代码还是热乎的,只要你细心一步步的慢慢调试,绝壁没问题
前期准备
- 订阅号;
- Python;
- Fiddler;
- 微信账号;
流程
- 使用用微信公众号生成cookie
- 使用Fiddler抓取微信公众号数据, 获取阅读数
- 通过cookie请求公众号获取文章,再使用Fiddler抓取的数据获取阅读数
- 整理数据写入到数据库
效果
- 平均20s可爬取一篇文章。为了微信号、订阅号的安全 时间间隔长一点
- 可按日期爬取文章。
- 视频文章无法爬取。当然了代码优化优化应该也是可以的
- 订阅号会出现 搜索文章限制问题。换一个订阅号解决
操作
操作
- 获取订阅号Cookie
1.1、基于Python调用chromedriver.exe, 打开URL
1.2、输入账号、密码
1.3、手动扫码
1.4、生成cookie.txt 文件, 包含cookie信息

- Fiddler抓取微信客户端公众号请求数据, 获取阅读量
需要获取req_id 、 pass_ticket 、 appmsg_tojen、cookie 和user-agent

2、1 电脑登录微信(PC版)
2、2 关注需要爬取的公众号
2、3 设置Fiddler 并保存配置

微信客户端请求公众号文章, fiddler抓取到的数据req_id 、 pass_ticket 、 appmsg_tojen


微信客户端请求公众号文章, fiddler抓取到的数据cookie 和user-agent

最后恢复Fiddler的配置,会报错的
END!!!前面的获取工作就结束了…
一、获取cookie
# -*- coding: utf-8 -*-import time
import json
from selenium import webdriver
import sys
sys.path.append('/path/to/your/module')post = {}driver = webdriver.Chrome(executable_path="chromedriver.exe")
driver.get('https://mp.weixin.qq.com')
time.sleep(2)driver.find_element_by_name('account').clear()
driver.find_element_by_name('account').send_keys('订阅号账号')
driver.find_element_by_name('password').clear()
driver.find_element_by_name('password').send_keys('订阅号密码')# 自动输入密码后点击记住密码
time.sleep(5)
driver.find_element_by_xpath("./*//a[@class='btn_login']").click()
# 扫码
time.sleep(20)
driver.get('https://mp.weixin.qq.com')
cookie_items = driver.get_cookies()
for cookie_item in cookie_items:post[cookie_item['name']] = cookie_item['value']
cookie_str = json.dumps(post)
with open('cookie.txt', 'w+', encoding='utf-8') as f:f.write(cookie_str)print('cookie write ok ...')
二、获取文章数据(文章列表写入数据库)

# -*- coding: utf-8 -*-import time, datetime
import json
import requests
import re
import random
import MySQLdb#设置要爬取的公众号列表
gzlist=['ckxxwx']
# 打开数据库连接
db = MySQLdb.connect("localhost", "root", "123456", "wechat_reptile_data", charset='utf8' )# 数据的开始日期 - 结束日期
start_data = '20190630';
end_data = '20190430'# 使用cursor()方法获取操作游标
cursor = db.cursor()# 获取阅读数和点赞数
def getMoreInfo(link, query):pass_ticket = "VllmJYTSgRotAAiQn17Tw1v35AduDOg%252BLCq%252B07qi4FKcStfL%252Fkc44G0LuIvr99HO"if query == 'ckxxwx':appmsg_token = "1016_%2F%2Bs3kaOp2TJJQ4EKMVfI0O8RhzRxMs3lLy54hhisceyyXmLHXf_x5xZPaT_pbAJgmwxL19F0XRMWtvYH"phoneCookie = "rewardsn=; wxuin=811344139; devicetype=Windows10; version=62060833; lang=zh_CN; pass_ticket=VllmJYTSgRotAAiQn17Tw1v35AduDOg+LCq+07qi4FKcStfL/kc44G0LuIvr99HO; wap_sid2=CIvC8IIDElxlWlVuYlBacDF0TW9sUW16WmNIaDl0cVhxYzZnSHljWlB3TmxfdjlDWmItNVpXeURScG1RNEpuNzFUZFNSZWVZcjE5SHZST2tLZnBSdDUxLWhHRDNQX2dEQUFBfjCasIvpBTgNQAE=; wxtokenkey=777"mid = link.split("&")[1].split("=")[1]idx = link.split("&")[2].split("=")[1]sn = link.split("&")[3].split("=")[1]_biz = link.split("&")[0].split("_biz=")[1]# 目标urlurl = "http://mp.weixin.qq.com/mp/getappmsgext"# 添加Cookie避免登陆操作,这里的"User-Agent"最好为手机浏览器的标识headers = {"Cookie": phoneCookie,"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 MicroMessenger/6.5.2.501 NetType/WIFI WindowsWechat QBCore/3.43.1021.400 QQBrowser/9.0.2524.400"}# 添加data,`req_id`、`pass_ticket`分别对应文章的信息,从fiddler复制即可。data = {"is_only_read": "1","is_temp_url": "0","appmsg_type": "9",'reward_uin_count': '0'}params = {"__biz": _biz,"mid": mid,"sn": sn,"idx": idx,"key": '777',"pass_ticket": pass_ticket,"appmsg_token": appmsg_token,"uin": '777',"wxtoken": "777"}# 使用post方法进行提交content = requests.post(url, headers=headers, data=data, params=params).json()# 提取其中的阅读数和点赞数if 'appmsgstat' in content:readNum = content["appmsgstat"]["read_num"]likeNum = content["appmsgstat"]["like_num"]else:print('请求参数过期!')# 歇10s,防止被封time.sleep(10)return readNum, likeNum#爬取微信公众号文章,并存在本地文本中
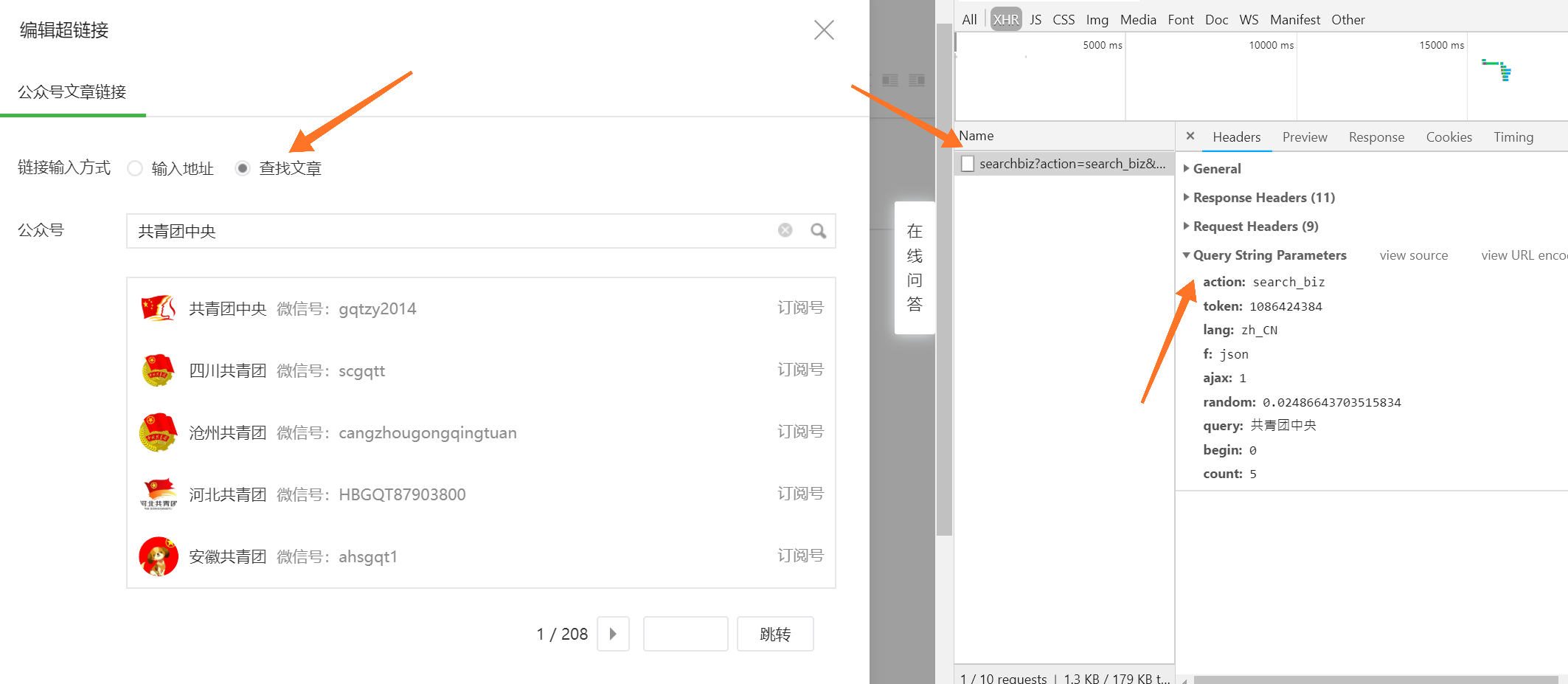
def get_content(query):#query为要爬取的公众号名称#公众号主页url = 'https://mp.weixin.qq.com'#设置headersheader = {"HOST": "mp.weixin.qq.com","User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0"}#读取上一步获取到的cookieswith open('cookie.txt', 'r', encoding='utf-8') as f:cookie = f.read()cookies = json.loads(cookie)#登录之后的微信公众号首页url变化为:https://mp.weixin.qq.com/cgi-bin/home?t=home/index&lang=zh_CN&token=1849751598,从这里获取token信息response = requests.get(url=url, cookies=cookies)token = re.findall(r'token=(\d+)', str(response.url))[0]time.sleep(2)#搜索微信公众号的接口地址search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'#搜索微信公众号接口需要传入的参数,有三个变量:微信公众号token、随机数random、搜索的微信公众号名字query_id = {'action': 'search_biz','token' : token,'lang': 'zh_CN','f': 'json','ajax': '1','random': random.random(),'query': query,'begin': '0','count': '5'}#打开搜索微信公众号接口地址,需要传入相关参数信息如:cookies、params、headerssearch_response = requests.get(search_url, cookies=cookies, headers=header, params=query_id)#取搜索结果中的第一个公众号lists = search_response.json().get('list')[0]#获取这个公众号的fakeid,后面爬取公众号文章需要此字段fakeid = lists.get('fakeid')#微信公众号文章接口地址appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'#搜索文章需要传入几个参数:登录的公众号token、要爬取文章的公众号fakeid、随机数randomquery_id_data = {'token': token,'lang': 'zh_CN','f': 'json','ajax': '1','random': random.random(),'action': 'list_ex','begin': '0',#不同页,此参数变化,变化规则为每页加5'count': '5','query': '','fakeid': fakeid,'type': '9'}#打开搜索的微信公众号文章列表页appmsg_response = requests.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)#获取文章总数if appmsg_response.json().get('base_resp').get('ret') == 200013:print('搜索公众号文章操作频繁,!!!')max_num = appmsg_response.json().get('app_msg_cnt')#每页至少有5条,获取文章总的页数,爬取时需要分页爬num = int(int(max_num) / 5)#起始页begin参数,往后每页加5begin = 0 # 根据内容自定义while num + 1 > 0 :query_id_data = {'token': token,'lang': 'zh_CN','f': 'json','ajax': '1','random': random.random(),'action': 'list_ex','begin': '{}'.format(str(begin)),'count': '5','query': '','fakeid': fakeid,'type': '9'}print('正在翻页:--------------',begin)time.sleep(5)#获取每一页文章的标题和链接地址,并写入本地文本中query_fakeid_response = requests.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)fakeid_list = query_fakeid_response.json().get('app_msg_list')for item in fakeid_list:content_link=item.get('link')content_title=item.get('title')update_time=item.get('update_time')timeArray = time.localtime(update_time)DataTime = time.strftime("%Y%m%d", timeArray)print(DataTime)Yearsmonth = time.strftime("%Y%m", timeArray)if DataTime <= start_data:if DataTime <= end_data:mark = '1'print('END....')break # 退出# 阅读数 点赞数readNum, likeNum = getMoreInfo(item['link'], query)print(readNum, likeNum, datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'))mark = '0'# SQL 插入语句sql = """INSERT INTO `wechat_urls` (`title`, `url`, `data_date`, `gzname`, `read_num`, `like_num`) VALUES ('""" + content_title + """', '""" + content_link+ """', '""" + DataTime+ """', '""" + query+ """', '""" + str(readNum)+ """', '""" + str(likeNum)+ """');"""try:# 执行sql语句print(sql)cursor.execute(sql)# 提交到数据库执行db.commit()except:# Rollback in case there is any errordb.rollback()elif DataTime >= start_data:mark = '2'print('END....')break # 退出time.sleep(5)if mark == '0':num -= 1begin = int(begin)begin += 5time.sleep(3)elif mark == '1':break # 退出elif mark == '2':num -= 1begin = int(begin)begin += 1time.sleep(20)# 关闭数据库连接# db.close()if __name__=='__main__':try:#登录之后,通过微信公众号后台提供的微信公众号文章接口爬取文章for query in gzlist:#爬取微信公众号文章,并存在本地文本中print("开始爬取公众号:"+query)get_content(query)print("爬取完成")except Exception as e:print(str(e))
console日志

三、读取URL列表, 文章数据写入数据库
from urllib.request import urlopen
import MySQLdb
import requests
from pyquery import PyQuery as pq
import time, datetime# 打开数据库连接
db = MySQLdb.connect("localhost", "root", "123456", "wechat_reptile_data", charset='utf8' )
# 使用cursor()方法获取操作游标
cursor = db.cursor()# 写入数据
def insert_contents(title, url, data_date, gzname, read_num, like_num):# 抓取页码内容,返回响应对象response = requests.get(url)response.encoding = 'utf-8'# 将html构建为Xpath模式doc = pq(response.text)js_content = doc('#js_content').text()# SQL 插入语句sql = """INSERT INTO `wechat_reptile_data`.`wechat_datas` (`title`, `content`, `gzh`, `data_date`, `read_num`, `like_num`) VALUES ('""" + title + """', '""" + js_content + """', '""" + gzname + """', '""" + data_date + """', '""" + str(read_num) + """', '""" + str(like_num) + """');"""try:# 执行sql语句print('===>>>', data_date+' : '+gzname)cursor.execute(sql)# 提交到数据库执行db.commit()except:# Rollback in case there is any errordb.rollback()time.sleep(1)# 更新数据
def update_contents(title, url, data_date, gzname):# SQL 更新语句sql = """UPDATE wechat_urls SET state = '1' WHERE title = '"""+title+"""' AND data_date = '"""+data_date+"""' AND gzname = '"""+gzname+"""'"""try:# 执行SQL语句cursor.execute(sql)# 提交到数据库执行db.commit()except:# 发生错误时回滚db.rollback()time.sleep(1)# SQL 查询语句
sql = "select * from wechat_urls where state='0';"
try:# 执行SQL语句cursor.execute(sql)# 获取所有记录列表results = cursor.fetchall()for row in results:title = row[0]url = row[1]data_date = row[2]gzname = row[3]read_num = row[4]like_num = row[5]insert_contents(title, url, data_date, gzname, read_num, like_num)update_contents(title, url, data_date, gzname)
except:print("Error: unable to fecth data")代码是东拼西凑写出来的还没来得及优化
看见一年前发布的这个文章,有部分同学比较感兴趣,我就找了找源码
源码我发布到了CSDN的下载站
Reptile_Wechat_Data.rar
源码包内包含了全部的源码、Sql文件、配置文件
代码、数据结构一直没有优化
参考就好