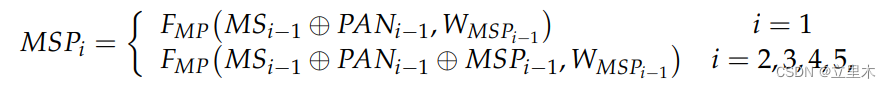基于Deformable Conv的大规模基础模型
特点:
- 采用Deformable Conv V3 【v2 19论文】
- CNN模型
背景
大规模的ViT模型借助模型能力在超大规模数据集上取得了非常高的性能,然而大规模CNN模型研究才刚刚开始。
近期CNN研究倾向于使用大的卷积kernel,以获得更大的感受野和大范围依赖。该文提出了基于Deformable Conv的大规模CNN模型,不仅有大的感受野适应下游密集识别任务,而且可以自适应Spatial维度特征聚集,计算高效,取得了ViT相当的性能。适用于分类、分割和检测任务,并在COCO上取得了SOTA的结果。
动机
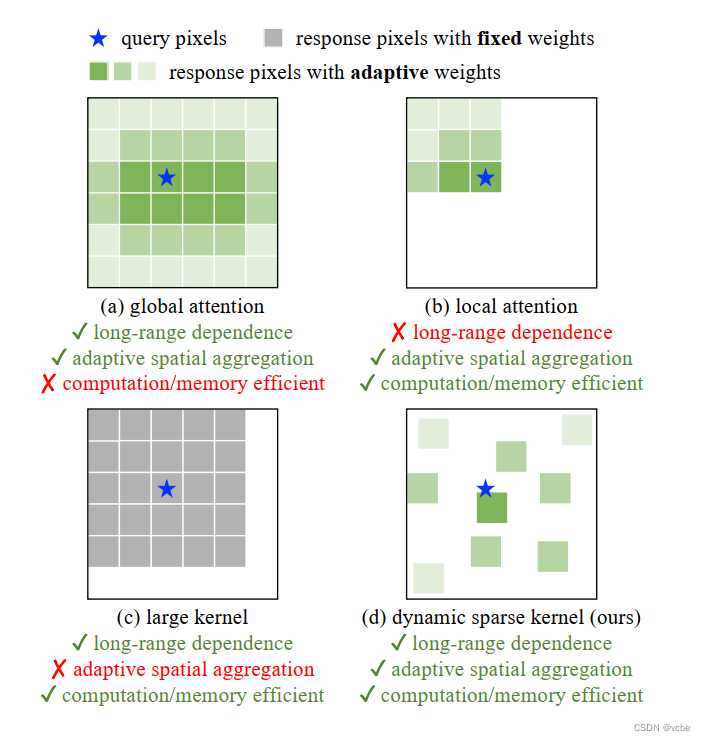
算子特性对比,灰色表示固定权重的kernel,绿色表示自适应权重的kernel。
| 算子 | 长距离依赖 | 自适应Spatial特征聚集 | 计算/内存高效 |
|---|---|---|---|
| global aggregation of multi-head self-attention (MHSA) | ✓ \checkmark ✓ | ✓ \checkmark ✓ | |
| Swin transformer -Local Window MHSA | ✓ \checkmark ✓ | ✓ \checkmark ✓ | |
| 大Kernel卷积 | ✓ \checkmark ✓ | ✓ \checkmark ✓ | |
| 动态稀疏kernel-Deformable Conv V2 | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ |
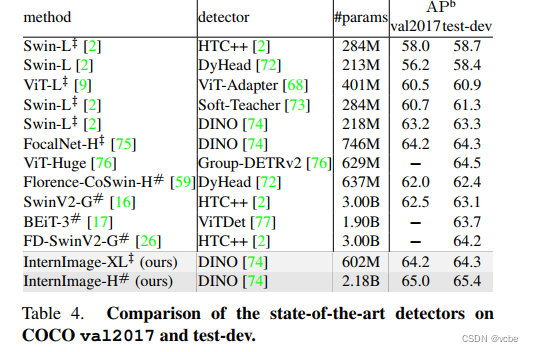
结果
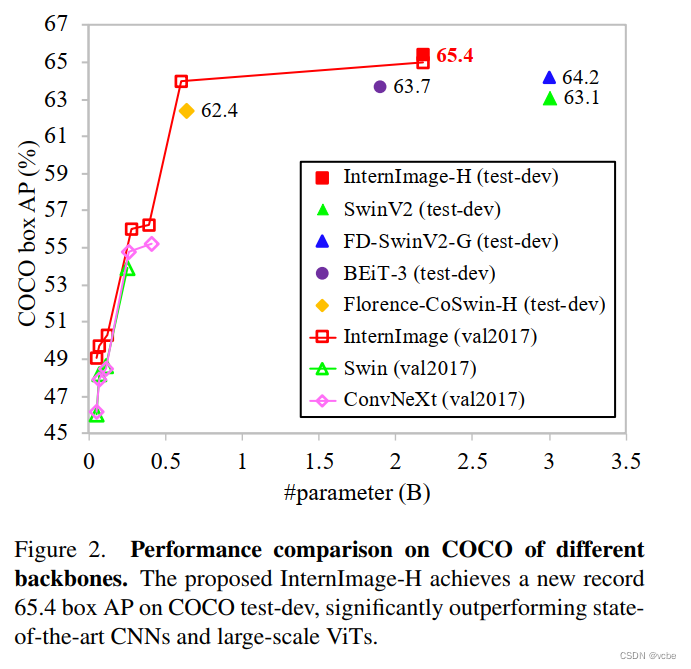
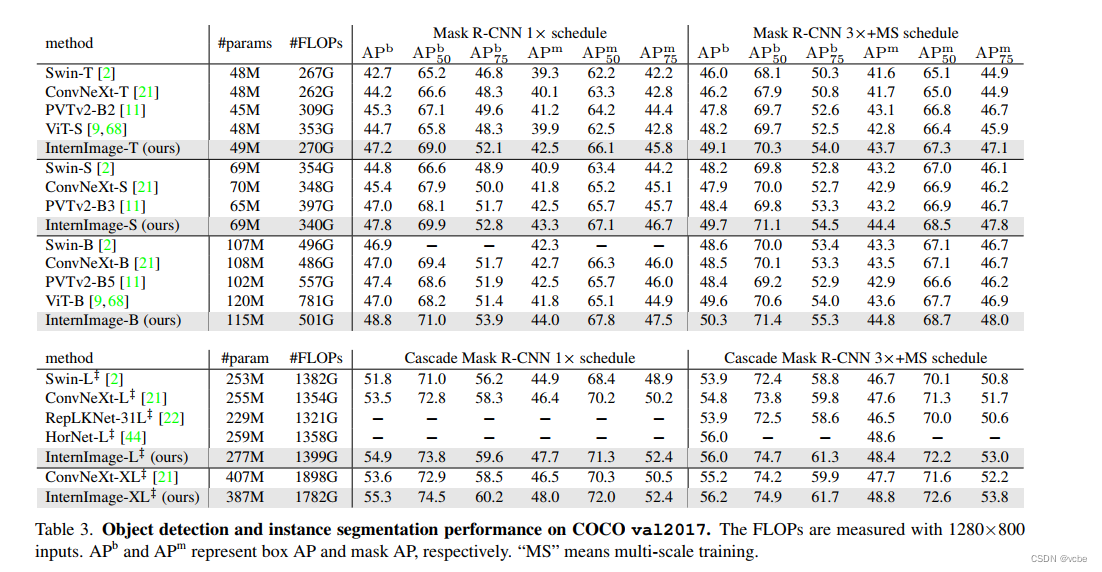
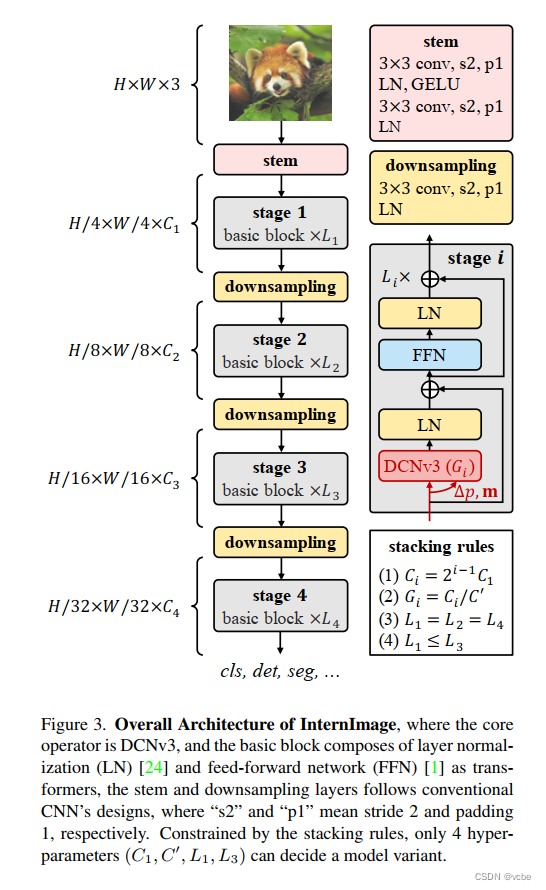
细节
Deformable-Conv V2
y ( p 0 ) = ∑ k = 1 K w k m k X ( p 0 + p k + Δ p k ) y(p_0)=\sum_{k=1}^{K}w_km_kX(p_0+p_k+\Delta{p_k}) y(p0)=k=1∑KwkmkX(p0+pk+Δpk)
K K K为采样点数量, p 0 p_0 p0为当前像素, m k m_k mk为尺度放缩参数, Δ p k \Delta{p_k} Δpk为第k个格点的偏移量。
Deformable Conv V3
- 引入Depth-wise 和Point-wise Conv 提高权重共享效率
- 将spatial aggregation 操作分组
- 将Element-wise Sigmoid 换成softmax ,提高训练稳定性
- 稀疏kernel 更高效
y ( p 0 ) = ∑ g = 1 G ∑ k = 1 K w g m g k X g ( p 0 + p k + Δ p g k ) y(p_0)=\sum_{g=1}^{G}\sum_{k=1}^{K}w_gm_gkX_g(p_0+p_k+\Delta{p_{gk}}) y(p0)=g=1∑Gk=1∑KwgmgkXg(p0+pk+Δpgk)
G表示aggregation分组数
代码
未开源