参考几篇DRL调参技巧总结
https://zhuanlan.zhihu.com/p/345353294
https://zhuanlan.zhihu.com/p/434495366
1
增大batch size,减小样本误差
减小辅助reward,使其不影响最终reward,并使其正负均衡
辅助reward属于在每个step均出现,用于引导智能体不断接近得到最终reward,其主要设计原则有两个:
1>正负均衡,均负则智能体最终策略趋于保守,均为正则智能体最终策略,所以针对稠密的辅助reward值R_tAsst设计一定要正负均衡;
2>大小上不得影响最终reward值R_tfinal,即其值在经γ帖现因子乘积后值应不大于最终reward值,因此需要首先对完成步数进行估计即t_done,必须满足条件:R_tFinal > R_tAsst * (1 - γ)^ (t_done)
3> 辅助reward不可过大或过小,建议介于-1 到 +1之间,而最终reward可以设置在满足最小条件的同规模数据上。
加入SAC特有超参数奖励放缩 reward scale
经验上进行reward目标调整的值主要是将整个epsiode的累积收益范围落在-1000 ~ +1000以内
参数
hidden_dim = 128
batch_size = 128
replay_buffer_size = 3500
learn_rate = 0.0005
reward_scale = 0.5
奖励函数
# 鼓励晚上充电,白天放电if env.time_step % 24 == 0:#print('net_electric_consumption in one day ', sum(env.net_electric_consumption[-24:-1]))# 如果白天放电,reward_day = 0,否则为-300if np.array(action_day[0:20]).mean() > 0.0:reward_day = -30else:reward_day = 30# 如果夜晚充电,reward_day = 300,否则为-300if np.array(action_day[22:-1]).mean() > 0.1:reward_night = 30elif np.array(action_day[22:-1]).mean() < 0.0:reward_night = -30else:reward_night = 0reward = reward_scale * reward + reward_day + reward_night
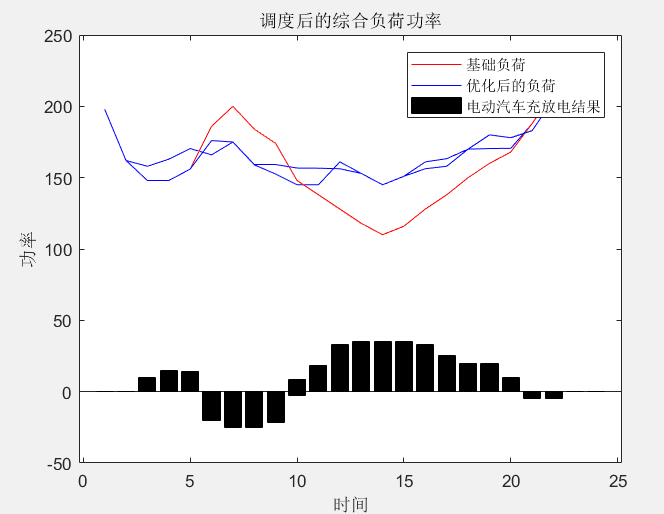
结果

2
注意到 输出action的范围是【-1,1】,但citylearn模型要求为[-1/c, 1/c],在模型相应位置修改
hidden_dim = 128
batch_size = 128
replay_buffer_size = 1440
learn_rate = 0.0003
reward_scale = 0.5
# 鼓励晚上充电,白天放电if env.time_step % 24 == 0:#print('net_electric_consumption in one day ', sum(env.net_electric_consumption[-24:-1]))# 如果白天放电,reward_day = 0,否则为-300if np.array(action_day[0:20]).mean() > 0.0:reward_day = -30else:reward_day = 30# 如果夜晚充电,reward_day = 300,否则为-300if np.array(action_day[22:-1]).mean() > 0.1:reward_night = 30elif np.array(action_day[22:-1]).mean() < 0.0:reward_night = -30else:reward_night = 0reward = reward_scale * reward + reward_day + reward_night#print('reward: ', reward)reward_epoch += reward_scale * reward #控制reward_epoch在-1000-1000之间

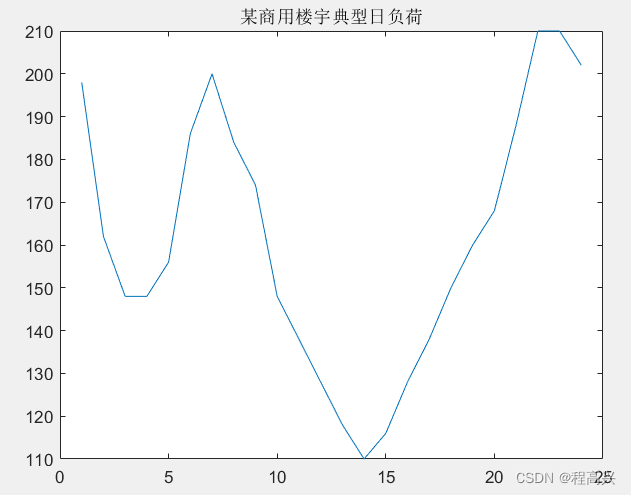
reward曲线未趋于平稳,且波动过大
3
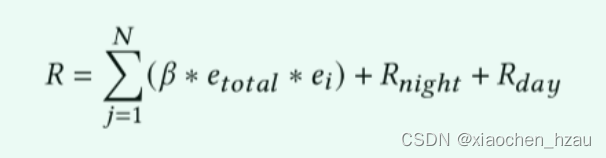
我们看到reward前面部分是电力需求的平方,对奖励函数做出同样修改
# 鼓励晚上充电,白天放电if env.time_step % 24 == 0:#print('net_electric_consumption in one day ', sum(env.net_electric_consumption[-24:-1]))# 如果白天放电,reward_day = 0,否则为-300if np.array(action_day[0:20]).mean() > 0.0:reward_day = -penaltyelse:reward_day = penalty# 如果夜晚充电,reward_day = 300,否则为-300if np.array(action_day[22:-1]).mean() > 0.1:reward_night = 2 * penaltyelif np.array(action_day[22:-1]).mean() < 0.0:reward_night = -penaltyelse:reward_night = 0reward = reward_scale * reward ** 2 + reward_day + reward_night# print('reward: ', reward)reward_epoch += reward # 控制reward_epoch在-1000-1000之间
参数
MAX_EPISODES = 100
sim_period = 720
reward_scale = 0.001
penalty = 4
hidden_dim = 128
batch_size = 128
replay_buffer_size = 3600
learn_rate = 0.00001
结果

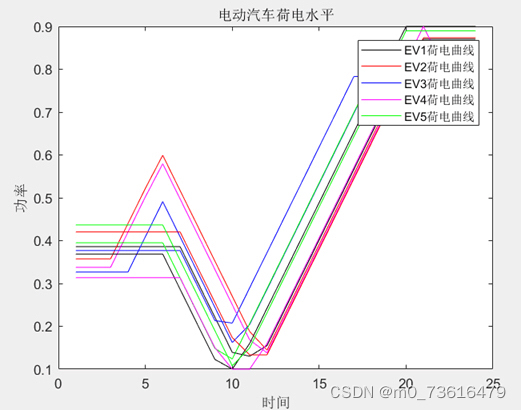
但在DQN上却效果还行

SAC中其他cost指标也没有变化

经检查,q_value_loss和value_loss数据一样
q_value_loss tensor(33.4076, device='cuda:0', grad_fn=<MseLossBackward0>)
value_loss tensor(33.4076, device='cuda:0', grad_fn=<MseLossBackward0>)