的两次数据拷贝。而mmap操控文件,只需要从磁盘到用户主存的一次数据拷贝过程。说白了,mmap的关键点是实现了用户空间和内核空间的数据直接交互而省去了空间不同数据不通的繁琐过程。因此mmap效率更高。
此外,在 认真分析mmap:是什么 为什么 怎么用 优点总结中提到:
4、可用于实现高效的大规模数据传输。内存空间不足,是制约大数据操作的一个方面,解决方案往往是借助硬盘空间协助操作,补充内存的不足。但是进一步会造成大量的文件I/O操作,极大影响效率。这个问题可以通过mmap映射很好的解决。换句话说,但凡是需要用磁盘空间代替内存的时候,mmap都可以发挥其功效。
I/O 效率更高、解决内存空间不足问题,MMAP 的这两个优点正好满足了音频解码的要求。4_playback_mmap.cpp 显示了使用 MMAP 对 wave 32bit-float 文件解码的过程,平均耗时约为 0.9us。

使用 MMAP 看上去非常美好,但它有几个较突出的问题:
- mmap 能力,在不同操作系统下的实现 API 不同,需要进行适配。当然,也有开源的 mio 替你完成了这些繁琐的事情
- 常用的解码库鲜有适配 mmap 的接口,因此需要针对 mmap 进行代码设配与改造。在 JUCE 中,支持 mmap 的解码格式也就只有 wave 和 aif,想必也是因为这两格式解码算法较为简单且是非压缩格式,容易适配。
- 在某些 android 机上,不具有 mmap 能力,无法做到全机型覆盖。
3. 音频转码,再接 MMAP
方法 2 中提到 mmap 不容易进行解码算法适配,例如 mp3 格式。那么有一个曲线救国的办法:先将 mp3 文件转码为一个 wave 的临时文件,接着再使用 mmap 对 wave 进行解码。
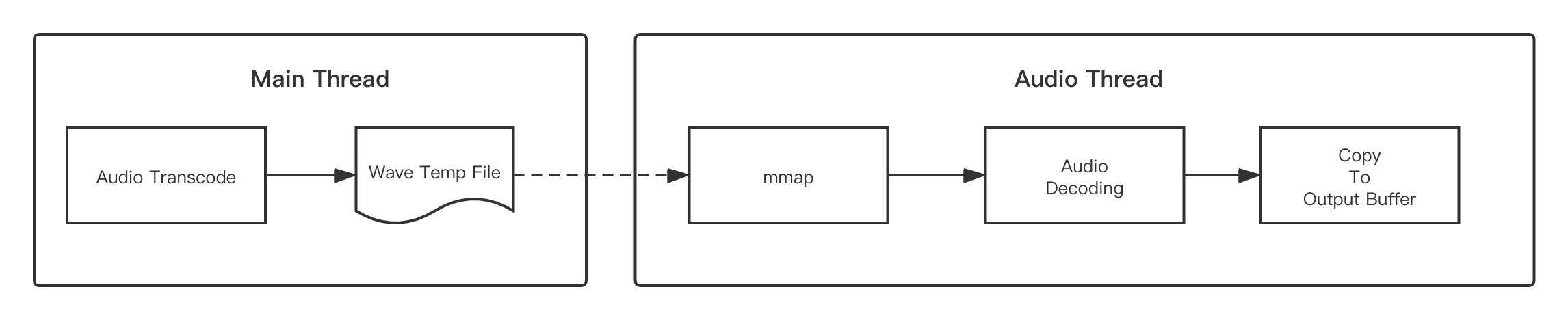
这种方法将转码耗时放在主线程进行(例如转码时显示一个 loading 的 icon),音频线程使用 mmap 进行 I/O 读取和解码,尽量降低耗时。
当然,这种方法的缺点在于得做好零时文件的管理工作,需要额外一些工作量。
4. 解码缓冲
除了上面三种方法,我们也可以采用多线程的策略来降低延迟。简单来说,我们开启一个新线程,该线程会预先读取并解码一大块音频数据到缓存中,这样一来,音频线程消费数据时,如果需要的数据就在缓存中,那么只要拷贝数据即可。
在 JUCE 中,BufferingAudioReader 搭配 TimeSliceThread 可以实现解码缓冲。
简单而言,TimeSliceThread 调用 TimeSliceThread::startThread 启动新线程,它维护了一个任务对列并且负责从对列中选择合适的任务,并执行它。伪代码如下:
// in a new thread
while(1)
{
auto* client = selectClientFromList();
int wait_ms = client->useTimeSlice();
updateClientNextCallTime(client, wait_ms);
}
其中 client 是继承了 TimeSliceClient 的任意实体,其中 useTimeSlice() 是具体要执行的任务。TimeSliceClient 具体代码如下:
class JUCE_API TimeSliceClient
{
public:/** Destructor. */virtual ~TimeSliceClient() = default;/** Called back by a TimeSliceThread.When you register this class with it, a TimeSliceThread will repeatedly callthis method.The implementation of this method should use its time-slice to do something that'squick - never block for longer than absolutely necessary.@returns Your method should return the number of milliseconds which it would like to wait before being calledagain. Returning 0 will make the thread call again as soon as possible (after possibly servicingother busy clients). If you return a value below zero, your client will be removed from the list of clients,and won't be called again. The value you specify isn't a guarantee, and is only used as a hint by thethread - the actual time before the next callback may be more or less than specified.You can force the TimeSliceThread to wake up and poll again immediately by calling its notify() method.*/virtual int useTimeSlice() = 0;private:friend class TimeSliceThread;Time nextCallTime;
};
BufferingAudioReader 继承了 TimeSliceClient 并实现 useTimeSlice(),它任务负责解码数据到缓存中,伪代码如下:
int BufferingAudioReader::useTimeSlice()
{// 下一个读取的位置auto pos = nextReadPostion;// 当 pos 不在缓存对列中时,说明要进行新一轮的解码if(needNewSamples(pos)){auto block = readSamples(pos); // 解码新的音频数据pushBlockToList(block); // 将数据放入缓存对列中}
}
JUCE 中解码缓冲基本原理还是挺简单的,但具体代码实现依赖了太多 JUCE 的其他模块,想要单独抽取这部分功能比较麻烦。其实我们可以自己动手实现一份,例如 me_time_slice_thread.cpp(仅供参考)。
在有解码缓冲的情况下,音频线程中解码的速度接近于从内存拷贝的速度,约 0.6us。当然,多线程环境下,系统行为更为复杂,代码理解起来会更复杂一些。
详细代码请参考 5_playback_buffering.cpp。
总结
本文介绍了四种音频解码的优化策略,它们各有优劣,适用于不同的场景,下面的表格对其进行了总结。
| 方法 | 优点 | 缺陷 |
|---|---|---|
| 读取到内存 | 速度最快 | 内存消耗大,不适合多音频、长音频场景,不适合内存较小的设备 |
| MMAP | 速度快,内存开销小 | 需要兼容不同平台的 MMAP API;需要音频解码算法进行适配;移动端有些机型无法使用 mmap |
| 转码 + MMAP | 速度快,内存开销小,解码算法适配成本低 | 需要兼容不同平台的 MMAP API;移动端有些机型无法使用 mmap;需要对零时文件做好管理 |
| 解码缓冲 | 速度较快 | 多线程带来了更加复杂的系统行为 |
参考资料
Android Developers - NDK - 指南 - 音频延迟
Windows - 驱动程序 - 音频 - 低延迟音频
认真分析mmap:是什么 为什么 怎么用