我们知道模型的泛化能力是很重要的,如果一个模型具有很好的泛化性能,那么它往往能够在没有见过的数据上表现良好。以中文命名实体识别为例,在用于评估模型泛化性能的数据集中,我们可能忽略了数据偏差对模型泛化的影响。
论文标题:
Improving Model Generalization: A Chinese Named Entity Recognition Case Study
论文链接:
https://aclanthology.org/2021.acl-short.125.pdf

通过分析五个中文NER的基准数据集后,作者观察到两种可能影响模型泛化能力的数据偏差。首先,所有这五个数据集中的测试集都包含了很大一部分在训练集中已经见过的实体(占比可达到50%-70%),因此这些测试数据不适合评估模型处理看不见数据的能力;其次,所有数据集都由少数fat-head实体主导,即出现频率特别高的实体,因此,模型可能只是通过关键字记忆就能够产生高预测精度,其基本原理是,给定相同的实体和上下文,模型收敛的最简单方法是记住实体,而不是从不同的上下文中提取模式。为了解决上述数据偏差问题,作者提出将测试集中的可见实体排除以改善测试集,然后通过提出的一种简单有效的实体重新平衡方法,让同一类型中的实体平均分布,从而鼓励模型在训练过程中利用名称和上下文知识。
实体重新平衡算法
为了提高模型在检测看不见的实体的泛化能力,作者认为应该在训练模型时把名称和上下文知识利用起来,因此提出一种简单有效的实体重新平衡算法,其主要思想是使标注的实体在同一类别内平均分布。提出的实体重新平衡算法有效的主要原因有两个。首先,平均分布将鼓励模型同时利用名称知识和上下文知识,因为由于分布不均,没有简单的统计线索可供利用。其次,在大多数情况下,同一类别内的不同实体在语义上应该是可互换的,从而避免了训练与测试的差异。
所提出的算法的工作原理如下。首先,重新平衡训练数据中标注的实体频率,让表示类别的原始实体频率计数,例如给定计数器={,,},其表示实体被标注了11次,实体e1和e2被标注了1次,然后将转变成平衡的实体频率计数器={, , },在中最大和最小实体频率之差最多为1。一旦fat-head实体累计出现次数超过中的重新平衡频率,用同类别的随机采样实体替换fat-head实体,具体算法细节如下:

实验/结果
由于在测试数据集中有很大一部分在训练集中出现过的可见实体,为了更好的评估模型的泛化能力,将测试集中的这部分可见实体排除,作者以BERT-CRF模型架构对比了一些复杂的SOTA模型,结果如下图所示:
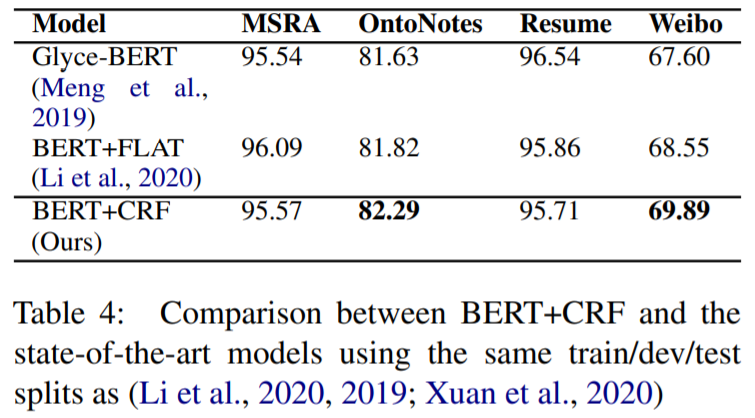
可以看到作者的方法在两个数据集上有比较明显的提升。进一步的,作者将所提方法和baseline在五个数据集上类别层面的性能比较。其中baseline使用原始的训练数据,所提方法使用应用了实体重新平衡算法的训练数据。(注:有些数据实体类别缺失是因为在这些类别上的未见实体为0或很少)
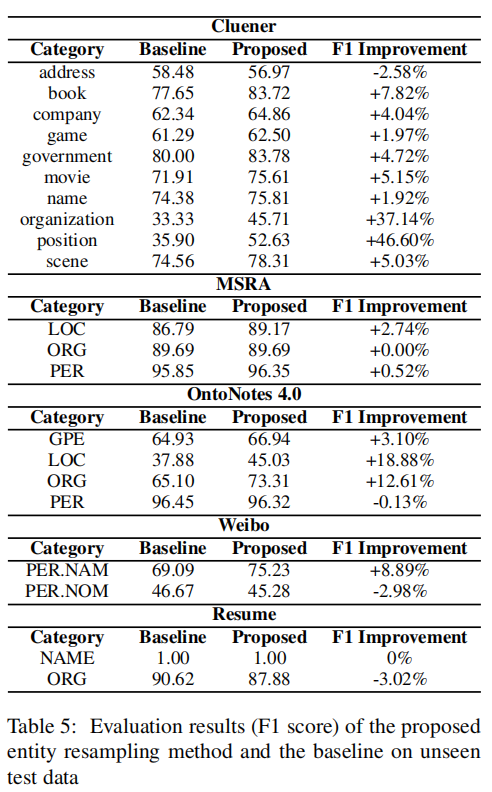
总的来说,作者所提方法在MSRA、OntoNotes、Cluener三个数据集上都表现良好,除了在Cluener的地址类别实体上降低了2.58%,作者认为这是因为地址类别包含地缘政治实体和位置实体,它们在语义上不可互换。在Weibo数据集上PER.NAM类别实体相比baseline提高了8.89%,然而在PER.NOM类别实体上降低了2.98%,注意到PER.NOM类别包含诸如男人、女人和朋友之类的实体,这些实体很难根据上下文知识进行概括。在Resume数据集上表现不佳,作者认为这是因为Resume语料库的结构特点导致可以利用的上下文知识很少。
小结
总而言之,作者所提方法能够提高模型检测未见实体的泛化能力,但是这种方法仅适用于满足特定条件的类别:
1)同一类别的实体需要在语义上可互换
2)实体应该依赖于上下文知识。
END

往期精彩回顾适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载机器学习的数学基础专辑黄海广老师《机器学习课程》视频课本站qq群851320808,加入微信群请扫码: