一 ALSR介绍:
1.1定义
aslr是一种针对缓冲区溢出的安全保护技术,通过对堆、栈、共享库映射等线性区布局的随机化,通过增加攻击者预测目的地址的难度,防止攻击者直接定位攻击代码位置,达到阻止溢出攻击的目的的一种技术。如今Linux、FreeBSD、Windows等主流操作系统都已采用了该技术。
Linux
Linux已在内核版本2.6.12中添加ASLR。
Windows
Windows Server 2008,Windows 7,Windows Vista,Windows Server 2008 R2,默认情况下启用ASLR,但它仅适用于动态链接库和可执行文件。
Mac OS X
Apple在Mac OS X Leopard10.5(2007年十月发行)中某些库导入了随机地址偏移,但其实现并没有提供ASLR所定义的完整保护能力。而Mac OS X Lion10.7则对所有的应用程序均提供了ASLR支持。Apple宣称为应用程序改善了这项技术的支持,能让32及64位的应用程序避开更多此类攻击。从OS X Mountain Lion10.8开始,核心及核心扩充(kext)与zones在系统启动时也会随机配置。
iOS(iPhone, iPod touch, iPad)
Apple在iOS4.3内导入了ASLR。
Android
Android 4.0提供地址空间配置随机加载(ASLR),以帮助保护系统和第三方应用程序免受由于内存管理问题的攻击,在Android 4.1中加入地址无关代码(position-independent code)的支持。
1.2 基本思想
在传统的操作系统里,用户程序的地址空间布局是固定的,自低向高依次为代码区, BSS区,堆栈区,攻击者通过分析能轻易得出各区域的基地址,在此情况下,只要攻击者的 注入代码被执行,攻击者就能随意跳转到想到达的区域,终取得计算机的控制权,试想如 果一个程序在执行时,系统分配给此进程三个区域的基地址是随机产生的,每次该程序执行 都不一样,那么攻击者注入的代码即使被执行,也终会因为无法找到合法的返回地址而产 生错误,终进程停止,攻击者无法入侵,这就是地址空间布局随机化的基本思想。
在ASLR的实现中,系统将进程的 用户空间分为三个区域,可执行区,映射区和栈区,可执行区存放可执行代码,初始化数据 和未初始化数据,映射区包括堆,动态库和共享内存,栈区是用户态栈,当进程被创建时, 对于X86体系计算机,系统给每个区域一个随机的偏移量,分别为16位,16位和24位,其中 映射区偏移量称为delta-map,这样动态链接库的基地址就有65536种可能 ,当然这个数字应 该更大一些的,因为对于现代计算机而言,这实在不算一个很大的范围,但是对于32位的线 性地址来说,高四位为全局页表,如果用随机产生会影响对高位内存的映射能力,会产生大 量的内存碎片,低12位要考虑页对齐,因而只能有16位来作为偏移量,而在64位机上,则可 以有40位来产生delta-map,效率将大大提高 。
1.3 ASLR的问题
在出现了某些漏洞,比如内存信息泄露的情况下,攻击者会得到部分内存信息,比如某些代码指针。传统的ASLR只能随机化整个segment,比如栈、堆、或者代码区。这时攻击者可以通过泄露的地址信息来推导别的信息,如另外一个函数的地址等。这样整个segment的地址都可以推导出来,进而得到更多信息,如图2所示,大大增加了攻击利用的成功率。在32位系统中,由于随机的熵值不高,攻击者也容易通过穷举法猜出地址。
改进的方法:
- 随机化的粒度可以改进。粒度小了,熵值增加,就很难猜出ROP gadget之类的内存块在哪里。ASLP在函数级进行随机化,binary stirring在basic block级进行随机化,ILR和IPR在指令级。将指令地址进行随机化;而把指令串进行重写,来替换成同样长度,并且相同语义的指令串。
- 随机化的方式可以改进。Oxymoron解决了库函数随机化的重复问题:原先假如每个进程的library都进行fine-grained的ASLR,会导致memory开销很大。该文用了X86的segmentation巧妙地解决了这个问题;并且由于其分段特性,JITROP之类的攻击也很难有效读取足够多的memory。Isomeron[7]利用两份differentlystructured but semantically identical的程序copy,在ret的时候来随机化executionpath,随机决定跳到哪个程序copy,有极大的概率可以让JIT-ROP攻击无效。
- 随机化的时间(timing)可以改进。假如程序中存在能泄露内存的漏洞,那这种传统的、一次性的随机化就白费了。所以需要运行时动态ASLR。解决了fork出来的子进程内存布局和父进程一样的缺陷。其思路是在每次fork时都进行一次随机化。方法是用Pin进行taint跟踪,找到ASLR之后要修复的指针并进行修复。为了降低把数据当成指针的false positive,一个daemon进程会跑多次来提取出重合的部分。
1.2 缓冲区溢出原理
缓冲区是程序运行时计算机内存中的一块连续的地址空间,它用于保存给定类型的数 据。在一些高级语言的函数调用中,缓冲区是在堆栈上进行分配的。堆栈是一个后进先出的 队列,它的生长方向与内存的生长方向正好相反。具体如图所示
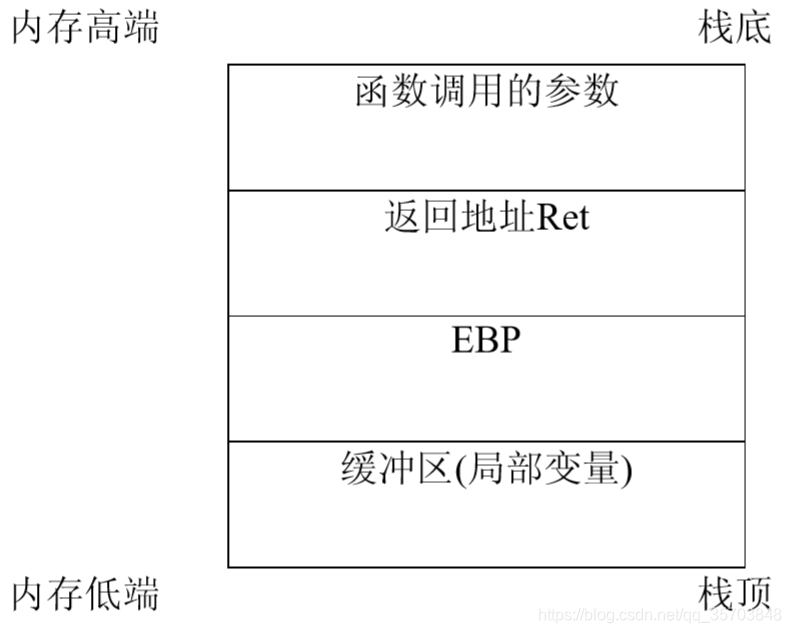
在正常情况下,处理器在函数调用时,将函数的参数、返回地址(即进行函数调用的那 条指令的下一条指令的地址)及基址寄存器EBP(该寄存器存储的内存地址为函数在参数和 变量压栈之前的内存地址)压入堆栈中,然后把当前的栈指针(ESP)作为新的基地址。如果 函数有局部变量,则函数会把堆栈指针ESP 减去某个值,为需要的动态局部变量腾出所需的内存空间,函数内使用的缓冲区就分配在腾出的这段内存空间上。函数返回时,弹出EBP 恢复堆栈到函数调用前的地址,弹出返回地址到EIP 以继续执行原程序。假设程序从攻击者处接收一长度超过缓冲区长度的字符串, 则会出现安全漏洞。由于堆 栈的生长方向与内存的生长方向正好相反, 如果接收的是超长字符串,EBP 和EIP 的值就 有可能被覆盖。一般情况下,会导致程序运行失败,但如果覆盖EIP 的值刚好是攻击代码的 内存地址,从而控制了程序的运行权,程序将自动跳转到攻击代码的位置,开始执行写 好的攻击代码,从而达到攻击的目的。这就是缓冲区溢出攻击的原理。
1.2.1缓冲区溢出的防御现状
目前堆溢出攻击的方法分为四种主要类型。 1 编写安全的代码与代码审查在, 包括使用 安全的编程语言, 静态代码审查和动态代码审查等; 2 编译器修改在, 包括数组边界检查与 关键数据完整性检查;3 库函数修改,主要针对malloc 库溢出,修改分配和释放的内存块的布局;4 操作系统与硬件修改,通过不执行内存和随机化指令集与地址来防止堆溢出 。
- 编写安全的代码与代码审查 :已有的防范方法中较早的一种就是针对C 中的如strcpy( ) 、sprintf( ) 等库函数不进行 边界检查来进行的。这些库函数很多以“null”为字符串的结束标志, 对输入字符串的长度不 做检查, 这样导致了缓冲区溢出的第一步的实现成为可能。这类防范方法的一个简单的思路 就是培训程序员, 让他们编写安全的代码, 避免在程序的编写中使用这样的函数, 反过来使 用如strncpy( ) 、snprintf( ) 等替换的版本。静态代码审查则是通过半自动或自动工具, 对已 有的代码进行审查, 发现代码中可能存在的缓冲区溢出漏洞, 报告给程序员修改。很多安全 编程语言自身的特性可以防止缓冲区的溢出, 如类型安全语言Java、ML 等, Kowshik 的 Control- C则通过限制在数组和指针上的操作提供边界安全, 其他还有如Trevor Jim等的 Cylone, George Necula 的CCured等。程序员应尽可能使用这些安全编程语言 。
- 编译器修改 :无论堆溢出还是栈溢出, 根本原因是缓冲区的越界访问,通过编译器修改对每个数组进 行边界检查, 使得缓冲区根本无法溢出, 则能完全地避免该漏洞和溢出攻击。典型成果 有:Compaq C Compiler, Jones & Kelly 的Array Bounds Checkingfor C等。关键数据完整性检 查则试图保护如栈帧返回地址和指针等关键数据, 确保完整性检查在程序关键数据被引用 之前检测到它的改变。因此, 即便一个攻击者成功地改变程序的指针, 也会由于系统事先检 测到了指针的改变, 这个指针将不会被使用。与数组边界检查相比, 这种方法不能解决所有 的缓冲区溢出问题; 但是在性能上有很大的优势, 而且兼容性也很好。
- 库函数修改 :由于动态内存分配函数是作为库实现的, 程序对这些函数的调用是动态加载的。可以利 用库函数修改方法来保护dlmalloc等库的内存管理信息, 防止malloc 库攻击。William Robertson 等人提出在内存块( chunks) 的头部添加校验和, 在释放内存块之前进行校验和 验证的方法来确保内存块的内存管理信息没有被更改。glibc 2.3.5 引入的防止malloc 库攻击 的新安全特性就借鉴了这种方法。
- 操作系统与硬件修改: 一些硬件与操作系统修改的方法同样用来防止堆溢出等缓冲区溢出, 如设置不可执行 的缓冲区( 堆或栈) 防止攻击者执行注入的代码, 加密指令集使得攻击者在注入代码时很难 猜测指令正确的机器码表示。通过栈不可执行( 如Solar Designer 在IA32 体系上的Linux实 现) 可以有效防止一部分基于栈的缓冲区溢出攻击。Pax则是一个Linux 内核补丁, 它通过不 可执行页实现了不可执行栈和不可执行堆,不可执行缓冲区对于需要注入可执行代码这类攻 击的防范是高效的, 但对Return- into- libc 攻击则毫无办法。
二 ALSR的验证
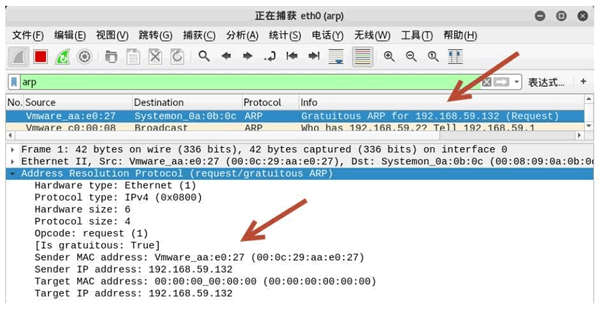
2.1 查看当前操作系统的ASLR配置情况
![]()
说明:
- 0 = 关闭
- 1 = 半随机。共享库、栈、mmap() 以及 VDSO 将被随机化。
- 2 = 全随机。
2.2 查看动态库的命令
ldd命令用于判断某个可执行的 binary 档案含有什么动态函式库。(ldd本身不是一个程序,而仅是一个shell脚本)
参数说明:
- --version 打印ldd的版本号
- -v --verbose 打印所有信息,例如包括符号的版本信息
- -d --data-relocs 执行符号重部署,并报告缺少的目标对象(只对ELF格式适用)
- -r --function-relocs 对目标对象和函数执行重新部署,并报告缺少的目标对象和函数(只对ELF格式适用)
ALSR开启状态下执行命令:(开启状态下两此加载地址不同)
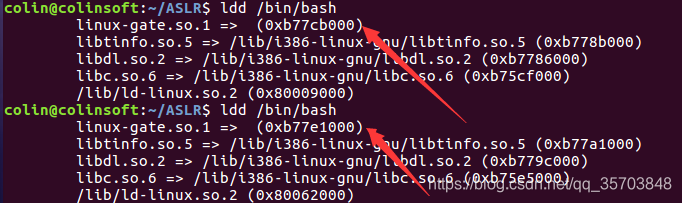
ALSR关闭状态下执行命令:(关闭状态下两次加载地址相同)
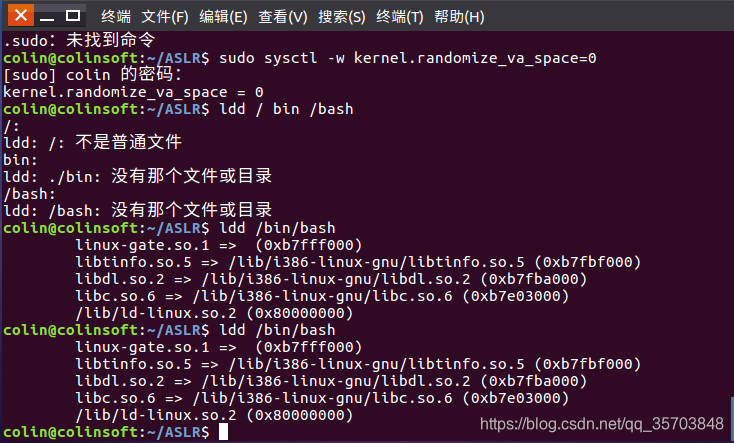
2.3 ALSR攻击
#include <stdio.h>
#include <string.h>void copyStr(char* str){char buffer[8];strcpy(buffer, str);
}void skill() {char *show = "你的电脑中毒了!请复制一下秘钥";char arr[7] = {0x44, 'S', 'A', 'M', 'S', 'o', 'n'};printf("%s", show);printf("%s\n", arr);
}int main() {//printf("skill =%p\n", &skill);char* input = "AAAAAAAAAAAAAAAAAAAAAAAA\x44\x84\x04\x08";copyStr(input); return 0;
} 上述代码有明显的字节溢出问题,str的字节最多拷贝8个字节很明显字节溢出。我们看到skill地址开始在0x8048444,字符数组溢出后,从文件读取的内容会在当前栈帧沿着高地址覆盖,而该栈帧的顶部存放着返回上一个函数的地址(EIP),只要我们覆盖了该地址,就可以修改程序的执行路径。由于我们希望有效负载覆盖返回地址,4个字节来替换旧的%ebp和以及目标地址。
注:查看eip的地址可以使用gdb的调试模式:(gdb) info register esp;。
也可以通过计算缓冲区的大小,加上RIP的地址大小,我们在这个位置上就可以执行自己的函数。