目录
- 1. 基本概念
- 2. 基于不确定性的主动学习方法
- 3.基于最近邻和支持向量的分类器的方法
- 3.1 NNClassifier
- 3.2 RBF network + Gradient Penalty
- 4 基于特征空间覆盖的方法
- 5 基于对抗学习的方法
- 5.1 VAAL
- 5.1.1 核心思想
- 5.1.2 网络结构
- 5.1.3 主动学习策略
- 5.1.4 模型特点
- 5.2 SRAAL
- 5.3 ARAL
- 6 融合不确定性和多样性的学习方法
- 6.1 信息论思路
- 6.2 构建候选集+大差异样本——SA
- 6.3 梯度嵌入空间——badge
- 7 基于变化最大的方法
1. 基本概念
主动学习(active learning)主要针对数据标签较少或标注代价较高的场景而设计的。主动学习主动地提出标注请求,将经过筛选的数据提交给专家进行标注,以期在较少的训练样本下获得较好的模型。

主动学习算法可以由以下五个组件进行建模:
A = ( C , L , S , Q , U ) A=(C,L,S,Q,U) A=(C,L,S,Q,U)
其中 C C C 为分类器; L L L 为已标注的训练样本集; Q Q Q 为查询函数,用于在未标注的样本中查询信息量大的样本; U U U 为整个未标注样本集; S S S 为督导者,对未标注样本进行标注。
主动学习算法主要分为两阶段:
- 初始化阶段,随机从未标注样本中选取小部分,由督导者标注,作为训练集建立初始分类器模型;
- 循环查询阶段, S S S 从未标注样本集 U U U 中,按照查询标准 Q Q Q 选取一定的未标注样本进行标注,并加到训练样本集 L L L 中,重新训练分类器,直至达到停止条件。
即,主动学习算法是一个迭代的过程,分类器使用迭代时反馈的样本进行训练,不断提升分类效率。
对于主动学习,我们非常关心的一个问题是,即标注哪些样本是最有用的呢? 因此,主动学习的关键是对查询策略,即 Q Q Q 的研究。
在各种主动学习方法中,查询函数的设计最常用的策略是:不确定性准则(uncertainty)和差异性准则(diversity)。不确定性越大代表信息熵越大,包含的信息越丰富;而差异性越大代表选择的样本能够更全面地代表整个数据集。
2. 基于不确定性的主动学习方法
基于不确定性的主动学习方法将最小化条件熵作为寻找判定函数的依据。
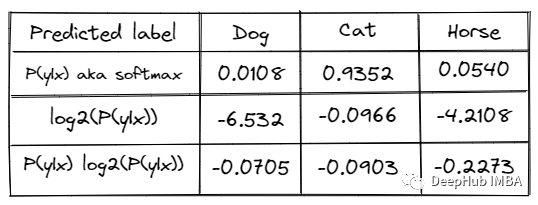
Bayesian Active Learning for Classification and Preference Learning(论文)通过贪婪地找到一个能使当前模型熵最大程度减少的数据点x,但由于模型参数维度很高,直接求解困难,因此在给定数据D和新增数据点x条件下,模型预测和模型参数之间的互信息。
Deep Bayesian Active Learning with Image Data(论文,代码)中实现了这一思路,过程如下:
(1)从整体的数据中选一个子集作为初始训练集,来训练任务模型(分类,分割等等)
(2)用训好的模型在剩余未标注的图像上以train模式跑多组预测,记录对每个样本的输出。
(3)计算对每个样本的熵作为不确定性分数。
(4)从大到小依次选择下一组数据标注好后加入训练集,更新训练模型(在上一代模型上fine-tuning),直到满足停止条件。
考虑到深度学习中,不能每次选一个数据样本就重新训练一次模型,而是以批数据的形式进行训练,BatchBALD(论文)中,把原来的一个样本变成了一批样本。
3.基于最近邻和支持向量的分类器的方法
基于不确定性的主动学习方法依赖模型预测的分类概率来确定模型对该样本的不确定性,但这个概率并不可靠,因为使用softmax分类器的神经网络并不能识别分布外样本,且很容易对OOD样本做出过度自信的预测。
在主动学习中,初始阶段使用非常少的标注样本训练模型,意味着大量的未标注样本可能都是OOD样本,若模型过早的给这部分样本一个过度自信的预测概率,就可能使我们错失一些有价值的OOD样本。如图1所示,初始训练阶段,模型缺乏虚线框以外的区域的训练数据,但softmax分类器仍然会对这些区域给出很自信的预测,导致选择新的待标注样本时,图中的q点会被忽略,而若q点正好不是class B,则会影响主动学习的性能。

3.1 NNClassifier
针对这个问题NNclassifier中设计了一个基于最近邻和支持向量的分类器来取代softmax, 使模型能对远离已有训练数据的区域产生较高的不确定性。
具体而言,每类训练学习N个支持向量,基于样本特征与各类的支持向量之间的距离,就可以定义分类概率为与这N个支持向量的核函数的最大距离:

定义了新的可以意识到OOD样本的分类器之后,作者给出了对应的主动学习策略:
- Rejection confidence,用于度量远离所有支持向量的样本,如图(b)所示;
- confusion confidence,用于度量远离支持向量以及同时靠近多个不同类支持向量的样本,如图©所示。


3.2 RBF network + Gradient Penalty
Amersfoort用RBF神经网络来促使网络具有良好的OOD样本不确定性,同时给出了基于梯度范数的双边正则来削弱特征崩溃(feature collapse)的问题。与NNClassifier相同,本文的作者也定义了一个与各类特征距离的函数K来帮助检测OOD样本,损失函数同样定义成逐类的二值交叉熵。不同于NNClassifier的是,这里的距离是每个样本与该类样本的指数滑动平均得到的。

另一个不同点在于本文加入了一个双边梯度正则项。

这个正则项的作用有两个,一个是保证平滑性,也就是相似的输入有相似的输出,这个是由max()中的梯度部分保证的,而梯度-1则起到避免特征崩溃的作用,也就是相比单纯的使用特征范数正则,-1能够避免模型将很多不同的输入映射到完全相同的特征,也就是feature collapse。
4 基于特征空间覆盖的方法
接下来主要介绍基于特征空间覆盖的主动学习代表性工作:coreset。coreset的主要贡献:给出了基于特征空间覆盖的主动学习算法的近似损失上界;证明了新添加的样本在能够缩小标注样本对剩余样本的覆盖半径时,才能提高近似效果。
coreset认为主动学习目标就是缩小核心集误差,即主动学习选出的样本损失与全体样本损失之间的差别。
我们在主动学习挑选新样本时,并不知道样本的标签,也就没法直接求核心集损失。作者把核心集损失的上界转换做剩余训练样本与挑选出的标注样本间的最大距离。因此,主动学习问题等价于选择添加一组标注样本,使得其他样本对标注样本集的最大距离 δ s \delta_s δs最小,也就是k-center集覆盖问题。如图所示,蓝色为挑选出的标注样本,红色为其他样本。

5 基于对抗学习的方法
5.1 VAAL
Variational Adversarial Active Learning(地址)描述了一种基于池的半监督主动学习算法,它以对抗的方式(关于对抗学习的详细介绍参见这里)隐式地学习了这种采样机制。与传统的主动学习算法不同,VAAL与任务无关,也就是说,它不依赖于试图获取标注数据的任务的性能。VAAL使用变分自编码器(VAE)和训练好的对抗网络来学习潜在空间,以区分未标注和标注的数据。
5.1.1 核心思想
本文的出发点可以理解如下:之前很多方法的uncertainty都是基于模型的,也就是说需要有个分割/分类等模型计算预测结果,然后从结果的好坏去分析相应的被预测样本的价值。而本文的uncertainty是基于数据本身的,也就是说并非基于预测结果本身去分析,而是直接基于样本自身的特征去处理。
核心思想:利用VAE对已标注的数据和未标注的数据进行编码。因此,对于一个未标注的数据,如果其编码向量与潜在空间中向量的差异足够大,那么我们就认为该样本是有价值的。
而对于样本的选择,是通过一个对抗网络来实现的,该对抗网络被用来区分一个样本是已标注还是未标注。因此上文的VAE还有一个额外的任务,即他的编码要让判别器难以区分已经标注还是没有标注。
5.1.2 网络结构
VAE和对抗网络之间的最大最小博弈是这样进行的:VAE试图欺骗对抗网络去预测,所有的数据点都来自已标注池;对抗网络则学习如何区分潜在空间中的不相似性。其结构如下:

5.1.3 主动学习策略
- 一开始随机选择10%的图像开始训练,此时记训练的网络为版本1。对于版本1,训练会迭代max_iterations次,与一般网络训练过程的差别在于每个iteration除了训练"任务模型"外,还得去训练VAE与判别器。而当迭代结束后,训练得到的"任务模型"其实与直接随机抽取10%的图像训练没有区别,因为VAE与判别器只对下一个网络版本有贡献。
- 利用VAE与判别器内包含的经验,一次性抽取5%的新数据加入训练集,此时开始训练网络版本2。而这里特别关键的一点是,版本2仍然是从预训练VGG开始从头训练的(而非在版本1的基础上继续finetune)。至此一直迭代到选取50%的数据结束。
5.1.4 模型特点
本文的强化学习有点"离线"的味道,即最后选取出的50%数据可以很轻松的迁移至其他模型中,选择的过程只依赖VAE与判别器,而与具体的任务无关。
此外该模型训练十分耗时——从10%逐步提升5%至50%,相当于顺序训练了9个相同的模型,再考虑训练VAE与判别器的耗时,训练该主动学习框架的所需时间可能高达原有基础网络的10倍。
5.2 SRAAL
SRAAL是VAAL的一个改进版。在VAAL中,判别器的训练的时候只有两种状态,标注/未标注。SRAAL的作者认为这样忽略了一些信息,有时候任务模型已经能很确信的对某个未标注样本做预测了,就应该降低选择这个样本的优先级。
为了实现这个思路,作者给出了一个任务模型预测不确定度的计算函数,用这个函数的输出结果作为生成对抗网络的判别器训练过程中,无标注样本的标签,而不用简单的个一个二值变量。
5.3 ARAL
VAAL有效的一个关键的因素实际上是同时利用标注/无标注的样本共同训练产生特征映射,而不像之前基于特征的coreset等主动学习方法,仅用标注数据训练产生特征。
ARAL更进一步,也用这些个无标注样本来训练任务模型(如分类器)本身,整体仍然是在VAAL基础上做的,只是增加了cgan的判别器来实现半监督训练任务模型。整体来说,基于池的主动学习用标注样本来训练任务模型,合成的主动学习标注合成的样本来训练任务模型。
相比之下,VAAL用标注数据训练任务模型,用所有数据来训练产生特征;ARAL用所有的训练数据,合成数据来训练任务模型、产生特征映射。相当于使用了半监督的学习方法,与和之前纯基于监督训练的主动学习方法比较自然有所提升。
6 融合不确定性和多样性的学习方法
之前介绍了基于不确定性的方法,以及基于多样性的方法。接下来我们来看看融合两者的方法。就动机而言,如果只用不确定性标准来选样本,在批量选择的场景中,很容易出现选到冗余样本的问题。而在深度学习中,由于训练开销的缘故,通常都采用批主动学习,所以为了提高主动学习的效率,就得考虑批量选择高不确定性样本时的多样性问题。而从多样性样本选择方法的角度来说,单纯的特征空间覆盖算法不能区分模型是否已经能很好预测某部分样本,会限制这类方法所能达到的上限。
融合不确定性和多样性的思路主要有三种:
- 完全延续信息论的分析思路,也就是batchBALD,在批量选择的过程中不采取每个样本互信息直接相加,而用求并的方法来避免选到冗余样本;
- 先用不确定性标准选出大于budget size的候选集,再用集覆盖的思路来选择特征差异大的样本;
- 是2的扩展,通过在梯度嵌入空间聚类来选样本,从而避开人工给定候选样本集大小的问题。
6.1 信息论思路
第一种从理论上来看很优雅,从信息论的角度推出怎么在批量选择的场景里选到对模型参数改善最有效的一组样本。但计算复杂度很高,可能并不是很实用,该论文中的实验部分也都是在很小的数据集上完成的。
6.2 构建候选集+大差异样本——SA
这类方法实现起来最简单,非常启发式。整个主动学习分两步来做,第一步先用不确定性(熵,BALD等)选超出主动学习budget size的候选样本集,在用多样性的方法,选择能最好覆盖这个候选集的一组样本。
SA用Bootstrapping训练若干个模型,用这些模型预测的variance来表示不确定性,之后再用候选集中样本特征相似度来选取与已经选到的样本差异最大的样本,就类似coreset-greedy的做法。
CoreLog基于Proper Scoring Rules给了表示不确定性的度量,先选出不确定性大的前k%个样本,再用kmeans聚类来选择多样的样本。
这种结合的方式没毛病,但有个小的问题,很难说清咋确定这个候选集大小,到底多大能算作高不确定性,能丢到候选集里。
6.3 梯度嵌入空间——badge
badge和第二类方法的思路很像,不确定性的用模型参数就某个样本的梯度大小来表示,多样性用kmeans++来保证。但这个方法很巧妙的地方在于,通过把这个问题丢到梯度嵌入空间来做(而不像第二类方法在样本的特征空间保证多样性),使样本的多样性和不确定性能同时得到保证。
梯度范数大小表示不确定性很好理解,和之前用熵之类的指标来表示不确定性类似,模型预测的概率小,意味着熵大,也意味着如果把这样本标了,模型要有较大的变化才能拟合好这个样本,也就是求出来的梯度大。梯度表示多样性,是这类方法的独特之处,用梯度向量来聚类,选到的差异大的样本就变成:让模型参数的更新方向不同的样本,而不是样本特征本身不同。
在用梯度表示了不确定性和多样性之后,怎么来选一批既有高不确定性,又不同的样本呢?badge的做法是Kmeans++聚类,第一个样本选梯度范数最大的样本,之后依据每个样本梯度与选到的样本梯度的差的范数来采样新的样本。这里注意这个差是两个向量的差,所以自然的避免了重复的选到梯度方向接近且范数都比较大的一组样本。
7 基于变化最大的方法
这一类方法核心的观点是,不管不确定性或多样性,而是希望选出的样本能使模型产生的变化最大。变化最大可以着眼于loss最大,也可以关注梯度的情况,比如梯度范数大小。
learning loss在任务模型上加一个小的附属子网络用来学习预测样本的损失值。训练任务模型的时候,也同时训练这个预测损失模块,之后就用这个模块来预测对哪个未标注样本的损失大,就选他。整个算法的流程图如下

损失预测模块的结构和损失计算方法如下:

参考文献
- 基于batch不确定性(MCDropout & BatchBALD)
- 论文阅读 Variational Adversarial Active Learning
- 主动学习active learning(一)——基于batch不确定性(MCDropout & BatchBALD)
- 主动学习active learning(二)——来自分类器和OOD样本的影响
- 主动学习active learning(三)——特征空间覆盖(coreset, bilevel coreset, bayesian coreset)
- 主动学习active learning(四)——基于对抗的方法(GAAL,BGADL,VAAL, ARAL)
- 主动学习Active learning(五)——融合不确定性和多样性(SA, BADGE)
- 主动学习Active learning(六)——基于变化最大(Learning loss, Grad_norm)