分析
1,先进行准备工作:使用fiddle抓包(大家可以自行百度怎么使用哦)
2,打开电脑端微信,找到需要爬取的公众号
点击进入公众号,再打开fiddle,微信停留在这一步
打开fiddle后再点击微信的下图按钮

fiddle会出现很多包,微信里面继续向下滑动,直至fiddle里出现

点击fiddle右侧的Raw,找到下面的链接并点击进去

点击后会出现这个页面
3,然后在浏览器中点击检查元素,找到network
在网页滑动的过程中会出现一个json文件的链接

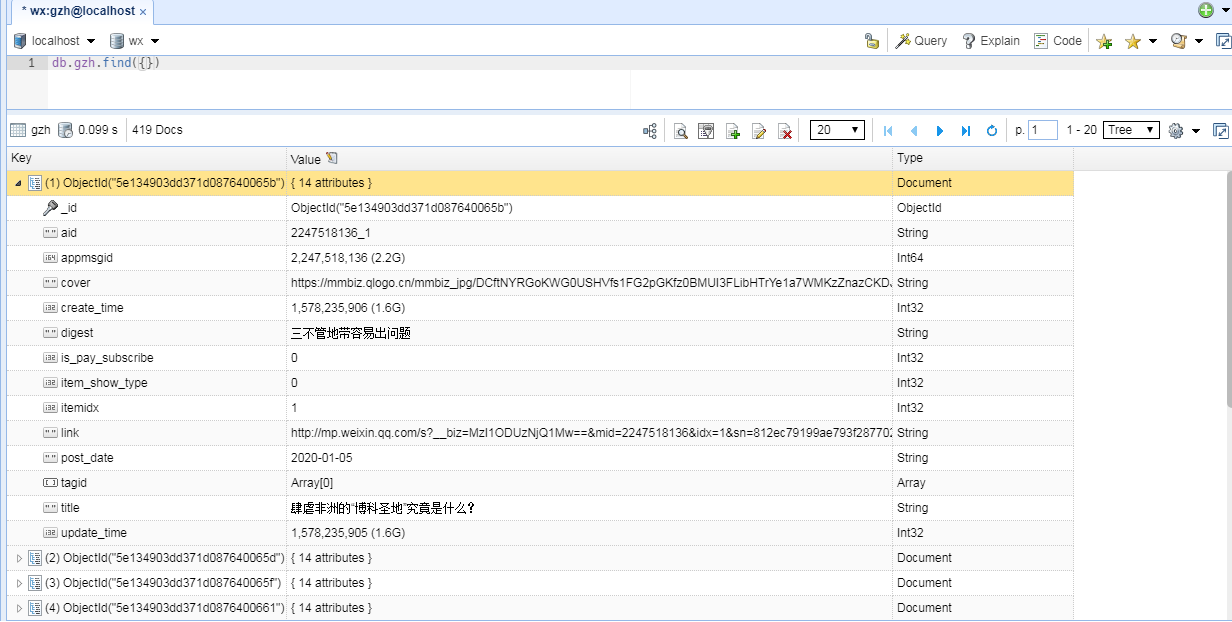
进去看看是这样子的

这就是我们要抓取的数据了
4,在第3步中可以继续将网页向下滑动,对比链接的不同

发现只有offset每次增加10,再观察第三步的第二个图发现正好是10个数据,说明offset每一次改变就是10篇不同的文章
**遇到的坑:
1,微信不能请求太频繁,不然会无法进入文章页面24小时
2,用fiddle抓取的这个链接有时效性,经测试大约30分钟
测试代码如下
3,想让爬取的url变成pdf需要使用pdfkit库,大家可以自行百度哦
import requests,time
data0 = time.time()
while True:url = 'https://mp.weixin.qq.com/mp/profile_ext?action=getmsg&__biz=MzA5NjEwNjE0OQ==&f=json&offset=11&count=10&is_ok=1&scene=124&uin=MTczNjk0NDEwMw%3D%3D&key=827f3335bef33e45717c17a835620ed3e7c540ab72a526ab5b053adcaa860be393c02f9ac5dcd1f29e45d6568788ca024b2aef3a0ff57fea9324a750ff257637fdba0690f8531315bdfca09cb3b9face1b1a5eb7efd9a8fc4f6948dd63e5930be4109b6de50b4efea8dc446012adf7ea5d58ee9ee75620ef9b1d7086201a78dc&pass_ticket=jN5PzMHo4SdLo6xWe8i%2FvQ6x87AEnKHHtwMkpl%2FuH6TKwnoBj%2F01J3thBdOHmMTM&wxtoken=&appmsg_token=1075_HtI4fzr7%252F2AwFEgwfox68YcvhRovjfzSy9-Knw~~&x5=0&f=json' r = requests.get(url)if len(r.text) > 400:time.sleep(180)else:print("有效期为"+str(int(time.time()-data0)/60)+"分钟")break
结果为

编写代码
1,构造headers,使用这里面的参数
import requests,random,re
User_Agent = ['Mozilla/5.0 CK={} (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.157 Safari/537.36','Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322)','Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36','Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/17.17134','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/18.17763','Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; KTXN)','Mozilla/5.0 (Windows NT 5.1; rv:7.0.1) Gecko/20100101 Firefox/7.0.1','Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)','Mozilla/5.0 (Windows NT 6.1; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0','Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1','Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.90 Safari/537.36','Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)','Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36','Mozilla/5.0 (Windows NT 6.1; WOW64; rv:18.0) Gecko/20100101 Firefox/18.0'
]
headers = {}
headers['connection'] = 'keep-alive'
headers['host'] = 'mp.weixin.qq.com'
headers['User-Agent'] = random.choice(User_Agent)
headers['referer'] = 'https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=MzA3Nzc4MzY2NA=='
headers['cookie'] = 'pgv_pvi=2150888448; RK=qBo4z5fmcP; ptcz=6b4b4ae9eb01daeffff996302197842b93afa3c6501532cce8850cdda5a37855; pgv_pvid=2824430422; pac_uid=0_5e87d63ce838c; tvfe_boss_uuid=bfebe1f857002eaf; XWINDEXGREY=0; Hm_lvt_dde6ba2851f3db0ddc415ce0f895822e=1588923704,1589040012; ua_id=MgD7dxr2iLcmCup2AAAAAC3Cx-Yr2sX1OGi-UfyQTzk=; Hm_lvt_dde6ba2851f3db0ddc415ce0f895822e=1588923704,1589040012; _ga=GA1.2.807773159.1593618327; iip=0; wxuin=1736944103; lang=zh_CN; pass_ticket=jN5PzMHo4SdLo6xWe8i/vQ6x87AEnKHHtwMkpl/uH6TKwnoBj/01J3thBdOHmMTM; devicetype=android-28; version=2700113f; wap_sid2=COfTnrwGEooBeV9ITnlBb3FjWk9LLUh6bmhCWE9XZk5oWEFoUXZxdUhkYTlTMWxUYVVvYjNSaGdmN3NiVTBIb29BejBRVjFicFFHV0phQzBWSE5FLUJpREw2a3pUVUROM0RjejlnaTN4eUQtZXJkQWpOb2QxbXR1SWl2bnU0Y2l0ME0zNkFGS3hvRnJSRVNBQUF+MJKUkfoF='
import requests,json,time
import pdfkit
##对json文件进行解析
def parse_page(url):r = requests.get(url,headers=headers)r = r.texta = json.loads(r)['general_msg_list']lists = json.loads(a)['list']##此处将链接和名字保存在html文件中f = open('python.html','a')for i in lists:try:title1 = i['app_msg_ext_info']['title']##json文件中有两种形式表示title,URL,故使用if else语句if len(title1)==0:title = i['app_msg_ext_info']['multi_app_msg_item_list'][0]['title']title = re.sub(r'[!,,\?\\\/:<>&$\*\|@#]','',title)link = i['app_msg_ext_info']['multi_app_msg_item_list'][0]['content_url']digest = i['app_msg_ext_info']['multi_app_msg_item_list'][0]['digest']article = {'title':title,'link':link,'digest':digest}f.write('<a href='+link+'>'+title+'</a>'+'<br>')save_pdf(link,title)print(article)time.sleep(1)else:title = i['app_msg_ext_info']['title']title = re.sub(r'[!,,\?\\\/:<>&$\*\|@#]','',title)link = i['app_msg_ext_info']['content_url']digest = i['app_msg_ext_info']['digest']article = {'title':title,'link':link,'digest':digest} f.write('<a href='+link+'>'+title+'</a>'+'<br>')save_pdf(link,title)time.sleep(1)print(article)print("*"*30)except:continuef.close()
##将网页链接url保存为pdf
def save_pdf(url,title):config=pdfkit.configuration(wkhtmltopdf=r"D:\tesseract\wkhtmltopdf\bin\wkhtmltopdf.exe")pdfkit.from_url(url,'E:1/'+title+'.pdf',configuration=config)##多页爬取
def main():for i in range(1,100):print("*"*30)print('第%d页' %i)print("*"*30)url = 'https://mp.weixin.qq.com/mp/profile_ext?action=getmsg&__biz=MzA3Nzc4MzY2NA==&f=json&offset={}0&count=10&is_ok=1&scene=124&uin=MTczNjk0NDEwMw%3D%3D&key=827f3335bef33e450aa3cb8e6088b5eed9e86a3b7a9023c61ce26ed85c0fae456a59262f47906011422679031b89df59a0ded071e96ceb9f39d6226f284762ccb2b9d755a17d2047b09cc00a9bf44e23f3ce6f33e8744deb4c69caa7c7c9226316825095c58ecbfa010e4219651e8eeb45c0370d6f04637e301a7b08a89e966f&pass_ticket=pCWEQrqZBNyT5N91MECA49xCvslYFAsMinBKcBCJHXd32k4pqEAaJtOjqUXajp0R&wxtoken=&appmsg_token=1079_uwFRe2sGJ6uaIdrzGCAnHbgqeLCpi7WbQqak7g~~&x5=0&f=json'.format(i) parse_page(url)##爬取一页睡眠几秒,防止微信被封time.sleep(10+int(random.random()*10))if __name__ == '__main__':
##此处将HTML 文件内容清空f = open('python.html','w')f.write('')f.close()main()
结尾













{kind=link}