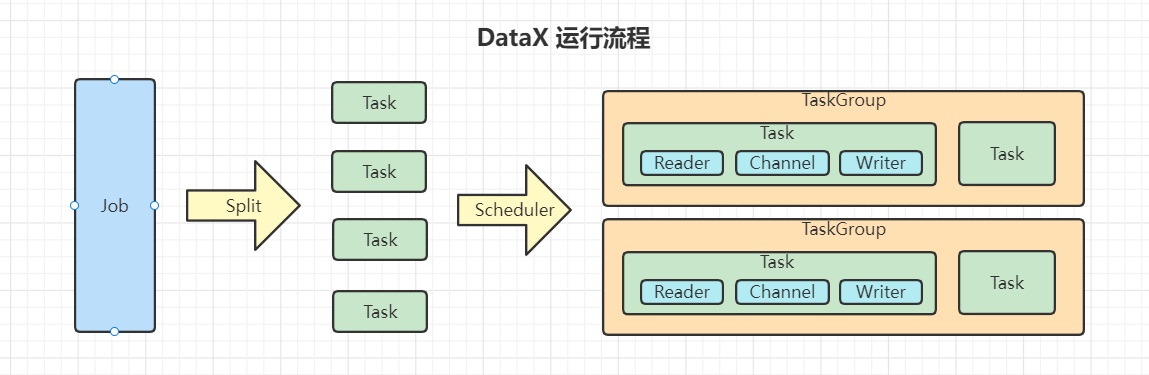
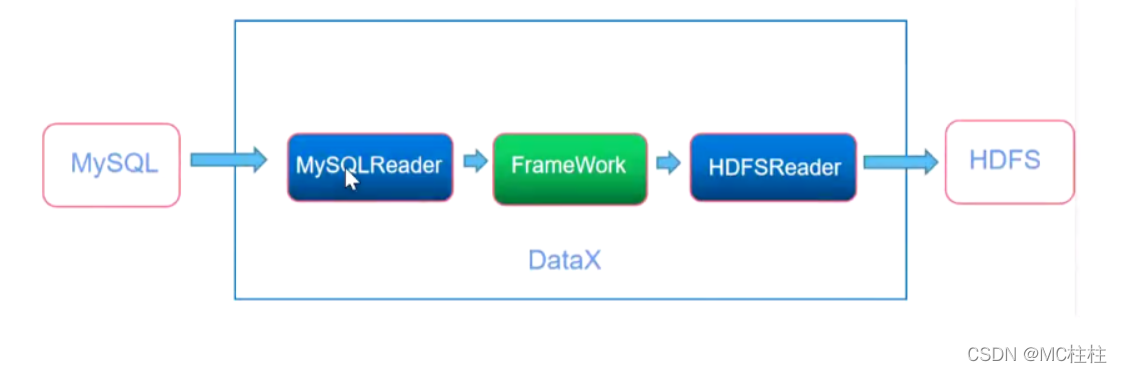
datax 直接使用py文件进行任务提交,今天读一读它
一、文件位置
原始文件位置在 xx/DataX/core/src/main/bin/下,datax项目打包后会将文件拷贝到 xx/DataX\target\datax\datax\bin 下。
core模块的pom.xml 指定‘拷贝’datax.py文件的方式maven-assembly-plugin<plugin><artifactId>maven-assembly-plugin</artifactId><configuration><archive><manifest><mainClass>com.alibaba.datax.core.Engine</mainClass></manifest></archive><finalName>datax</finalName><descriptors><!--指定装配的配置文件--><descriptor>src/main/assembly/package.xml</descriptor></descriptors></configuration><executions><execution><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin>DataX\core\src\main\assembly\package.xml里面是一些打包的细节二、文件的作用
该py文件主要用来提交datax任务,相当于datax的入口;样例执行datax任务如下
python datax.py {YOUR_JOB.json}
三、文件解读
文件的主入口 if name == “main”:
if __name__ == "__main__":# 1 打印版权信息printCopyright()# 2 获取选项的解析器parser = getOptionParser()# 3 根据入参,使用解析器解析出参数值# 3.1 parse_args方法返回俩参,分别为instance类型的options和list类型的args# 3.2 用sys.argv[1:]来获取命令参数,返回一个list类型的返回值options, args = parser.parse_args(sys.argv[1:])if options.reader is not None and options.writer is not None:# 4 如果解析后,入参的 reader和writer不为空,在从github上构建出一个 json的样例模板generateJobConfigTemplate(options.reader,options.writer)sys.exit(RET_STATE['OK'])if len(args) != 1:parser.print_help()sys.exit(RET_STATE['FAIL'])# 5 根据入参 构建执行脚本startCommand = buildStartCommand(options, args)# print startCommand 该命令可以打印出 用户输入的参数+py文件构建的参数,作为整体形成一个执行脚本。(执行脚本最后调用java类)# 打印出来的startCommand 如下:# java -server -Xms1g -Xmx1g -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=D:\idea-workspace\github\DataX\target\datax\datax/log -Xms1g -Xmx1g -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=D:\idea-workspace\github\DataX\target\datax\datax/log -Dloglevel=info -Dfile.encoding=UTF-8 -Dlogback.statusListenerClass=ch.qos.logback.core.status.NopStatusListener -Djava.security.egd=file:///dev/urandom -Ddatax.home=D:\idea-workspace\github\DataX\target\datax\datax -Dlogback.configurationFile=D:\idea-workspace\github\DataX\target\datax\datax/conf/logback.xml -classpath D:\idea-workspace\github\DataX\target\datax\datax/lib/* -Dlog.file.name=x\datax\job\job_json com.alibaba.datax.core.Engine -mode standalone -jobid -1 -job D:\idea-workspace\github\DataX\target\datax\datax\job\job.json# 6 创建并返回一个子进程,并在这个进程中执行指定的shell 脚本child_process = subprocess.Popen(startCommand, shell=True)# 7 将执行结果保存在信号量中register_signal()# 8 父子进程进行通信,并将通信结果保存到 stdout, stderr(stdout, stderr) = child_process.communicate()# 9 退出(根据子进程的状态码)sys.exit(child_process.returncode)
文件中的方法和变量,通过变量名或函数名就可以直接猜到含义,本文不在赘述;

整体的datax.py文件如下
#!/usr/bin/env python
# -*- coding:utf-8 -*-import sys
import os
import signal
import subprocess
import time
import re
import socket
import json
from optparse import OptionParser
from optparse import OptionGroup
from string import Template
import codecs
import platformdef isWindows():return platform.system() == 'Windows'DATAX_HOME = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))DATAX_VERSION = 'DATAX-OPENSOURCE-3.0'
if isWindows():codecs.register(lambda name: name == 'cp65001' and codecs.lookup('utf-8') or None)CLASS_PATH = ("%s/lib/*") % (DATAX_HOME)
else:CLASS_PATH = ("%s/lib/*:.") % (DATAX_HOME)
LOGBACK_FILE = ("%s/conf/logback.xml") % (DATAX_HOME)
DEFAULT_JVM = "-Xms1g -Xmx1g -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=%s/log" % (DATAX_HOME)
DEFAULT_PROPERTY_CONF = "-Dfile.encoding=UTF-8 -Dlogback.statusListenerClass=ch.qos.logback.core.status.NopStatusListener -Djava.security.egd=file:///dev/urandom -Ddatax.home=%s -Dlogback.configurationFile=%s" % (DATAX_HOME, LOGBACK_FILE)
ENGINE_COMMAND = "java -server ${jvm} %s -classpath %s ${params} com.alibaba.datax.core.Engine -mode ${mode} -jobid ${jobid} -job ${job}" % (DEFAULT_PROPERTY_CONF, CLASS_PATH)
REMOTE_DEBUG_CONFIG = "-Xdebug -Xrunjdwp:transport=dt_socket,server=y,address=9999"RET_STATE = {"KILL": 143,"FAIL": -1,"OK": 0,"RUN": 1,"RETRY": 2
}# 获取本地ip
def getLocalIp():try:return socket.gethostbyname(socket.getfqdn(socket.gethostname()))except:return "Unknown"# 根据信号值,结束本 子进程
def suicide(signum):global child_processprint >> sys.stderr, "[Error] DataX receive unexpected signal %d, starts to suicide." % (signum)if child_process:child_process.send_signal(signal.SIGQUIT)time.sleep(1)child_process.kill()print >> sys.stderr, "DataX Process was killed ! you did ?"sys.exit(RET_STATE["KILL"])#
def register_signal():if not isWindows():global child_processsignal.signal(2, suicide)signal.signal(3, suicide)signal.signal(15, suicide)# 构造解析器
def getOptionParser():usage = "usage: %prog [options] job-url-or-path"parser = OptionParser(usage=usage)prodEnvOptionGroup = OptionGroup(parser, "Product Env Options","Normal user use these options to set jvm parameters, job runtime mode etc. ""Make sure these options can be used in Product Env.")prodEnvOptionGroup.add_option("-j", "--jvm", metavar="<jvm parameters>", dest="jvmParameters", action="store",default=DEFAULT_JVM, help="Set jvm parameters if necessary.")prodEnvOptionGroup.add_option("--jobid", metavar="<job unique id>", dest="jobid", action="store", default="-1",help="Set job unique id when running by Distribute/Local Mode.")prodEnvOptionGroup.add_option("-m", "--mode", metavar="<job runtime mode>",action="store", default="standalone",help="Set job runtime mode such as: standalone, local, distribute. ""Default mode is standalone.")prodEnvOptionGroup.add_option("-p", "--params", metavar="<parameter used in job config>",action="store", dest="params",help='Set job parameter, eg: the source tableName you want to set it by command, ''then you can use like this: -p"-DtableName=your-table-name", ''if you have mutiple parameters: -p"-DtableName=your-table-name -DcolumnName=your-column-name".''Note: you should config in you job tableName with ${tableName}.')prodEnvOptionGroup.add_option("-r", "--reader", metavar="<parameter used in view job config[reader] template>",action="store", dest="reader",type="string",help='View job config[reader] template, eg: mysqlreader,streamreader')prodEnvOptionGroup.add_option("-w", "--writer", metavar="<parameter used in view job config[writer] template>",action="store", dest="writer",type="string",help='View job config[writer] template, eg: mysqlwriter,streamwriter')parser.add_option_group(prodEnvOptionGroup)devEnvOptionGroup = OptionGroup(parser, "Develop/Debug Options","Developer use these options to trace more details of DataX.")devEnvOptionGroup.add_option("-d", "--debug", dest="remoteDebug", action="store_true",help="Set to remote debug mode.")devEnvOptionGroup.add_option("--loglevel", metavar="<log level>", dest="loglevel", action="store",default="info", help="Set log level such as: debug, info, all etc.")parser.add_option_group(devEnvOptionGroup)return parser# 根据writer和reader名, 从github拉取对应的模板,最终创建出 json任务的模板
def generateJobConfigTemplate(reader, writer):readerRef = "Please refer to the %s document:\n https://github.com/alibaba/DataX/blob/master/%s/doc/%s.md \n" % (reader,reader,reader)writerRef = "Please refer to the %s document:\n https://github.com/alibaba/DataX/blob/master/%s/doc/%s.md \n " % (writer,writer,writer)print readerRefprint writerRefjobGuid = 'Please save the following configuration as a json file and use\n python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json \nto run the job.\n'print jobGuidjobTemplate={"job": {"setting": {"speed": {"channel": ""}},"content": [{"reader": {},"writer": {}}]}}readerTemplatePath = "%s/plugin/reader/%s/plugin_job_template.json" % (DATAX_HOME,reader)writerTemplatePath = "%s/plugin/writer/%s/plugin_job_template.json" % (DATAX_HOME,writer)try:readerPar = readPluginTemplate(readerTemplatePath);except Exception, e:print "Read reader[%s] template error: can\'t find file %s" % (reader,readerTemplatePath)try:writerPar = readPluginTemplate(writerTemplatePath);except Exception, e:print "Read writer[%s] template error: : can\'t find file %s" % (writer,writerTemplatePath)jobTemplate['job']['content'][0]['reader'] = readerPar;jobTemplate['job']['content'][0]['writer'] = writerPar;print json.dumps(jobTemplate, indent=4, sort_keys=True)# 根据插件名读取插件模板
def readPluginTemplate(plugin):with open(plugin, 'r') as f:return json.load(f)# 判断入参是否为一个 url
def isUrl(path):if not path:return Falseassert (isinstance(path, str))m = re.match(r"^http[s]?://\S+\w*", path.lower())if m:return Trueelse:return False# 通过各类 if else 构建启动命令。启动命令中包含2部分 JVM参数+环境变量
def buildStartCommand(options, args):commandMap = {}tempJVMCommand = DEFAULT_JVMif options.jvmParameters:tempJVMCommand = tempJVMCommand + " " + options.jvmParametersif options.remoteDebug:tempJVMCommand = tempJVMCommand + " " + REMOTE_DEBUG_CONFIGprint 'local ip: ', getLocalIp()if options.loglevel:tempJVMCommand = tempJVMCommand + " " + ("-Dloglevel=%s" % (options.loglevel))if options.mode:commandMap["mode"] = options.mode# jobResource 可能是 URL,也可能是本地文件路径(相对,绝对)jobResource = args[0]if not isUrl(jobResource):jobResource = os.path.abspath(jobResource)if jobResource.lower().startswith("file://"):jobResource = jobResource[len("file://"):]jobParams = ("-Dlog.file.name=%s") % (jobResource[-20:].replace('/', '_').replace('.', '_'))if options.params:jobParams = jobParams + " " + options.paramsif options.jobid:commandMap["jobid"] = options.jobidcommandMap["jvm"] = tempJVMCommandcommandMap["params"] = jobParamscommandMap["job"] = jobResourcereturn Template(ENGINE_COMMAND).substitute(**commandMap)# 打印版权信息
def printCopyright():print '''
DataX (%s), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.''' % DATAX_VERSIONsys.stdout.flush()# 程序主入口
if __name__ == "__main__":# 1 打印版权信息printCopyright()# 2 获取选项的解析器parser = getOptionParser()# 3 根据入参,使用解析器解析出参数值# 3.1 parse_args方法返回俩参,分别为instance类型的options和list类型的args# 3.2 用sys.argv[1:]来获取命令参数,返回一个list类型的返回值options, args = parser.parse_args(sys.argv[1:])if options.reader is not None and options.writer is not None:# 4 如果解析后,入参的 reader和writer不为空,在从github上构建出一个 json的样例模板generateJobConfigTemplate(options.reader,options.writer)sys.exit(RET_STATE['OK'])if len(args) != 1:parser.print_help()sys.exit(RET_STATE['FAIL'])# 5 根据入参 构建执行脚本startCommand = buildStartCommand(options, args)# print startCommand 该命令可以打印出 用户输入的参数+py文件构建的参数,作为整体形成一个执行脚本。(执行脚本最后调用java类)# 6 创建并返回一个子进程,并在这个进程中执行指定的shell 脚本child_process = subprocess.Popen(startCommand, shell=True)# 7 将执行结果保存在信号量中register_signal()# 8 父子进程进行通信,并将通信结果保存到 stdout, stderr(stdout, stderr) = child_process.communicate()# 9 退出(根据子进程的状态码)sys.exit(child_process.returncode)注:
-
对源码进行略微改动,主要修改为 1 阿里代码规约扫描出来的,2 clean code;
-
所有代码都已经上传到github(master分支和dev),可以免费白嫖