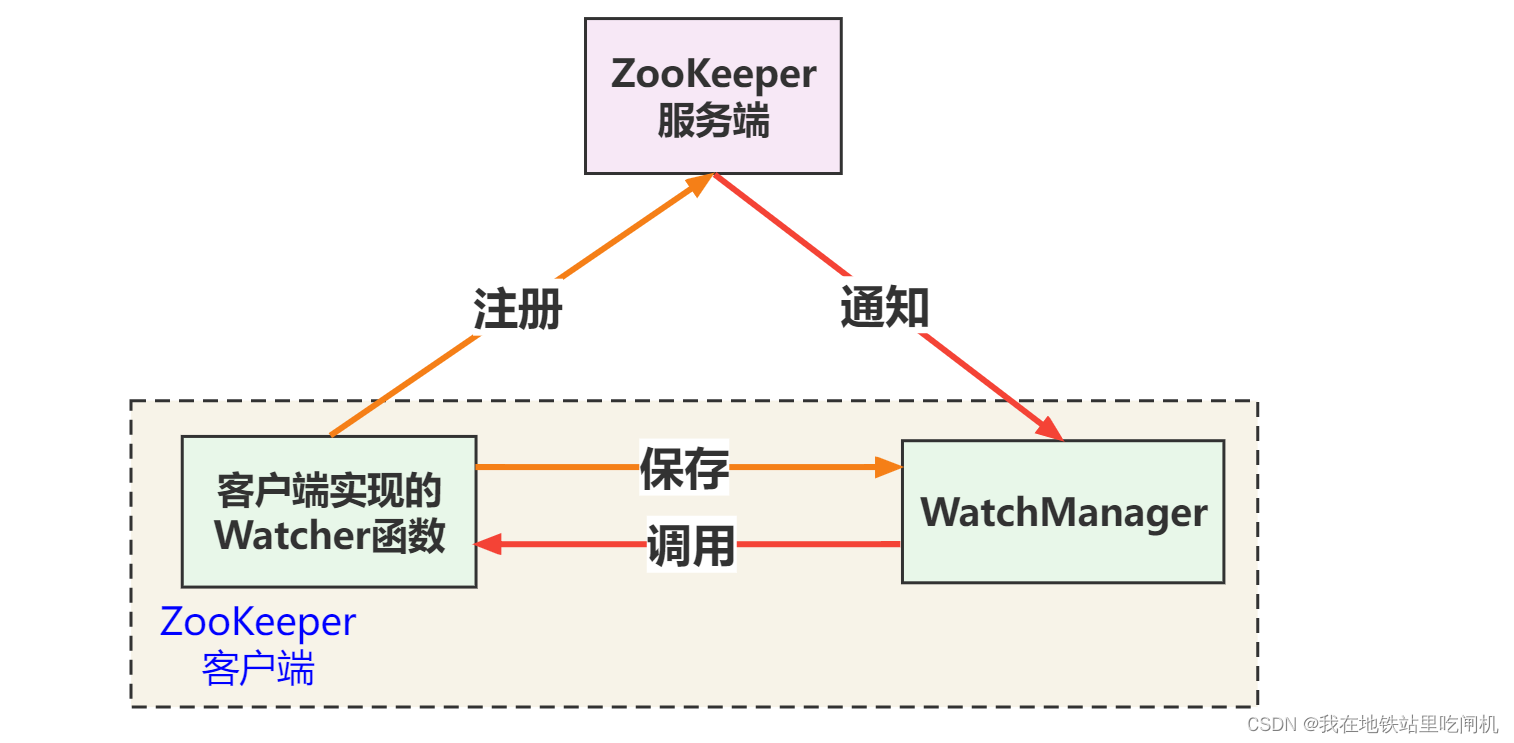
1. 简介
文章简称为LIIF,即Local Implicit Image Function,受到了3D视觉里场景或物体的隐式表示思想的启发,主要的想法便是把正常的图像当做是连续的,用神经网络表示这个图像之后,对于图像上的每一个像素点其实就当做了一次查询,从而就能实现图像的超分辨率了,并且还是任意尺度的超分,和Meta-SR的工作取得的效果是一样的,在看本文之前,建议先看一下我写的Meta-SR里面的一些相关研究介绍。
2. 思路
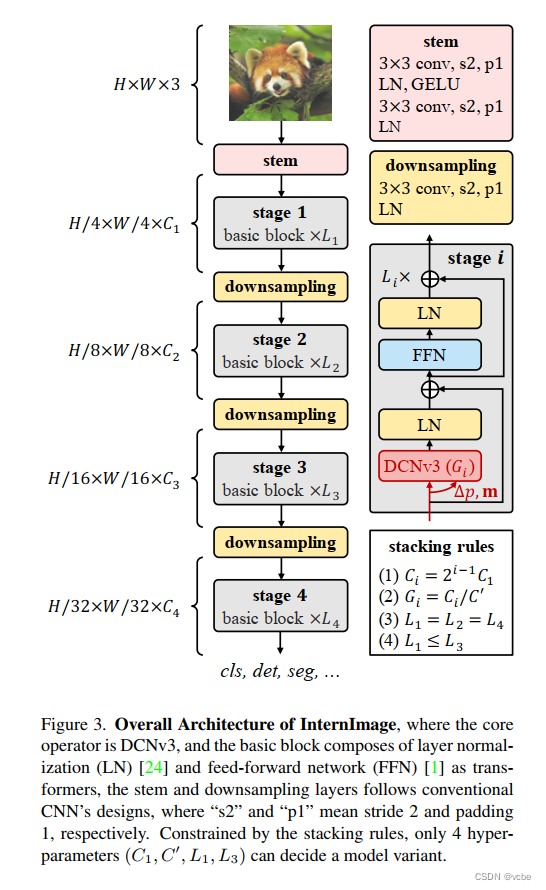
- 在本文里,当然不是将图像直接用神经网络表示那么简单,在一般的超分领域,图像将会通过两个步骤进行处理,首先经过特征提取模块得到与输入相同尺寸、更深通道的特征图(本文通道数为64),然后经过上采样得到SR图像。在本文中,保留了前半部分的特征提取模块,也就是说,特征提取模块可以随意更换成不同论文里的方法,如ESDR,RDN等等
- 当得到特征图之后,我们可以将其想象成放在一个 [ − 1 , 1 ] [-1,1] [−1,1]的平面直角坐标系内,然后对于一张新的任意分辨率的SR图像,其像素都有对应的、所属于这个平面直角坐标系的二维坐标,从而也有对应的一个特征图像素,以及这个像素的通道(可以看成长度为64的一维向量)
- 把这个像素通道的特征向量(64)、SR图像的某个像素坐标与特征图像素坐标的相对位置(2)组成一个新的一维向量,当做MLP的输入,然后输出一个一维的长度为3向量,当做这个SR图像的像素应有的值,就实现了超分辨率重建
- 有多少个SR像素,就查询多少次MLP,全部查询完之后,就组成了SR图像,而图像的分辨率将不再受网络结构本身的影响,实现了分辨率与图像内容表示的解耦合,即使我想生成一张 10000 ∗ 10000 10000*10000 10000∗10000像素的超分图像,也不用去考虑显存大小开支,只需要把MLP的batchsize设置的大一点,让它多迭代几次就行了
- 当然在具体实现过程中,还有local ensemble,feat_unfold,cell decoding等细微操作,但是总的框架如上所示,其实是比较容易理解的
3. 代码层面的详细理解
3.1 数据处理
以div2k数据集为例,结合本文项目代码(liif)梳理一下训练数据预处理流程:
- div2k数据集的高分辨率训练集由800张2K图像组成,每张图像尺寸不一,如 2040 ∗ 1848 , 2040 ∗ 1404 2040*1848,2040*1404 2040∗1848,2040∗1404等等,因此需要进行某种归一化处理
- 对于每张图像,如果不设置inp_size参数,默认是将其给随机缩放到1-4倍之间,作为crop_lr图像,原图作为crop_hr图像;如果设置inp_size参数(inp_size=48),是先随机生成一个长宽均为 48 − 48 ∗ 4 48-48*4 48−48∗4像素之内的占位方框,然后随机扔到原图中框出这部分区域作为crop_hr,然后把这部分区域进行双三次插值缩放到 48 ∗ 48 48*48 48∗48像素作为crop_lr。可以看到,不管原图像尺寸如何,都给统一变成了crop_hr和crop_lr以便于进行下一步处理(虽然这俩变量尺寸大小对于每张图像也不相同)
- 以0.5几率进行左右翻转,上下翻转,对称翻转来数据增强,因此训练集可以复制20倍,这里就相当于用了共16000张图像用来训练了
- 对于crop_hr,我们要想将其统一,就得将其精细到像素层次,具体做法是:假定每张图像都统一连续表示与二维的[-1,1]正方形平面坐标系区域内,然后我们就可以根据分辨率大小进行坐标系网格划分(肯定分辨率越高网格就越密)这一个个划分后的坐标系小网格就代表了crop_hr的像素(可以想象,如果crop_hr是正方形,那么划分后的坐标系网格是正方形,如果crop_hr是长方形,那么划分后的坐标系小网格肯定就是长方形了,因为原项目设置了inp_size参数,因此第二步骤的crop_hr和crop_lr都是正方形,后面的讨论就都当做正方形来看待了)
- 划分坐标系网格之后,那么以坐标系每个小网格中心点的坐标取值可以确定hr_coord,这个值对应的像素值可以确定hr_rgb,二者一一对应,且共有 4 8 2 − 19 2 2 48^2-192^2 482−1922对这样的值,具体多少对每张图像都是不一定的,因为在第二步骤里的那个框是48给随机扩展1-4倍的
- 但是这样不要紧,我们在配置里有个sample_q参数(sample_q=2304),意思是对这些hr_coord-hr_rgb对随机取sample_q个,得到正式的hr_coord与hr_rgb,也是在这一步,实现了某种意义上的训练图像归一化,而这样随机取会不会丢失信息呢?感觉不会,因为这些采样点差不多均匀覆盖了坐标系正方形的区域,而 2304 = 4 8 2 2304=48^2 2304=482,取的其实也算是足够多了
- 最后对于每张图像,总共提取出四个数值,分别为:
- crop_lr:大小48*48像素,为2K原图随机框选48-192像素大小区域之后再将该区域缩放,作为低分辨率图像,也是神经网络的输入
- hr_coord:随机打乱的sample_q个正方形区域内的采样点坐标,均匀覆盖了[-1,1]
- hr_rgb: 这些采样点坐标对应的真实rgb值,和hr_coord一起作为ground truth
- cell:平面坐标系内的划分的方格宽度
3.2 网络结构
网络的输入为任意一张低分辨率的图像,输出为对应的我们指定的任意分辨率的图像
- 网络接收低分辨率图像后,可以经过encoder,也就是某种超分辨率网络(如ESDR,RDN)的上采样之前的部分,输出相同尺寸大小与某深度(这里是64)的特征图。
大致阅读了ESDR(2017)、RDN(2018)这两篇论文,在单张图像超分辨率(SISR)领域,大致做法就是将低分辨率的输入图像,经过神经网络(如ESDR的残差网络,RDN的稠密残差网络),得到相同尺寸的特征图,其深度高达64,得到之后我们根据需要选择不同的上采样层(比如x2倍,x4倍)来得到超分之后的图像。而在训练过程中,后面的上采样层其实就像是一个可以替换的零部件,因为网络的核心部分都在前面了,如果我想训练一个x4的超分辨率网络,完全可以拿一个x2的训练好的超分辨率网络前面的现成的参数,把后面的上采样层换成x4即可,这样替换之后再训练其实可以更快地达到收敛。
- 有了特征图,接下来就是围绕特征图所进行的一系列操作,在此之前,先介绍一下文中所提到的坐标系概念,如图所示,假定我们的特征图的长宽均为4(这里只是方便举例子,实际操作中特征图长宽和输入的低分辨率图长宽一样),那么其实可以将其放在一个限定范围在[-1,1]的二维平面直角坐标系内,这样就仿佛整张图片是连续的,我们要得到更高的分辨率,只需要查询一下想要的高分辨率像素的中心点坐标即可:

举个例子,左图为一张 4 ∗ 4 4*4 4∗4的特征图给放到坐标系之后的样子,第一行第一列像素中心点坐标为(-0.75,-0.75),第一行第二列像素中心点坐标为(-0.75,-0.25)这样子;而如果我们想要将其进行超分重建,比如想要分辨率为 11 ∗ 11 11*11 11∗11,那么就像右图的样子先设定一个蓝色的框框,放在[-1,1]这个范围内,然后就让这个蓝色框框每个蓝色像素(后面就把超分辨率图的像素统一称作蓝色像素了)的中心点坐标对这个由特征图表示的[-1,1]区域进行采样即可
- feat_unfold:在继续深入讲之前,说一下文中提到的feat_unfold的概念,其实我们可以理解为将这张 4 ∗ 4 4*4 4∗4的特征图的深度给加深,比如每个像素原先是64通道,现在给变成 64 ∗ 9 64*9 64∗9个通道,多出来8个通道其实就是每个像素周围一圈周围8个像素的通道,如果是在边缘的话就给padding一圈0,在代码里其实借助nn.functional.unfold函数即可实现,至于这么做的原因,可以理解为每个像素的特征肯定和周围的像素特征有关,我们不妨直接把他们给拼接起来,相当于每个像素不是那么独立
- 那么究竟该如何从这个[-1,1]的区域内根据特征图查询蓝色像素点的值呢?是借助MLP实现的,这个MLP的输入其实共有 580 = 64 ∗ 9 + 2 + 2 580=64*9+2+2 580=64∗9+2+2个神经元,其中的 64 ∗ 9 64*9 64∗9代表每一个特征图像素的通道数,一个2是指蓝色像素的相对坐标,另一个2是指cell decoding(这俩后面细讲)
我们想要查询蓝色像素,首先得根据超分图分辨率来确定这个蓝色框框到底长宽为多少,然后生成对应的蓝色像素中心点坐标,在查询的时候,是分批次查询的,比如batchsize设成30000,就代表每一批查询30000个蓝色像素,MLP在具体处理的时候,接收的tensor尺寸其实为(30000,580),输出的tensor尺寸为(30000,3),其中3代表RGB值
- 下面就产生了一个像素的对应问题,我有了一个蓝色像素的中心点坐标,该如何确定MLP的输入呢?其实主要需要确定两个方面,一个方面是这个蓝色像素应该对应哪个特征图像素以便于取得其通道(64*9),另一个是相对坐标与cell decoding,这里就是文中所谓的local ensemble部分
- 如下图所示其实就能更好理解,对于每一个蓝色像素中心点(左图的蓝色点),首先生成一个以蓝色像素中心点为中心的与特征图像素点一样大的橙色框框,这个橙色框框的四个顶点(粉红色点)其实都有其所属的特征图像素,根据这四个粉红色点就能找到四个特征图像素的中心点(黑色点),然后就能计算四个黑色点与蓝色点的绝对距离向量了(绿色箭头),而这个绝对距离向量我们发现其实x,y坐标的取值最大分别为特征点像素的高与宽,乘以特征点像素长宽就能得到相对距离向量了,也就是MLP所应当输入的相对坐标两个值

上面说的其实是在代码层面的理解,因为借助了grid_sample函数,如果从抽象层面简单理解的话,其实就是上面的右图,像论文里所表示的,根据蓝色点来确定其周围最近的四个特征像素中心点坐标并且计算相对坐标,作为MLP的输入
- 但是对于一个蓝色像素,我们发现在上面的步骤中其实能产生四个相对坐标,并且每个相对坐标对应着不同的特征像素,在代码层面来看的话,每一次查询,输入的tensor为(30000,2),代表30000个蓝色像素的中心点,在每一次查询里,其实有四次循环,这四次分别计算出30000个蓝色像素点的左上、右上、左下、右下四个相对坐标与四个特征像素的通道,每次循环计算好之后,都会作为MLP的输入进行前向传播,得到30000个RGB值,作为这个蓝色像素左上、右上、左下、右下四个方向应该的RGB值
- 在每次查询中我们的最终目标是得到这30000个像素的RGB值,因为其内部经历了四次循环,其实得到的是这个蓝色像素中心点四个角上的RGB值,而要计算这个蓝色像素究竟是啥RGB值,其实可以做某种权重分配的“插值”即可,在文中是计算了四个矩形区域的面积,哪个区域面积越小,就能得到更大的权重
- 其实总的来看,虽然说将图像看做了一个连续的区域,要进行超分辨率重建只需要查询对应蓝色像素中心点坐标所应有的RGB即可,但是在实际的代码执行层面中,却不是简单的吧这个蓝色像素中心点所属的特征像素的通道与相对坐标直接丢入MLP得到RGB,而是丢了四次,计算出四个顶点区域的RGB并且做了插值处理。至于为啥要这么做呢,其实这样可以缓解当相邻两个蓝色像素对应的特征像素不一样时最终图像在视觉上看起来不连续的效果(当然不是彻底解决,只是缓解!因为即使是四个像素,也会存在“跳跃”的现象呀)
3.3 cell decoding
按理说,我在这个连续的[-1,1]范围内查询的蓝色像素中心点坐标所对应的颜色就应当是最终的像素颜色,但是我们忽略了一个问题,那便是:我们毕竟查询的是一个正方形的蓝色像素区域,如果仅仅用这个蓝色像素中心点的颜色来表示这整个蓝色像素的颜色会不会有失偏颇呢?或者我们考虑下这种情况:假定我们第一次去查询一张 2 ∗ 2 2*2 2∗2的超分辨率图像,查询第二象限的时候,也就是左上角的那个像素时,中心坐标为(-0.5,-0.5);如果我们再去查询一张 6 ∗ 6 6*6 6∗6的超分辨率图像的话,第二象限会有9个蓝色像素,那么中间那个蓝色像素的中心点坐标其实也是(-0.5,-0.5),相同的中心点坐标,对应着不同的蓝色像素大小,那么这俩像素最终的颜色应该一个样吗?从直觉上来说是不应该一样的,因为我们不能仅仅用中心点的颜色来代表整个像素的颜色,因为本身这个像素的大小是不确定的,在像素块尺寸越小的时候肯定效果区分不明显,但是一旦像素块变大了情况就不容忽略了!因此,MLP的输入特征数还有2个值的位置,就代表了要查询的这个蓝色像素的大小