前言
一直在《深入理解JVM》对常量池只有一个浅薄的了解,之前也遇到过这种题目,今天还是要挑出来进行一次全方位的了解。
常量池分类
常量池大体可以分为:静态常量池,运行时常量池。
静态常量池 存在于class文件中,比如经常使用的javap -verbose中,常量池总是在最前面把?
运行时常量池呢,就是在class文件被加载进了内存之后,常量池保存在了方法区中,通常说的常量池 值的是运行时常量池。所以呢,讨论的都是运行时常量池
字符串常量池
最最最流行的、最典型的就是字符串了
典型范例:
String a = "abc";
String b = new String("abc");
System.out.println(a == b);----*----
结果:false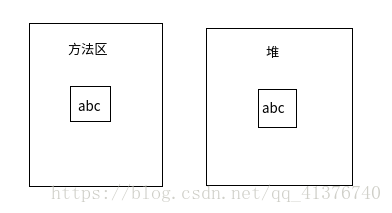
这个是第一个需要理解的地方,a指向哪片内存,b又指向哪片内存呢?对象储存在堆中,这个是不用质疑的,而a作为字面量一开始储存在了class文件中,之后运行期,转存至方法区中。它们两个就不是同一个地方存储的。知道了它之后我们就可以通过实例直接进一步了解了
实例
String s1 = "Hello";String s2 = "Hello";String s3 = "Hel" + "lo";String s4 = "Hel" + new String("lo");String s5 = new String("Hello");String s6 = s5.intern();String s7 = "H";String s8 = "ello";String s9 = s7 + s8;System.out.println(s1 == s2); // trueSystem.out.println(s1 == s3); // trueSystem.out.println(s1 == s4); // falseSystem.out.println(s1 == s9); // falseSystem.out.println(s4 == s5); // falseSystem.out.println(s1 == s6); // true分析:
1、s1 = = s2 很容易可以判断出来。s1 和 s2 都指向了方法区常量池中的Hello。
2、s1 = = s3 这里要注意一下,因为做+号的时候,会进行优化,自动生成Hello赋值给s3,所以也是true
3、s1 = = s4 s4是分别用了常量池中的字符串和存放对象的堆中的字符串,做+的时候会进行动态调用,最后生成的仍然是一个String对象存放在堆中。
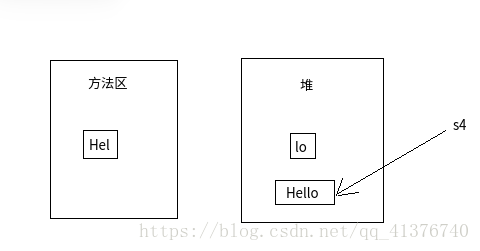
4、s1 = = s9 在JAVA9中,因为用的是动态调用,所以返回的是一个新的String对象。所以s9和s4,s5这三者都不是指向同一块内存

5、s1 = = s6 为啥s1 和 s6地址相等呢? 归功于intern方法,这个方法首先在常量池中查找是否存在一份equal相等的字符串如果有的话就返回该字符串的引用,没有的话就将它加入到字符串常量池中,所以存在于class中的常量池并非固定不变的,可以用intern方法加入新的
需要注意的特例
1、常量拼接
public static final String a = "123";public static final String b = "456";public static void main(String[] args){String c = "123456";String d = a + b;System.out.println(c == d);}------反编译结果-------0: ldc #2 // String 1234562: astore_13: ldc #2 // String 1234565: astore_26: getstatic #4 // Field java/lang/System.out:Ljava/io/PrintStream;我们可以发现,对于final类型的常量它们已经在编译中被确定下来,自动执行了+号,把它们拼接了起来,所以就相当于直接”123” + “456”;
2、static 静态代码块
public static final String a;public static final String b;static {a = "123";b = "456";}public static void main(String[] args){String c = "123456";String d = a + b;System.out.println(c == d);}------反编译结果-------3: getstatic #3 // Field a:Ljava/lang/String;6: getstatic #4 // Field b:Ljava/lang/String;9: invokedynamic #5, 0 // InvokeDynamic #0:makeConcatWithConstants:(Ljava/lang/String;Ljava/lang/String;)Ljava/lang/String;
上个例子是在编译期间,就已经确定了a和b,但是在这段代码中,编译期static不执行的,a和b的值是未知的,static代码块,在初始化的时候被执行,初始化属于类加载的一部分,属于运行期。看看反编译的结果,很明显使用的是indy指令,动态调用返回String类型对象。一个在堆中一个在方法区常量池中,自然是不一样的。
包装类的常量池技术(缓存)
简单介绍
相信学过java的同学都知道自动装箱和自动拆箱,自动装箱常见的就是valueOf这个方法,自动拆箱就是intValue方法。在它们的源码中有一段神秘的代码值得我们好好看看。除了两个包装类Long和Double 没有实现这个缓存技术,其它的包装类均实现了它。
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}private static class IntegerCache {
static final int low = -128;
static final int high;
static final Integer cache[];static {// high value may be configured by propertyint h = 127;String integerCacheHighPropValue =VM.getSavedProperty("java.lang.Integer.IntegerCache.high");if (integerCacheHighPropValue != null) {try {int i = parseInt(integerCacheHighPropValue);i = Math.max(i, 127);// Maximum array size is Integer.MAX_VALUEh = Math.min(i, Integer.MAX_VALUE - (-low) -1);} catch( NumberFormatException nfe) {// If the property cannot be parsed into an int, ignore it.}}high = h;cache = new Integer[(high - low) + 1];int j = low;for(int k = 0; k < cache.length; k++)cache[k] = new Integer(j++);// range [-128, 127] must be interned (JLS7 5.1.7)assert IntegerCache.high >= 127;
}private IntegerCache() {}
}分析:我们可以看到从-128~127的数全部被自动加入到了常量池里面,意味着这个段的数使用的常量值的地址都是一样的。一个简单的实例
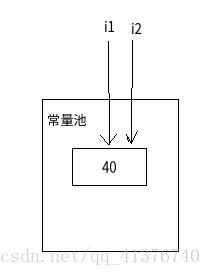
Integer i1 = 40;
Integer i2 = 40;
Double i3 = 40.0;
Double i4 = 40.0;System.out.println("i1=i2 " + (i1 == i2));
System.out.println("i3=i4 " + (i3 == i4));-----结果----
true
false原理如下:
1、== 这个运算在不出现算数运算符的情况下 不会自动拆箱,所以i1 和 i 2它们不是数值进行的比较,仍然是比较地址是否指向同一块内存
2、它们都在常量池中存储着,类似于这样
3、编译阶段已经将代码转变成了调用valueOf方法,使用的是常量池,如果超过了范围则创建新的对象
2: invokestatic #2 // Method java/lang/Integer.valueOf:(I)Ljava/lang/Integer;复杂实例[-128~127]
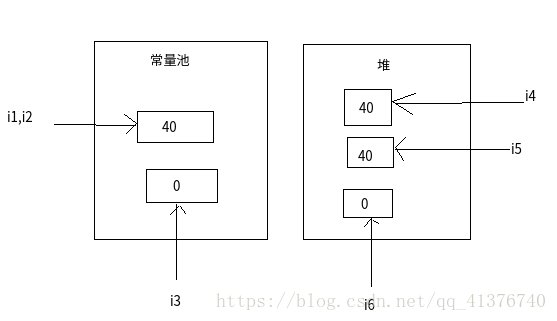
Integer i1 = 40;Integer i2 = 40;Integer i3 = 0;Integer i4 = new Integer(40);Integer i5 = new Integer(40);Integer i6 = new Integer(0);System.out.println("i1=i2 " + (i1 == i2));System.out.println("i1=i2+i3 " + (i1 == i2 + i3));System.out.println("i1=i4 " + (i1 == i4));System.out.println("i4=i5 " + (i4 == i5));System.out.println("i4=i5+i6 " + (i4 == i5 + i6));System.out.println("40=i5+i6 " + (40 == i5 + i6));----结果----
(1)i1=i2 true
(2)i1=i2+i3 true
(3)i1=i4 false
(4)i4=i5 false
(5)i4=i5+i6 true
(6)40=i5+i6 true它们的内存分布大概如下
注意点
1、当出现运算符的时候,Integer不可能直接用来运算,所以会进行一次拆箱成为基本数字进行比较
2、==这个符号,既可以比较普通基本类型,也可以比较内存地址看比较的是什么了
分析:
(1)号成立不用多说
(2)号成立是因为运算符自动拆箱
(3)(4)号是因为内存地址不同
(5)(6)号都是自动拆箱的结果
PS:equals方法比较的时候不会处理数据之间的转型,比如Double类型和Integer类型。
超过范围
假设一下,如果超出了这个范围之后呢?正如前文所言,所有的都将成为新的对象
Integer i1 = 400;Integer i2 = 400;Integer i3 = 0;Integer i4 = new Integer(400);Integer i5 = new Integer(400);Integer i6 = new Integer(0);Integer i7 = 1;Integer i8 = 2;Integer i9 = 3;System.out.println("i1=i2 " + (i1 == i2));System.out.println("i1=i2+i3 " + (i1 == i2 + i3));System.out.println("i1=i4 " + (i1 == i4));System.out.println("i4=i5 " + (i4 == i5));System.out.println("i4=i5+i6 " + (i4 == i5 + i6)); System.out.println("400=i5+i6 " + (400 == i5 + i6));----结果----
i1=i2 false
i1=i2+i3 true
i1=i4 false
i4=i5 false
i4=i5+i6 true
400=i5+i6 true总结
关于常量池部分的总结到这里,通过实际的例子和绘图来熟悉了下字符串常量池和包装类的常量池的使用。其中还包括了装箱和拆箱的小知识。收获还是丰厚的,终于明白了常量池的内容了。~happy-。-,如有笔误,还望纠正