-
-
- 神经网络通过记忆学习
- 传统观点
- 论文观点
- 论文实验
- 神经网络 不 通过记忆学习
- 参考资料
- 神经网络通过记忆学习
-
深度神经网络往往带有大量的参数,但依然表现出很强的泛化能力(指训练好的模型在未见过的数据上的表现)。
深度神经网络为何会拥有如此强的泛化能力?最近,两篇论文引起了广泛思考。
神经网络通过记忆学习
《Understanding deep learning requires rethinking generalization》一文通过实验得出初步结论:
神经网络极易记忆训练数据,其良好的泛化能力很可能与此记忆有关。
传统观点
传统方法认为模型对训练数据的记忆是导致泛化能力差的重要原因,因此往往通过各种各样的正则化手段使得模型“简约”,从而打破这种记忆。
论文观点
深度神经网络极易记忆数据,常用的正则化手段对于模型泛化能力的提高不是必要的而且也不足以控制泛化误差。深度神经网络发挥作用时可能很好的利用了其记忆能力。
论文实验
论文通过大量试验挑战了传统机器学习的观点。
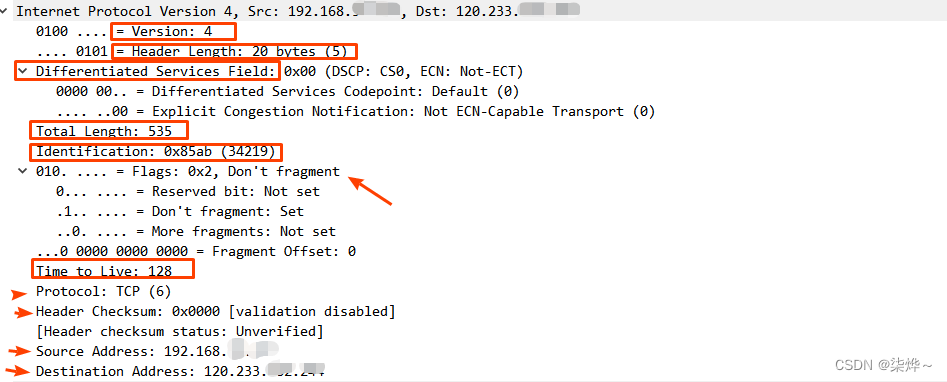
实验一:如下图

上图的实验结果是:哪怕是随机的label、随机的噪声,神经网络也能获得零训练误差。虽然训练时间变长,测试误差也变高。因此,作者得出了结论:神经网络极易记忆数据,其泛化能力很可能与记忆有关。
我的看法: 作者试验中保证网络参数量大于数据量的2倍,如此巨大的网络能够记忆训练数据似乎一点也不让人惊奇。作者用零训练误差来表示网络记忆了数据,但对于正确label和随机label而言,同样的零训练误差可能代表完全不同形式的“记忆”,因此不能简单就说明神经网络的能力和记忆有关。
实验二:如下表

上表试图比较说明三种类型的显式正则化:data augmentation, weight decay and dropout的效果。 结论是:这些正则化手段虽然有助于减小泛化误差,但即使没用这些手段,模型依然可以比较好的泛华。即正则化不是模型泛化的根本原因。
神经网络 不 通过记忆学习
《DEEP NETS DON’T LEARN VIA MEMORIZATION》
文章结论:深度神经网络的性能并非来自“记忆”, 而是源于在有限数据上学习简单的、切合的可用假设。
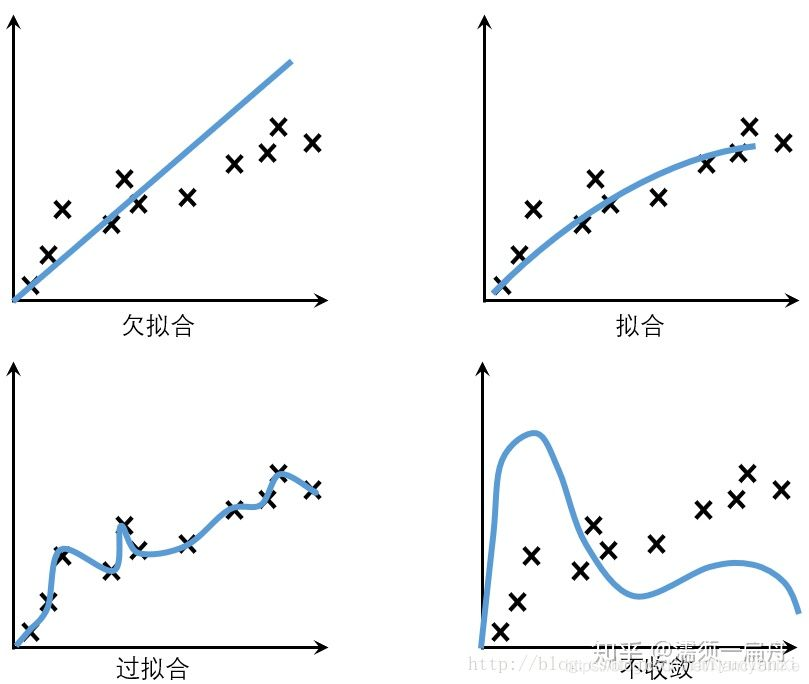
实验一:如下图

实验现象:对于真实数据,网络可以用较少的参数获得较好的性能;对于噪声,则需要增加网络容量。
结论: 这暗示网络是在学习某种“模式”,而不是简单的暴力记忆。
实验二:如下图

实验现象:减小网络容量或者增加数据集的大小会使网络收敛速度变慢,但这一现象对真实数据并不明显。
结论: 这暗示网络是在学习某种“模式”,而不是简单的暴力记忆。(否则的话,样本增多,训练速度应该变慢很多。)
未完待续:
参考资料
[1] 新智元文章:【Bengio vs 谷歌】深度学习兄弟对决,神经网络泛化本质之争:http://it.sohu.com/20170219/n481116059.shtml
[2] Reddit评论: https://www.reddit.com/r/MachineLearning/comments/5cw3lr/r_161103530_understanding_deep_learning_requires/
[3] ICLR 论文公开评审:https://openreview.net/pdf?id=rJv6ZgHYg