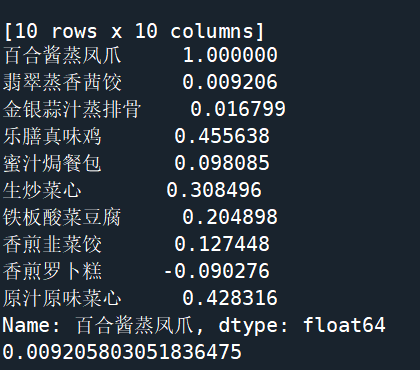
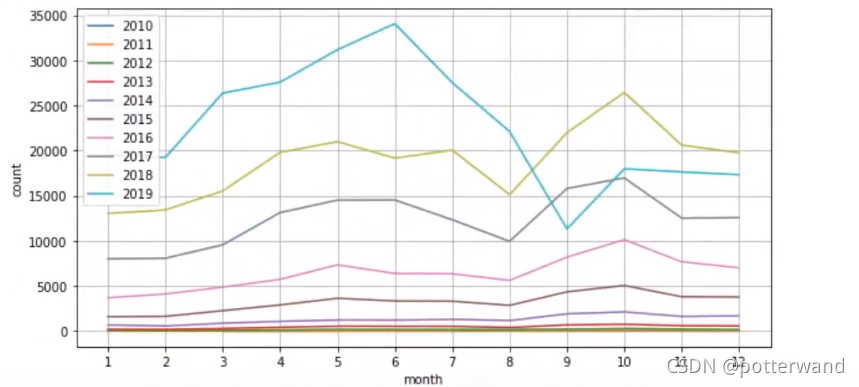
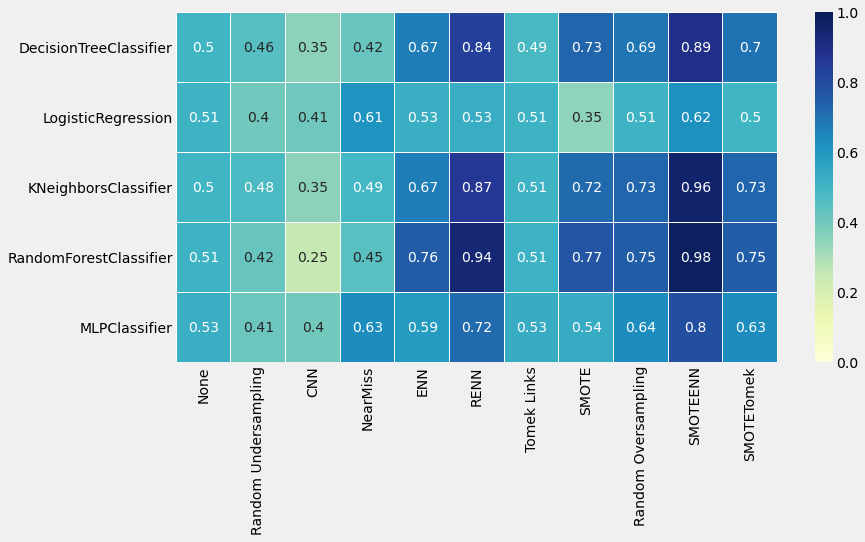
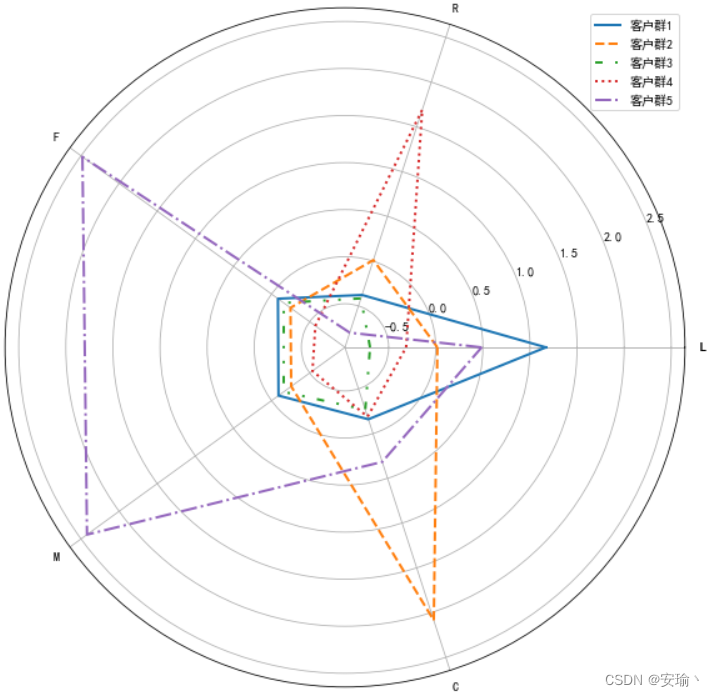
1、分析问题,明确目标
有目的解决问题才会事半功倍。
2、模型可行性分析
并不是所有问题都需要数据挖掘模型或着能通过数据挖掘模型来解决。在建模之前需要进行可行性分析。判断模型可行性的流程如图所示:

3、 选取模型
根据问题定义选则合适的模型:决策树、随机森林、XGBoost等。
4、 选择变量
变量分类:
- 非实时变量:基于历史数据,对时效性要求不高;
- 实时变量:短时间内获取的最新数据。
提取和选取变量的常规步骤:
- 通过PRD文档、业务方需求文档,建立变量池;
- 组织变量讨论会,拓展对业务的认知,丰富变量池;
- 借助SQL语句从数据库中提取变量,一小部分数据由业务方直接通过表格提供。
5、特征工程
在确定好变量之后,对这些变量进行处理,称为特征工程。
(1)验证逻辑。常见的逻辑错误:因果关系倒置;忽略模型陕西概念后变量数据计算的时效性;在取数过程中出现错误。
(2)重复数据和测试数据:一般都是删除处理444
(3)缺失值处理:对于一些模型(如XGboost),在符合逻辑、确保缺失值具有一定意义的前提下,可以不做处理,其他情况下都要处理。
(如果缺失比例高于30%,一般放弃这个变量;如果低于30%才进行处理)
常用处理方法:
用特定值表示(如:-9999);
统计插值(均值、中值、众数),适用于数据型变量;
模型插值:SKNN,参考最邻近的K个值进行填补;
EM聚类,选择不存在缺失值的变量进行聚类,根据所在类的其他值进行填补。
(4)异常值处理:判断业务逻辑在取数计算过程中是否出现错误,如需要对数据唯一性进行验证。
判断异常值方法:
统计方法:3σ、盒形图、分位数 模型法:
iforest孤立森林。
处理异常值的方法:
删除异常数据所在的记录
将异常值标志为缺失值,用填补缺失值的方法进行处理。
6、建立模型和效果评估
7、模型上线和迭代
在模型正式陕西概念之前,通常需要将模型封装成特定的模型文件交由开发部门,开发部门定时调用模型文件。(有些模型如线性回归模型,无须交付模型文件,只需要提供变量对应的参数即可)。
目前比较常用的方法是将机器学习/数据挖掘模型打包成PMML文件。
PMML(Predictive Model Markup language)是一种基于XML的预测模型标记语言:
任何语言都可以调用模型。
不存在调用的通信消耗。
直接部署上线,无须二次开发。
支持数据转换,比如标准化和one-hot编码等。
在模型上线前需要提前定制好监控策略,保证模型效果在可控范围内。
我们要时刻保持对模型的迭代,并在相应的代码管理平台及时更新代码,做好模型版本编号,以此形成一个完整的闭环。