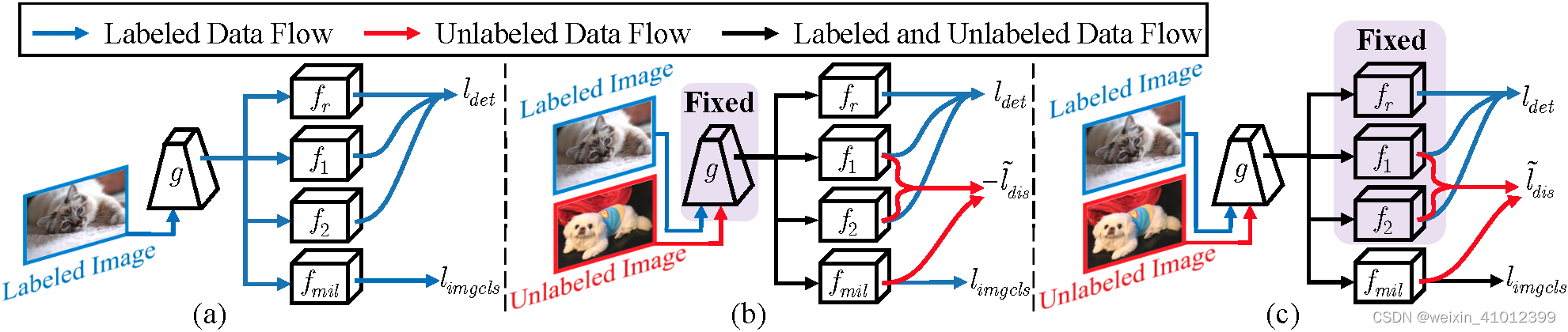
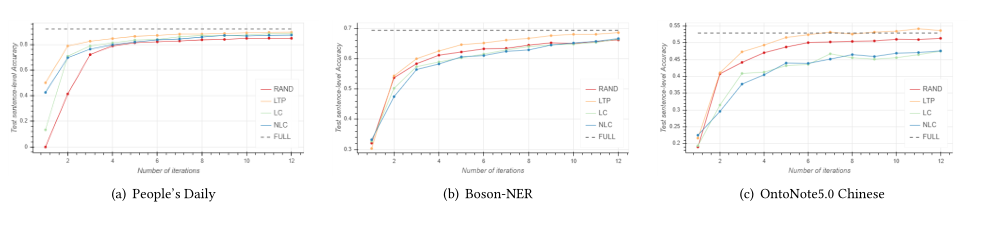
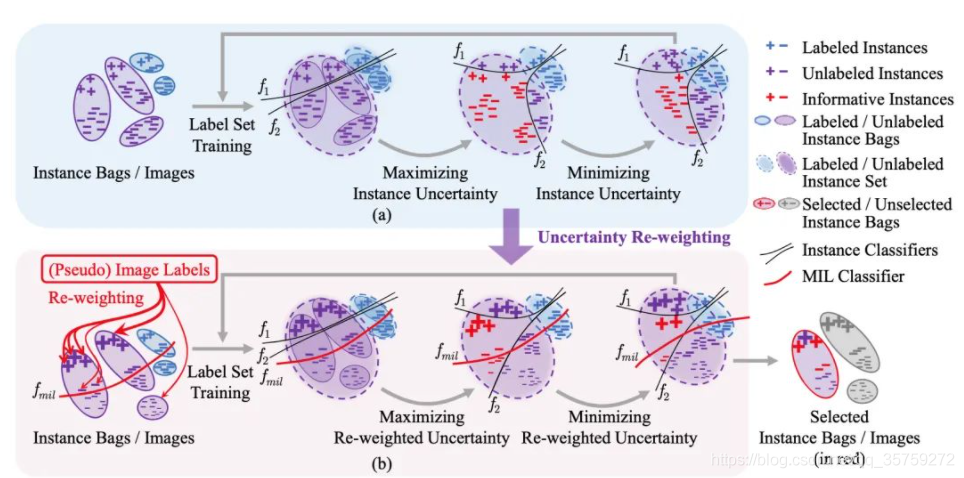
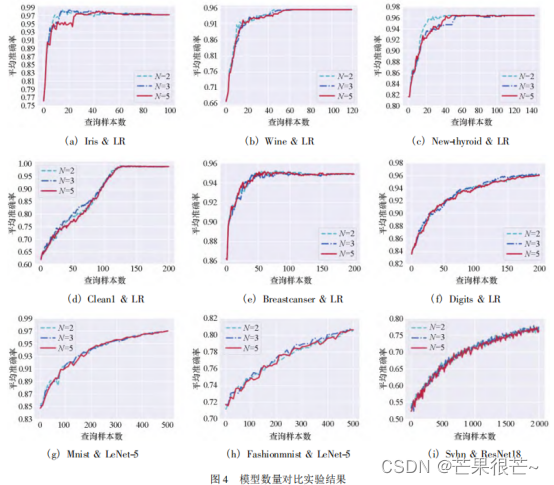
最近在做主动学习相关的东西,随着深入了解和学习对于某些东西有一些模糊,先将所见所感整理如下,如有不正确之处希望大佬能够指正:
1.主动学习
1.1关键问题
对于监督学习模型,足够多的已标注样例是获得高精度分类器的前提条件,随着传感器技术的迅速发展,数据采集变得越来越容易,同时也导致位置样例在总样例中占比较大,而人工标注位置样例成本昂贵。另外,过多的低质量训练样例反而会降低分类器的鲁棒性,甚至导致“过学习”问题。因此,需要控制训练样例集的数量和质量。
如何高效地选出高分类贡献度的无类标样例进行标注并补充到已有训练集中逐步提高分类器精度与鲁棒性是主动学习亟待解决的关键问题。
1.2定义
目前主动学习已经成为机器学习、模式识别和数据挖掘研究领域中最前瞻和热点的研究方向之一。
文章《Active Learning Literature Survey》阐述主动学习是机器学习的一个子领域,在统计学领域也叫做查询学习、最优实验设计。关键的假设如果机器可以自己选择学习的样本,它可以使用较少的训练取得更好的效果。
如何利用为标注样例,从中挑选出对训练贡献度高的样例,标注后补充到训练集中来提升分类器性能是机器学习研究方向之一。
主动学习的主要目标是在保证分类精度不降低的前提下有效地发现训练数据集中高信息量的样本,是训练的分类器在较低的标注下高效地训练模型。
主动学习的研究多数情况下集中在两个地方:选择策略和查询策略。选择策略指导模型从哪里选择为标注样本,查询策略指导模型如何确定未标注样本是否需要被标注。
主动学习算法一般包含2个重要模块:学习模块和选择模块,学习模块本质上就是训练分类器的过程,即通过示教学习主键提高分类器的分类精度与鲁棒性;而选择模块的终极目标是生成高质量的训练样例集,以提高样例集的代表性和广泛性。
1.3步骤
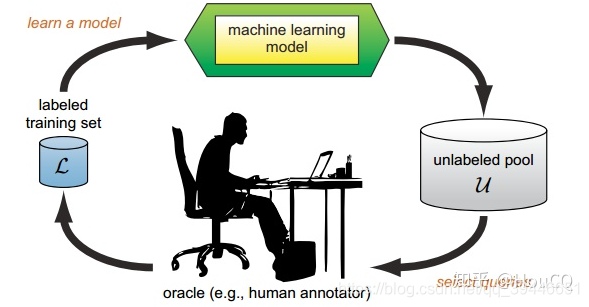
主动学习的模型可以用A=(C,L,S,Q,U)表示,其中C表示分类器(1个或多个),L表示带标注的样本集,S表示督导者,可以对未标注样本进行标注,Q表示当前所使用的查询策略,U表示为标注的样本集。
(1)选取合适的分类器(网络模型)记为current_model、主动选择策略、数据划分为train_sample(带有标注的样本,用于训练模型)、validation_sample(带标注的样本,用于验证当前模型的性能)、active_sample(未标注的数据集,对应于U币labeled pool);
(2)初始化:随机初始化或者通过迁移学习(source domain)初始化;如果有target domain的标注样本,就通过这些表示标注样本对模型进行训练;
(3)使用当前模型current_model对active_sample中的样本进行逐一预测(预测不需要标签),得到每个样本的预测结果。此时可以选择Uncertainty Strategy衡量样本的标注价值,预测结果越接近0.5的样本表示当前模型对于该样本具有较高的不确定性,即样本需要进行标注的价值越高。
(4)专家对选择的样本进行标注,并将标注后的样本放至train_sample目录下。
(5)使用当前所有标注样本train_sample对于当前模型current_model进行fine_tuning,更新current_model;
(6)使用当前current_model对validation_sample进行验证,如果当前模型的性能得到目标或者已不能再继续标注新的样本(没有专家或者没有钱),则结束迭代过程。否则,循环执行步骤(3)。
整个过程如下图所示。
2.应用场景
大多数人将其分为以下主要的三种,即Membership query synthesis、Stream_based selective sampling、Pool_based sampling,但有的人将其分为四种,多了一种Query synthesis。
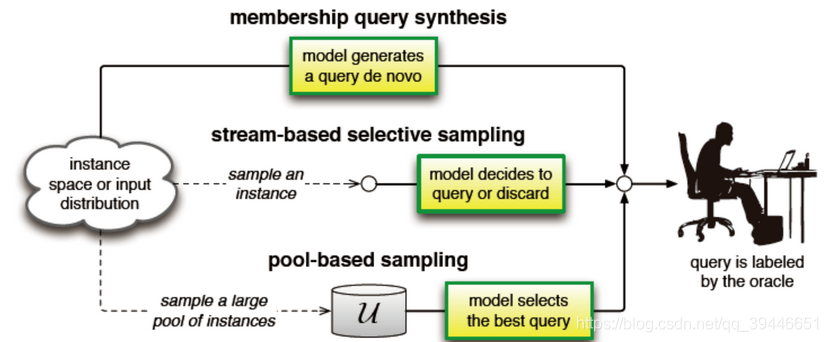
2.1Membership Query Synthesis
从字面上无法理解,不过这正方式的实例是算法从整个可能的样本空间中生成的,模型从头开始生成一个实例然后送回oracle打标签。
2.2Stream_based Selective Sampling
基于流的策略一次从未标注样例池中取出一个样例输入到选择模块,若满足预设的选中条件则对其进行准确的人工标注,反之直接舍弃。该学习过程需要处理所有未标记样例,查询成本高昂。另外,由于基于流的样例选择策略需要预设一个样例标注条件,但该条件往往需要根据不同的任务适当调整,因此很难将其作为一种通用方法普遍使用。
2.3Pool_based Sampling
基于池的方法每次从系统维护的未标注样例池中按照预设的选择规则选取一个样例交给基准分类器进行识别,当基准分类器对其识别出错误时进行人工标注。相较基于流的方法,基于池的方法每次都可选出当前样例池中对分类贡献最高的样例,这即降低了查询样例成本,也降低了标注代价,这使得基于池的样例选择策略广泛使用。基于池的样例选择标准主要包括:不确定性标准、版本空间缩减标注、泛化误差缩减标注等。
3.查询策略
查询策略也叫做查询函数,以往的方法大概分为这两类:一类方法,倾向于选择最有信息的样本,例如,我去叫你最不会的东西应该是对你最有帮助的;另一类方法,是倾向选择最优代表性的样本,希望选择的样本涵盖数据整体分布的信息。
按照获取优质样例工作方式的不同可将样例选择分为基于流(Stream_based)和基于池(Pool_based)的策略。
基于池的样例选择策略细分为不确定性(Uncertainty)、版本空间缩减标准和泛化误差缩减标准等。
4.主动学习算法形式
4.1基于委员会的启发式方法(QBC)
选择一定数量的分类模型,构成分类委员会。利用初始训练集训练委员会中的每个模型,并将训练完成的模型用于分类未标记样本池中的样本。该方法选择所有模型分类结果中最不一致的样本。
4.2基于边缘的启发式方法(MS)
4.3基于后验概率的启发式方法(pp)
5.半监督学习与主动学习
两者都是从未标记样例中挑选部分价值量高的样例标注后补充到已标记样例集中来跳高分类器中精度,降低领域专家的工作量,但两者的学习方式不同。
(1)半监督学习一般不需要人工参与,是通过具有一定分类精度的基准分类器实现对未标注样例的自动标注;而主动学习需要将挑选出的高价值样例进行人工准确标注。
(2)半监督学习通过用计算机进行自动或半自动标注代替人工标注,虽然有效降低了标注代价,但其标注结果依赖于用部分已经标注样例训练出的基准分类器的分类精度,因此并不能保证标注结果完全正确。