原文:Efficient Multiple Feature Fusion With Hashing for Hyperspectral Imagery Classification: A Comparative Study
面向高光谱图像的多特征融合哈希
- I. Introduction
- II. MFH Framework
- III. Feature Hashing
- IV. Experiment Setting
- A. Data Sets
- B. Multiple Feature Extraction
- C. EvaluatedMethods
- D. Evaluation Criterion
- V. Results and Analysis
- A. Experiment 1: Indian Pines Data Set
- B. Experiment 2: University of Pavia Data Set With Given Training Samples
- C. Experiment 3: Salinas Data Set
- D. Experiment 4: Houston Data Set With Given Training Samples
- VI. Disscussion
- VII. Conclusion And Feature Works
I. Introduction
The existing methods for multiple feature fusion are mainly
focused on improving their classification accuracy without con- sidering the computational and storage cost. However,
动机:现存多特征融合方法主要致力于提高分类精度,没有考虑计算和存储开销。
As a powerful technique to obtain compact features and fast nearest neighbor search, hashing has not been introduced in remote sensing processing until very recently, where it is adopted for large-scale remote sensing image retrieval. To the best of our knowledge, it has not been used in hyperspectral image classification.
哈希作为一种获取紧凑特征和快速近邻搜索的强大技术,直到最近才被引入到遥感处理中,被用于大规模遥感图像检索。据我们所知,它还没有被用于高光谱图像的分类。
The main contributions of our work are summarized as follows.
- We propose an MFH framework to use hash technique in fusing multiple features for hyperspectral image classification and show encouraging results.
- We conduct an extensive performance evaluation of different hashing methods on fusing multiple features for classification on four popular hyperspectral data sets. Based on the evaluation results, we supply with an indepth discussion on the advantages, disadvantages, and availability of different hashing methods in this task.
- We conduct comparative experiments with five classical subspace-based dimension reduction methods and six different multiple feature fusion methods. Experiments show that, when equipped with a proper hashing learning strategy, the proposed MFH method can achieve comparable or even competitive performance. Meanwhile, the obtained binary features require much less storage and classification time.
本文的主要贡献如下:
- 提出了一种MFH(Multiple feature Fision Hashing)框架,将哈希技术引用到多特征融合的高光谱图像分类中;
- 在4个流行高光谱数据集上进行了性能评估,探讨哈希方法在本课题中的优缺点;
- 对五种经典的基于子空间的降维方法和六种不同的多特征融合方法进行了对比实验。
II. MFH Framework
The proposed MFH framework can be divided into three steps: 1) perform feature extraction in the hyperspectral image via efficient approaches, and concatenate multiple features into a long feature vector for each pixel; 2) perform hashing learning on these feature vectors with or without class label information, and map the original float-type feature vectors into compact binary codes; and 3) perform classification with the obtained binary codes, and output the final classification results. The flowchart of MFH is shown in Fig. 1.
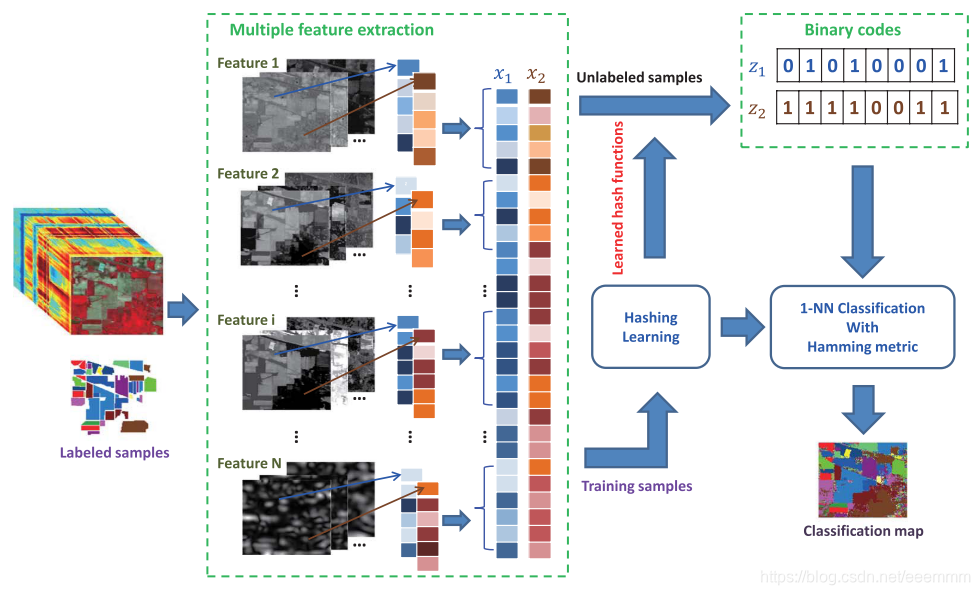
MFH框架分为三个步骤:
- 对高光谱图像进行特征提取,并将每个像素的多个特征拼接成一个长特征向量;
- 对特征向量进行哈希学习,将浮点特征映射为二进制哈希码;
- 利用得到的哈希码进行分类,输出分类结果。
MFH方法简单地将多特征拼接,它忽略了不同视图之间的潜在相关性。
III. Feature Hashing
本节介绍了几个代表性监督和非监督的哈希算法。
(1)无监督哈希
- LSH
- KLSH
- SH
(2)监督哈希
- KSH
- FastHash
- CCA-Based ITQ:当标签信息可用时,可以用典型相关分析(CCA)[46]代替PCA,从而产生基于CCA的ITQ算法(CCA-ITQ)。如[45]所示,CCA-ITQ是非常有效的,可以显著提高图像检索的性能。
[45] Y. Gong and S. Lazebnik, “Iterative quantization: A Procrustean approach to learning binary codes,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2011, pp. 817–824.
[46] H. Hotelling, “Relations between two sets of variates,” Biometrika, vol. 28, no. 3/4, pp. 321–377, Dec. 1936.
IV. Experiment Setting
A. Data Sets
Indian Pines: This data set was captured by the Airborne Visible/Infrared Imaging Spectrometry (AVIRIS) sensor over a mixed agricultural/forested region in Northwest Indiana, on June 12, 1992. This data set has a spatial size of 145×145 pixels and 220 spectral bands with a spatial resolution of 20 m/pixel. It has 16 land-cover classes, whose sizes of labeled samples disproportionately range from 20 to 2468 pixels. In the experi- ments, we remove 20 noisy bands (104–108, 150–163, and 220) due to water absorption and use the remaining 200 bands.
Indian Pine :该数据集具有145*145像素的空间大小和220个光谱波段,空间分辨率为20m/piexl。该数据集包含16个土地覆盖类别,可用于分类的样本分布极不均匀,数量从20到2468个不等。实验中去掉了20个(104-108,150-163和220)被水吸收的噪声频段,使用了剩下的200个频段。
University of Pavia: This data set was acquired by the Reflective Optics System Imaging Spectrometry (ROSIS), covering an urban area of the University of Pavia, Italy. Originally, the ROSIS sensor provided 115 bands from 0.43 to 0.86 μm. After removing the 12 most noisy bands, the remaining 103 bands are used for experiments. The spatial size of this data set is 610 × 340 pixels, and its spatial resolution is 1.3 m/pixel. There are 9 classes, with sizes of labeled samples ranging from 1026 to 18686.
University of Pavia:该数据集包含115个波段,去除12个噪声最大的波段后,剩下的103个波段用于实验。该数据集的空间大小为610*340像素,空间分辨率为1.3m/pixel。包含9个类别,样本像素数量从1026到18686个不等。
Salinas: This data set was captured by the AVIRIS sensor over Salinas Valley, CA, USA, with a spatial resolution of 3.7 m/pixel. This data set has a spatial size of 512 × 217 with 224 spectral bands. In our experiments, 20 water absorption bands (108–112, 154–167, and 224) are discarded. This data set has 16 classes, whose sample sizes range from 916 to 11271.
Salinas:该数据集空间分辨率大小为3.7m/pixel,包含有224个波段,空间大小为512*217的像素。实验中忽略了20个被水吸收的波段(108–112, 154–167和224)。该数据集包含16个类别,样本像素数量从916到11271个不等。
Houston: This data set was initially distributed in the 2013 IEEE Geoscience and Remote Sensing Data Fusion Contest, which includes an urban hyperspectral data set and light detection and ranging (LiDAR) derived digital surface model. Both are geographically referenced and at the same spatial resolution (2.5 m). The hyperspectral data set has 144 bands in the 380–1050-nm spectral region. There are 15 classes of interest selected by the organizers.
Houston:该数据集包括一个城市高光谱数据集和一个由光探测和测距(LiDAR)得出的数字地表模型。两者的空间分辨率均为2.5m/pixel。高光谱数据集在380-1050 nm的光谱区域中有144个波段。实验中选取了15个感兴趣的类别。
B. Multiple Feature Extraction
Four kinds of commonly used features in hyperspectral image processing are extracted for each pixel, including the following: 1) the original spectral feature (denoted as Spectral); 2) the EMP feature (denoted as EMP) [19]; 3) the EAP feature (denoted as EAP) [20], [21]; and 4) the Gabor filtering feature (denoted as Gabor).
对于每个像素,实验提取了高光谱图像处理中常用的四种特征,包括:
- 原始光谱特征(Spectral),记为 x s p e ∈ R d 1 x_{spe}\in\mathbb{R}^{d_1} xspe∈Rd1,其中 d 1 d_1 d1为高光谱图像的波段数。
- 扩展的形态学剖面(EMP),记为 x e m p ∈ R d 2 x_{emp}\in\mathbb{R}^{d_2} xemp∈Rd2。
- 扩展形态学属性剖面(EAP),记为 x e a p ∈ R d 3 x_{eap}\in\mathbb{R}^{d_3} xeap∈Rd3。
- Gabor滤波特征(Gabor),记为 x g a b o r ∈ R d 4 x_{gabor}\in\mathbb{R}^{d_4} xgabor∈Rd4。
提取了这些特征后,简单地将它们连接成一个融合的高维多个特征向量 x m u l t i = [ x s p e , x e m p , x e a p , x g a b o r ] ∈ R 1 × D ( D = ∑ k = 1 4 d k ) x_{multi}=[x_{spe},x_{emp},x_{eap},x_{gabor}]\in\mathbb{R}^{1\times D}(D=\sum_{k=1}^4d_k) xmulti=[xspe,xemp,xeap,xgabor]∈R1×D(D=∑k=14dk),并将他们作为后续哈希学习的输入。
C. EvaluatedMethods
本文选取了6种代表性的哈希方法:包括3种非监督方法(LSH、KLSH、SH)和3种监督的方法(KSH、CCA-ITQ、FastHash)进行对比实验。
【其他方法与我的工作无关略过了】
在性能评估中,对于基于哈希的方法,所获得的哈希码被作1-NN分类器的输入进行分类。哈希码的长度为[8,16,32,48,64]。
在处理所之前,将所有特征线性归一化为[0,1]。
D. Evaluation Criterion
对于分类性能的评估度量,本文报告了:
- 总体准确率(OA),即分类正确的样本的数量除以测试样本的数量;
- kappa统计量( κ \kappa κ),用于一致性检验和衡量分类的效果;
- 每类分类精度。
分类问题中,最常见的评价指标是acc,它能够直接反映分正确的比例,同时计算非常简单。但是实际的分类问题种,各个类别的样本数量往往不太平衡。在这种不平衡数据集上如不加以调整,模型很容易偏向大类别而放弃小类别(eg: 正负样本比例1:9,直接全部预测为负,acc也有90%。但正样本就完全被“抛弃”了)。此时整体acc挺高,但是部分类别完全不能被召回。
原文链接:Kappa系数简介
除了分类准确率外,本文还报告了运行时间。对于每种方法,实验记录了三种类型的计算时间,包括:
- 学习哈希函数的训练时间,以秒为单位;
- 从串联的多个特征中提取哈希码的时间,以微秒为单位;
任意两个特征(浮点型向量或二进制码)之间距离计算的平均时间,以纳秒为单位。
V. Results and Analysis
A. Experiment 1: Indian Pines Data Set
该数据集有16个类别,主要由农业土地覆盖类别组成。对于每一类,随机选取50个样本作为训练集,其余样本作为测试集。对于样本少于50个的类,随机选取15个样本作为训练集。
重复十次,并记录平均结果及其标准偏差。
多特征提取为: x s p e ∈ R 200 x_{spe}\in\mathbb{R}^{200} xspe∈R200, x e m p ∈ R 45 x_{emp}\in\mathbb{R}^{45} xemp∈R45, x e a p ∈ R 180 x_{eap}\in\mathbb{R}^{180} xeap∈R180,
x g a b o r ∈ R 40 x_{gabor}\in\mathbb{R}^{40} xgabor∈R40, x m u l t i = [ x s p e , x e m p , x e a p , x g a b o r ] ∈ R 1 × 465 x_{multi}=[x_{spe},x_{emp},x_{eap},x_{gabor}]\in\mathbb{R}^{1\times 465} xmulti=[xspe,xemp,xeap,xgabor]∈R1×465
部分实验结果如下:

从表1可以看出,监督哈希方法(KSH、CCA-ITQ和FastHash)与原始的MultiFeature方法相比,显著提高了分类精度,并且FastHash在该数据集上取得了最好的结果。
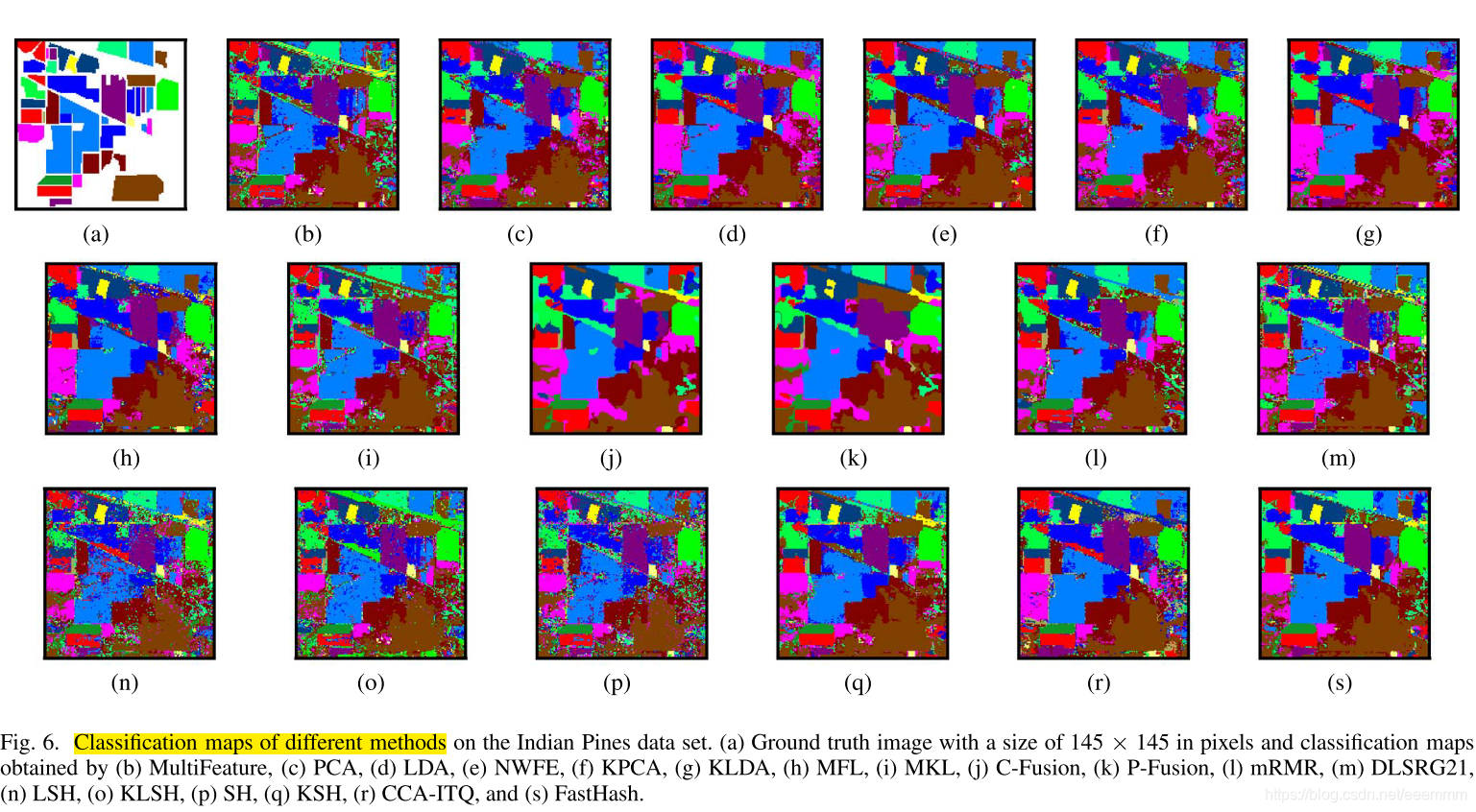
图6说明了通过不同方法获得的分类图。可以看出,对于这些特征哈希方法,可以观察到FastHash可以获得非常令人满意的分类映射,与LDA或KLDA得到的分类映射非常相似。这表明哈希码可以在保持紧凑性的同时保持原始浮点型表示之间的语义相似性。此外,有监督哈希方法比无监督哈希方法获得了更平滑的分类图。
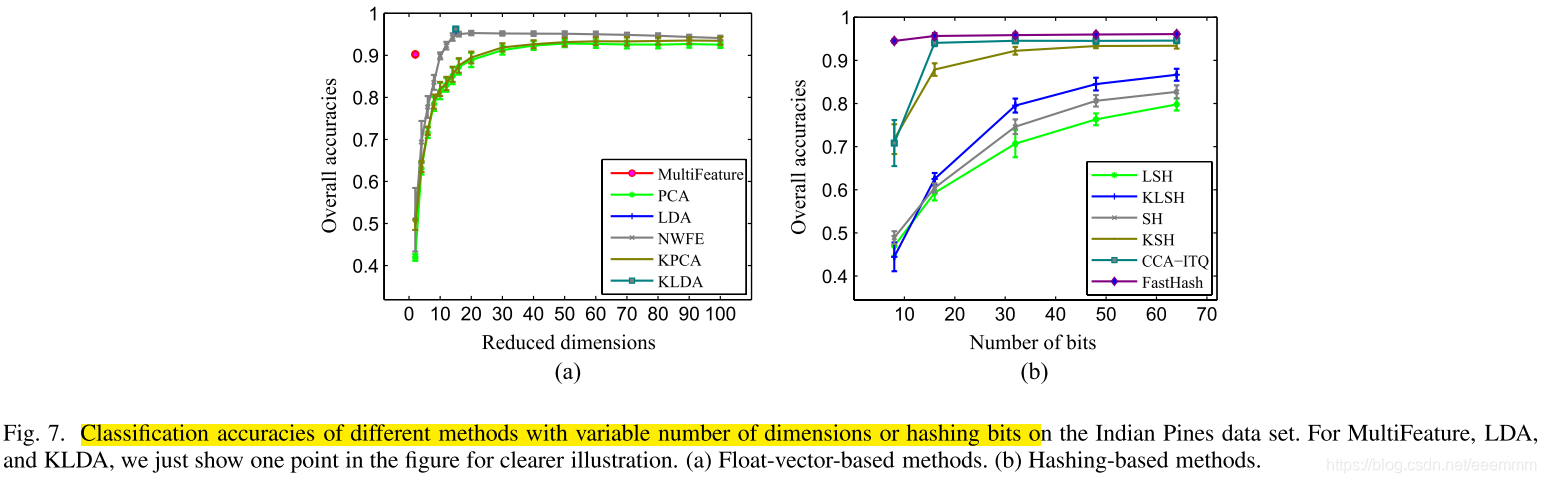
图7(B)展示了具有不同比特数的哈希方法的分类性能。值得注意的是,FastHash和CCA-ITQ在只有16位时就能表现得相当好。对于其他哈希方法,最多64位就足以获得令人满意的性能。
B. Experiment 2: University of Pavia Data Set With Given Training Samples
略
C. Experiment 3: Salinas Data Set
略
D. Experiment 4: Houston Data Set With Given Training Samples
略
VI. Disscussion
实验结构表明哈希方法生成的二进制码可以保留原始数据空间中的相似性。同时,紧凑的哈希码码还可以方便更快的后续处理和经济的存储。
VII. Conclusion And Feature Works
In this paper, we have proposed an MFH framework and have given a comparative evaluation on several existing hashing methods for hyperspectral imagery classification. The main characteristics of this work lie in the following aspects. First, the hashing technique has been introduced into multiple feature fusion for generating compact binary feature representation. Second, the classification experiments conducted on four real hyperspectral data sets have demonstrated that the obtained compact binary codes cannot only preserve similarity in the original data space but also allow more economical subsequent processing and meanwhile can achieve a comparable or better performance. Finally, along with the powerful features ex- tracted on hyperspectral images, the feature hashing in multiple feature fusion is very effective and efficient as expected.
As future work, more investigations on the MFH can bemainly explored in two aspects: theory and application. From the perspective of theory, the first improvement is to propose more flexible fusion schemes to take advantage of comple- mentary but vital information from multiple types of features. Another possible improvement is to develop more efficient hashing methods to obtain more compact and discriminative binary codes. From the viewpoint of application, with the greater development of imaging technologies, large volumes of huge data in remote sensing have been captured and stored. How to effectively and efficiently explore the large-scale big remote sensing data urgently needs to be studied. One possible application is remote sensing data compression. With the effi- cient MFH, the large-scale data can be compressed into binary codeswithout significant loss of information,which will largely reduce the storage amount. Another possible exploration is fast retrieval for the near-duplicate spectrum or similar objects. Owing to the compact binary codes, the nearest neighbor search or approximate nearest neighbor search would be very efficient, thus largely decreasing the time complexity.
本文提出了一种MFH框架,并对现有的几种用于高光谱图像分类的哈希方法进行了比较评价。这项工作的主要特点在于以下几个方面。首先,将哈希技术引入多特征融合,生成紧凑的二值特征表示。其次,在四个真实的高光谱数据集上进行的分类实验表明,所得到的紧凑二进制码不仅可以保持原始数据空间的相似性,而且可以进行更经济的后续处理,同时可以获得与之相当或更好的性能。最后,结合高光谱图像提取的强大特征,多特征融合中的特征哈希是非常有效和高效的。
在今后的工作中,可以主要从理论和应用两个方面对MFH进行更多的研究。从理论上讲,第一个改进是提出了更灵活的融合方案,充分利用了多种特征的重要信息。另一个可能的改进是开发更有效的哈希方法以获得更紧凑和更具区分性的二进制码。从应用的角度看,随着成像技术的不断发展,大量的遥感海量数据被捕获和存储。如何有效、高效地开发大尺度的大遥感数据是亟待研究的问题。一种可能的应用是遥感数据压缩。利用高效的MFH,可以将大规模的数据压缩成二进制码,而不会造成明显的信息损失,这将大大减少存储量。另一种可能的探索是对接近重复的光谱或类似对象进行快速检索。由于紧凑二进制码,最近邻搜索或近似最近邻搜索将非常有效,因此大大降低了时间复杂度。