在如何爬取微信公众号(一)中完成了将爬取公众号文章的元数据存入数据库,其中包括文章的连接、标题、发布时间、摘要和封面图片等信息。下面介绍如何根据文章链接来爬取文章内容。
开发环境
- windows 7 x64
- python3.7 (Anaconda)
- vscode 编辑器
- mongodb4.0 数据库
- Nosqlbooster mongodb数据库的可视化管理工具
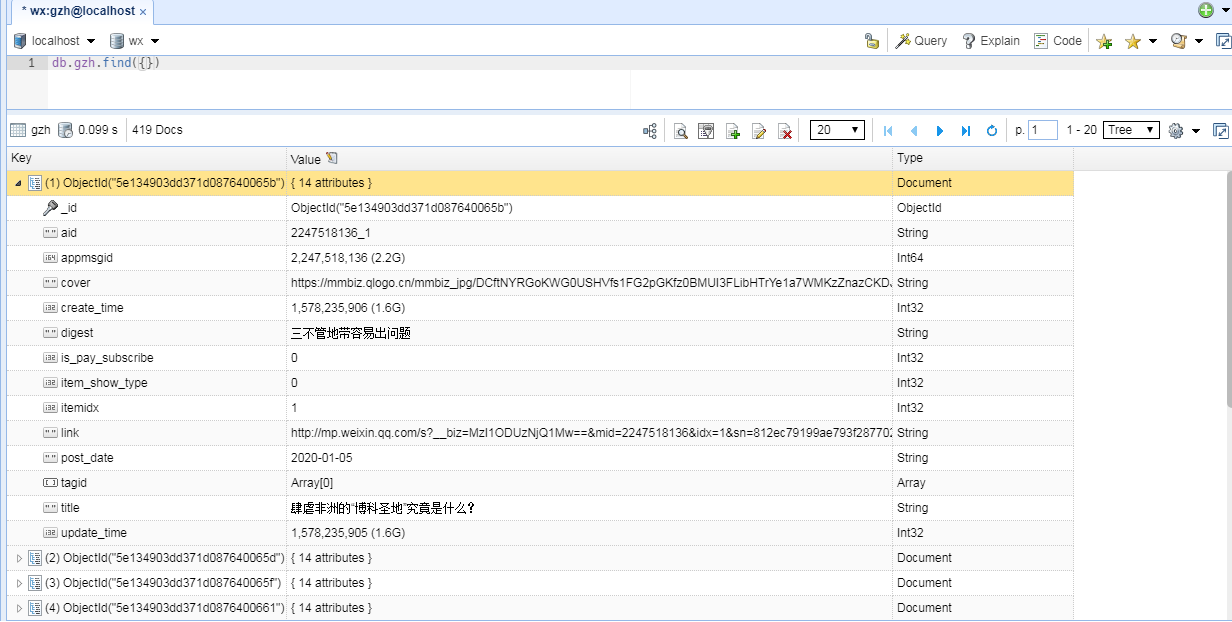
mongodb数据库中以文档格式来存储数据,如一条文章数据是这样存储的。
//Copy from NoSQLBooster for MongoDB free edition. This message does not appear if you are using a registered version.{"_id": "5e134903dd371d087640065b","aid": "2247518136_1","appmsgid": 2247518136,"cover": "https://mmbiz.qlogo.cn/mmbiz_jpg/DCftNYRGoKWG0USHVfs1FG2pGKfz0BMUI3FLibHTrYe1a7WMKzZnazCKDJ9OUfuibGbewFqIiakic8MEqDkNiaXHH7w/0?wx_fmt=jpeg","create_time": 1578235906,"digest": "三不管地带容易出问题","is_pay_subscribe": 0,"item_show_type": 0,"itemidx": 1,"link": "http://mp.weixin.qq.com/s?__biz=MzI1ODUzNjQ1Mw==&mid=2247518136&idx=1&sn=812ec79199ae793f28770287969d0f2b&chksm=ea0462d2dd73ebc40f6ecc4f1f52fb2a3e0c798ca152aa89cc42b8e77ef6e54234695ad43025#rd","post_date": "2020-01-05","tagid": [],"title": "肆虐非洲的“博科圣地”究竟是什么?","update_time": 1578235905
}
里面的link字段为文章的url。
下面我们根据这个url来爬取文章的内容。
爬取文章内容,主要包括文章的html页面,引用的js和css,以及页面中的图片。微信公众号的js和css都是内嵌在页面当中,没有引用的外部文件,所以只需爬取页面中的图片,并将公网的url替换成本地的相对uri即可。
下面看代码。
代码实现
# -*- coding:utf-8 -*-
# written by wlj @2020-1-7 13:52:34
#功能:从数据库读取文章url,将公众号文章爬取到本地
#用法:python get_article.py [本地存储路径] 如python get_article.py wx_articles
import time
import json
import requests,re,sys,os
from requests.packages import urllib3
from bs4 import BeautifulSoup
import hashlib
from pymongo import MongoClient
urllib3.disable_warnings()#全局变量
#存储路径,去掉前后的连接符
path = sys.argv[1].strip('/').strip('\\')
#静态文件的存储路径
static_path = ''
#HTTP请求的headers
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:72.0) Gecko/20100101 Firefox/72.0"
}#计算x的md5()
def md5(x):m = hashlib.md5()m.update(x.encode('utf-8'))return m.hexdigest()#根据url爬取文章,article_filename要保存的html文件名
def get_article(url,article_filename):global static_path#requests会话对象s = requests.Session()#主页文章页面res = s.get(url,headers = headers,verify=False)if res.status_code == 200:#html文档content = res.text#使用bs库解析文档结构soup = BeautifulSoup(res.text,'lxml')#找出html中的图片for img in soup.find_all('img'):#找到图片的url,有的img的图片源在data-src字段中img_url = img.attrs.get('src','').strip()img_url = img_url if img_url else img.attrs.get('data-src','').strip()if img_url:#处理img_url是 //xxx.xxx.xx.jpg的情况if img_url.startswith('//'):img_url = 'http:'+img_url#图片在本地的存储路径,文件名为img_url的md5值img_filename = '%s/%s' % (static_path,md5(img_url))#图片在本地的相对urilocal_img_uri = 'static/%s' % md5(img_url)#若该图片本地不存在,对其进行下载if not os.path.isfile(img_filename):#请求图片res = s.get(img_url,headers = headers,verify=False)if res.status_code == 200:#保存图片open(img_filename,'wb').write(res.content)#将html文档中的互联网url替换成本地的相对uricontent = content.replace(img_url,local_img_uri)#将img标签的data-src替换为src,因为data-src属性不会显示出来content = content.replace('data-src','src')#保存html文档open('%s/%s.html'% (path,article_filename),'w',encoding='utf-8').write(content)print(article_filename,'下载完毕!')#主函数
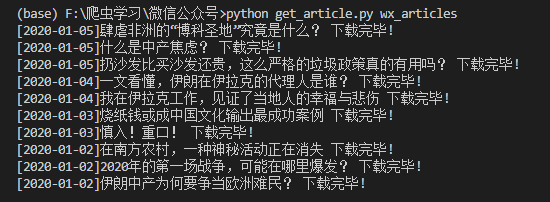
def main():#声明全局变量global static_path#静态文件的存储路径static_path = '%s/static' % path#若该路径不存在,将其创建if not os.path.isdir(static_path):os.makedirs(static_path)#mongodb数据库,存储有文章的元数据mongo = MongoClient('localhost',27017).wx.gzh#作为示例,返回前10条文章数据for item in mongo.find({},limit=10,skip=0):#爬取文章,并以"[发布时间]标题.html"保存为本地文件get_article(item['link'],'[%s]%s' % (item['post_date'],item['title']))main()
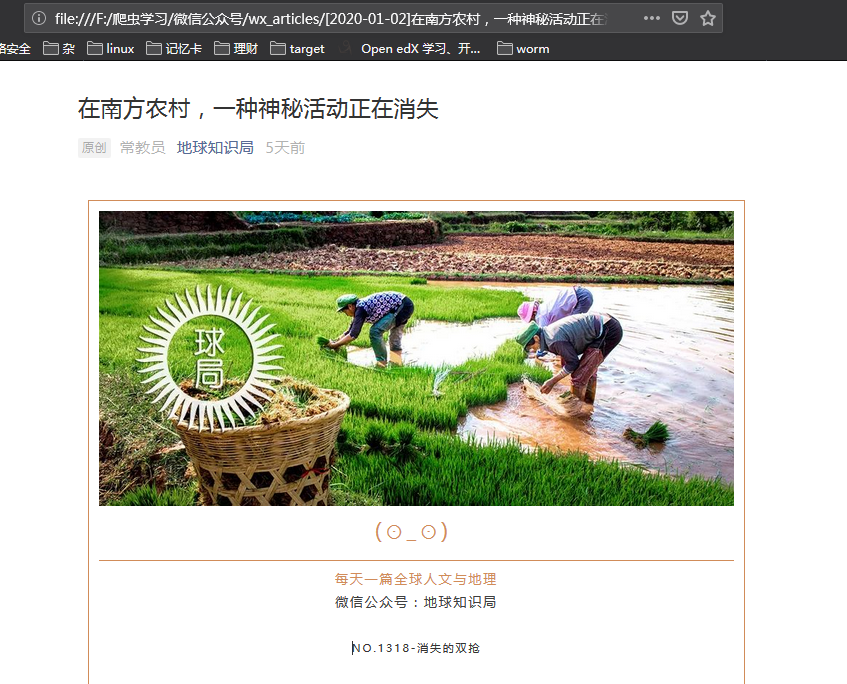
结果

参考资料
- What are all the differences between src and data-src attributes?