文章目录
- 前言
- The Box–Muller transform
- The Ziggurat algorithm(金字形神塔)
- 附录:Inverse transform sampling直观解释
前言
在Monte Carlo模拟技术中,许多地方都需要用到符合标准正态分布(高斯)的随机数来设计采样方案,因此了解如何用均匀分布随机数(实际上是均匀分布的伪随机数)来生成标准正态分布的随机数十分重要。本文将对这个最基本的问题做讨论,并提供c++11代码。
在讨论更高效的算法之前,我们先来看看能不能基于中心极限定理来设计算法。中心极限定理告诉我们,对于一组 i . i . d i.i.d i.i.d的随机数 { x k } ∼ U ( μ , σ 2 ) \{x_k\}\sim U(\mu,\sigma^2) {xk}∼U(μ,σ2),有 1 n ∑ i = 1 n x i → N ( μ , σ 2 / n ) \frac{1}{n}\sum_{i=1}^n x_i \rightarrow N(\mu,\sigma^2/n) n1∑i=1nxi→N(μ,σ2/n)。这个算法有两个问题:
- 计算量大。生成一个数需要用n个均匀分布随机数。
- 无法准确刻画正态分布的末端效应。生成的数均有界,不会是很大的数。
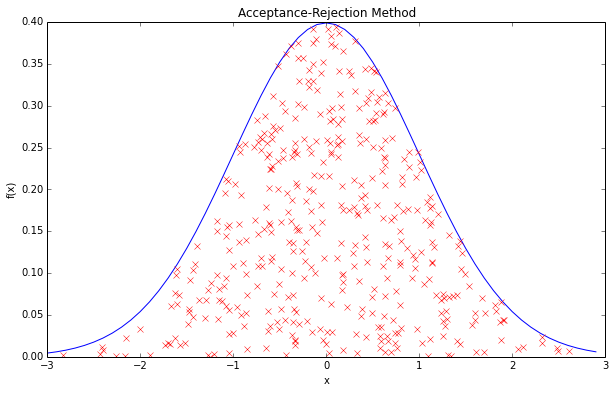
此外,如果用“拒绝采样(rejection sampling)“的思路,在覆盖 f ( x ) = c e − x 2 / 2 f(x)=ce^{-x^2/2} f(x)=ce−x2/2的矩形内均匀投点,保留曲线下的点,则计算较复杂(exp函数),而且舍弃点多代价大。
我们下面介绍两种更高效的算法:The Box–Muller transform 和 The Ziggurat algorithm。它们一个是对分布函数做了变换,另一个还是使用了“拒绝采样“的思路,但并不是简单的仅用一个大矩形覆盖。
The Box–Muller transform
The Box–Muller transform 把一对均匀分布随机数映射到一对标准正态分布随机数。它有两种形式:
- 基本形式:用 ( 0 , 1 ) (0,1) (0,1)均匀分布随机数,需要计算三角函数 sin \sin sin和 cos \cos cos;
- 极坐标形式:用 ( − 1 , 1 ) (-1,1) (−1,1)均匀分布随机数,且不需要计算三角函数。
我们希望计算积分 I = ∫ − ∞ ∞ e − x 2 / 2 d x I=\int_{-\infty}^{\infty}e^{-x^2/2}dx I=∫−∞∞e−x2/2dx,可以先取它的平方并用极坐标表示, I 2 = ∫ − ∞ ∞ ∫ − ∞ ∞ e − ( x 2 + y 2 ) / 2 d x d y = ∫ 0 2 π ∫ 0 ∞ r e r 2 / 2 d r d θ . I^2=\int_{-\infty}^{\infty}\int_{-\infty}^{\infty}e^{-(x^2+y^2)/2}dxdy=\int_{0}^{2\pi}\int_{0}^{\infty}re^{r^2/2}drd\theta. I2=∫−∞∞∫−∞∞e−(x2+y2)/2dxdy=∫02π∫0∞rer2/2drdθ.可以看到极角 θ \theta θ服从 ( 0 , 2 π ) (0,2\pi) (0,2π)均匀分布,径向距离 r r r服从 r e r 2 / 2 re^{r^2/2} rer2/2分布函数(即 r 2 r^2 r2服从 χ 2 分 布 \chi^2分布 χ2分布)。如果把 r r r的累积分布函数(cumulative distribution function)写出来 F ( x ) = ∫ 0 x r e r 2 / 2 d r = 1 − e − x 2 / 2 , F(x)=\int_0^xre^{r^2/2}dr=1-e^{-x^2/2}, F(x)=∫0xrer2/2dr=1−e−x2/2,我们就可以通过 F F F的逆函数 F − 1 ( u ) F^{-1}(u) F−1(u),将均匀分布 u ∼ U ( 0 , 1 ) u\sim U(0,1) u∼U(0,1)映射到目标分布,即 x = − 2 ln ( 1 − u ) x=\sqrt{-2\ln (1-u)} x=−2ln(1−u),也等价于 x = − 2 ln u x=\sqrt{-2\ln u} x=−2lnu (注意到如果 u ∼ U ( 0 , 1 ) u\sim U(0,1) u∼U(0,1),那么 1 − u 1-u 1−u也是)。
基本形式:
假设 U 1 U_1 U1和 U 2 U_2 U2是区间 ( 0 , 1 ) (0,1) (0,1)上的均匀分布随机数,令
Z 1 = R cos ( θ ) = − 2 ln U 1 cos ( 2 π U 2 ) Z_1=R\cos(\theta)=\sqrt{-2\ln U_1}\cos(2\pi U_2) Z1=Rcos(θ)=−2lnU1cos(2πU2),
Z 2 = R sin ( θ ) = − 2 ln U 1 sin ( 2 π U 2 ) Z_2=R\sin(\theta)=\sqrt{-2\ln U_1}\sin(2\pi U_2) Z2=Rsin(θ)=−2lnU1sin(2πU2),
则 Z 1 Z_1 Z1和 Z 2 Z_2 Z2是两个独立的标准正态分布随机变量。
极坐标形式:
转换到极坐标的方法叫做Marsaglia polar method。该方法对水平和竖直方向 ( − 1 , 1 ) (-1,1) (−1,1)正方形区域内均匀投点,把落在单位圆内的点 ( x , y ) (x,y) (x,y)通过 s = x 2 + y 2 s=x^2+y^2 s=x2+y2映射到单位圆周上,即 ( x s , y s ) (\frac{x}{\sqrt{s}},\frac{y}{\sqrt{s}}) (sx,sy),这样就可以不用计算三角函数。由于 s ≡ r 2 s\equiv r^2 s≡r2独立于极角,且在区间 ( 0 , 1 ) (0,1) (0,1)上均匀分布(因为 ∫ ∫ d x d y = ∫ ∫ r d r d θ = ∫ ∫ 1 2 d r 2 d θ \int\int dxdy=\int\int rdrd\theta=\int\int \frac{1}{2}dr^2d\theta ∫∫dxdy=∫∫rdrdθ=∫∫21dr2dθ),因此可以用这个 s s s继续得到径向距离 − 2 ln ( s ) \sqrt{-2\ln(s)} −2ln(s)。于是我们有:
Z 1 = − 2 ln U 1 cos ( 2 π U 2 ) = − 2 ln s ( u s ) = u ⋅ − 2 ln s s , Z_1=\sqrt{-2\ln U_1}\cos(2\pi U_2)= \sqrt{-2 \ln s} \left(\frac{u}{\sqrt{s}}\right) = u \cdot \sqrt{\frac{-2 \ln s}{s}}, Z1=−2lnU1cos(2πU2)=−2lns(su)=u⋅s−2lns,
Z 2 = − 2 ln U 1 sin ( 2 π U 2 ) = − 2 ln s ( v s ) = v ⋅ − 2 ln s s . Z_2=\sqrt{-2\ln U_1}\sin(2\pi U_2)= \sqrt{-2 \ln s}\left( \frac{v}{\sqrt{s}}\right) = v \cdot \sqrt{\frac{-2 \ln s}{s}}. Z2=−2lnU1sin(2πU2)=−2lns(sv)=v⋅s−2lns.
极坐标形式对应的c++代码如下(顺带说一下,c++标准函数库libstdc++里std::normal_distribution用的就是Marsaglia polar method,见这里):
//
// Marsaglia polar method. C++11 代码
// 由于生成的是一对i.i.d.高斯变量,每次生成的两个样本都可以利用起来!
//
bool _M_saved_available=false;
if (_M_saved_available) //输出下面暂时储存的x*mult
{_M_saved_available = false;return = _M_saved;
}
else
{double x, y, r2;do{x = 2.0 * rand() - 1.0;y = 2.0 * rand() - 1.0;r2 = x * x + y * y;}while (r2 > 1.0 || r2 == 0.0);const double mult = std::sqrt(-2 * std::log(r2) / r2);_M_saved = x * mult;_M_saved_available = true; //暂时储存x*mult,输出y*multreturn = y * mult;
}
算法局限性: 尾部截断(Tails truncation)
由于计算机有数值精度限制,其表示的数字不可能无线接近0。比如,使用32bit精度,那么最接近0的数字是 2 − 32 2^{-32} 2−32。因此,当 u 1 u_1 u1和 u 2 u_2 u2都取 2 − 32 2^{-32} 2−32时, x x x的最大值是 − 2 ln ( 2 − 32 ) cos ( 2 − 32 ) ≈ 6.6 \sqrt{-2\ln(2^{-32})}\cos(2^{-32})\approx6.6 −2ln(2−32)cos(2−32)≈6.6,即产生的随机数最大不会超过 6.6 6.6 6.6个标准差,这意味着会有 2 × 1 0 − 11 2×10^{-11} 2×10−11的比例(尾部)会因为计算机精度问题无法采样到,这在大规模生成高斯随机数和研究rare events的时候要特别注意。
The Ziggurat algorithm(金字形神塔)
The Ziggurat algorithm 属于rejection sampling的一种。这个方法适用于分布函数是单调递减的情况,而正态分布的正半轴就属于这种情况。

附录:Inverse transform sampling直观解释
数学解释: 假设 F ( x ) = P r [ X < x ] F(x)=Pr[X<x] F(x)=Pr[X<x]是CDF,并假设 u ∼ U ( 0 , 1 ) u\sim U(0,1) u∼U(0,1),定义映射 X = f ( x ) X=f(x) X=f(x),这个映射是 [ 0 , 1 ] → R [0,1]\rightarrow R [0,1]→R。我们希望找到一个映射使得 X X X恰好服从 F ( x ) F(x) F(x)的CDF分布,即 P r [ f ( U ) < x ] = F ( x ) Pr[f(U)<x]=F(x) Pr[f(U)<x]=F(x)。显然, f = F − 1 f=F^{-1} f=F−1,因为 P r [ X < x ] = P r [ f ( u ) < x ] = P r [ u < F ( x ) ] = F ( x ) Pr[X<x]=Pr[f(u)<x]=Pr[u<F(x)]=F(x) Pr[X<x]=Pr[f(u)<x]=Pr[u<F(x)]=F(x)。
图像解释: 我们假设随机变量取值是离散的,比如一共有5种取值。右边是CDF,相当于把左边的概率“盒子“逐渐堆积起来,直到最后一列对应的 F F F正好等于1。这时候对 F ( x ) F(x) F(x)均匀采样的话,相当于在最后一列按照各个盒子面积的相对大小(各部分的概率大小)来采样, F ( x ) F(x) F(x)的逆函数只是用来回溯到对应的 x x x而已。随机变量取连续情况同样适用上述论证过程。

[1]:
[2]: https://github.com/jmcmanus/pagedown-extra “Pagedown Extra”
[3]: http://meta.math.stackexchange.com/questions/5020/mathjax-basic-tutorial-and-quick-reference
[4]: http://bramp.github.io/js-sequence-diagrams/
[5]: http://adrai.github.io/flowchart.js/
[6]: https://github.com/benweet/stackedit