1. ray库介绍
金融、工程模型需要大量使用 Pandas 和 Numpy 来做矩阵计算,需要针对 Pandas/Numpy 有更好的支持,ray库就是其中一种可以加速计算的框架。
Ray 有如下特点:
- 分布式异步调用
- 内存调度
- Pandas/Numpy 的分布式支持
- 支持 Python
- 整体性能出众
2. ray安装
电脑是win10+python3.7.3,安装ray库,下面的顺序不能错
pip install -i https://mirrors.aliyun.com/pypi/simple/pytest-runner
pip install -i https://mirrors.aliyun.com/pypi/simple/ray
3. 初步使用的基本形式
# 导入ray,并初始化执行环境
import ray
ray.init()# 定义ray remote函数
@ray.remote
def hello():return "Hello world !"# 异步执行remote函数,返回结果id
object_id = hello.remote()# 同步获取计算结果
hello = ray.get(object_id)# 输出计算结果
print hello4. 测试一个简单的例子
使用ray库计算100次的延迟1秒
import ray
import time
import numpy as np# 启动Ray.
ray.init()
#定义remote函数
@ray.remote
def sleep1(n):time.sleep(n)#程序开始时的时间
time_start=time.time()result_ids = []
for i in range(100):#异步执行remote函数sleep1.remote(1)#程序结束时系统时间
time_end=time.time()
#两者相减
print('totally cost',time_end-time_start)
#print(z_id)
不使用ray库计算100次的延迟1秒
import time
import numpy as npdef sleep1(n):time.sleep(n)#程序开始时的时间
time_start=time.time()
result_ids = []
for i in range(100):sleep1(1)#程序结束时系统时间
time_end=time.time()
#两者相减
print('totally cost',time_end-time_start)
#print(z_id)

5. 系统架构
作为分布式计算系统Ray仍旧遵循了典型的Master-Slave的设计,Master负责全局协调和状态维护;Slave执行分布式计算任务。不过和传统的分布式计算系统不同的是Ray使用了混合任务调度的思路。
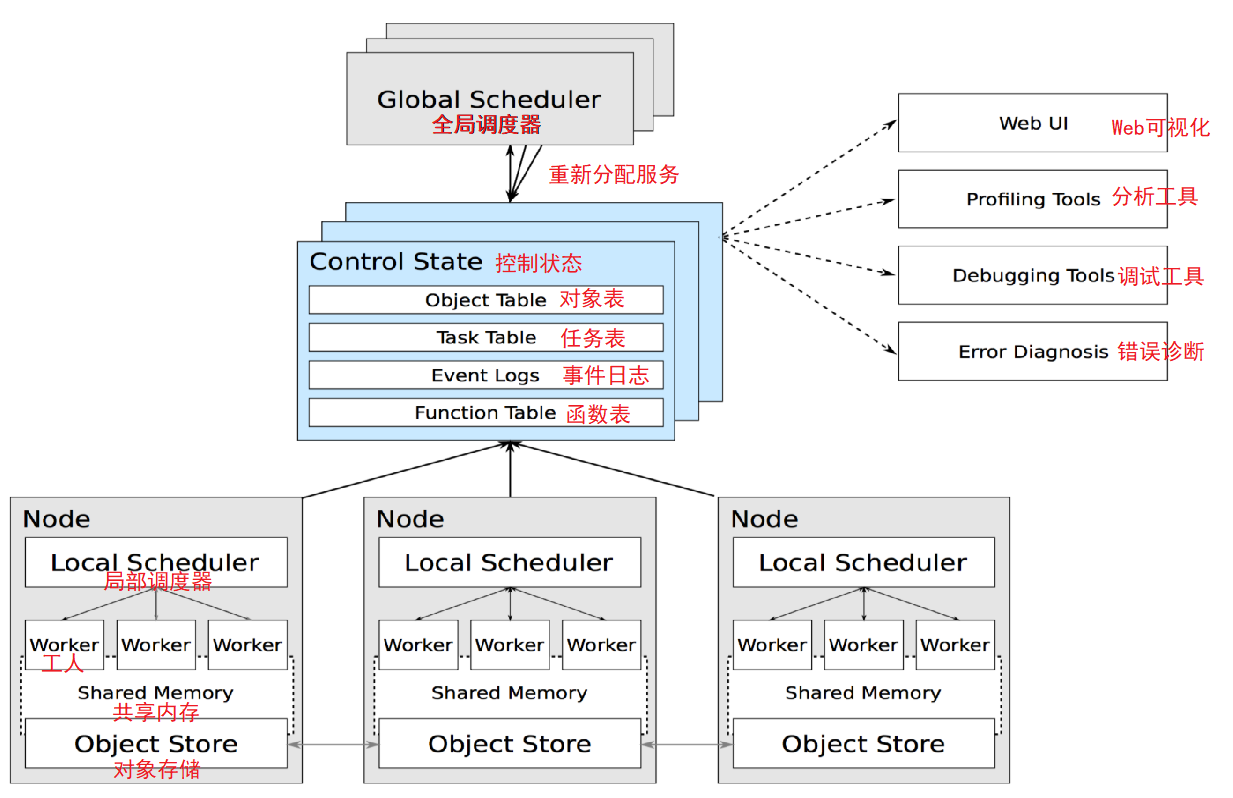
在集群部署模式下Ray启动了以下关键组件:
- GlobalScheduler(全局调度器)— Master上启动一个全局调度器用于接收本地调度器提交的任务;并将任务分发给合适的本地任务调度器执行。
- RedisServer Master(重新分配任务)— 启动一到多个RedisServer用于保存分布式任务的状态信息(Control State),包括对象机器的映射、任务描述、任务debug信息等。
- LocalScheduler(局部调度器)— 每个Slave上启动一个本地调度器,用于提交任务到全局调度器,以及分配任务给当前机器的Worker进程。
- Worker(工人)— 每个Slave上可以启动多个Worker进程执行分布式任务;并将计算结果存储到ObjectStore。
- ObjectStore(对象存储)— 每个Slave上启动一个ObjectStore存储只读数据对象;Worker可以通过共享内存的方式访问这些对象数据;这样可以有效地减少内存拷贝和对象序列化成本,ObjectStore底层由Apache Arrow实现。
- Plasma — 每个Slave上的ObjectStore都由一个名为Plasma的对象管理器进行管理;它可以在Worker访问本地ObjectStore上不存在的远程数据对象时主动拉取其它Slave上的对象数据到当前机器。
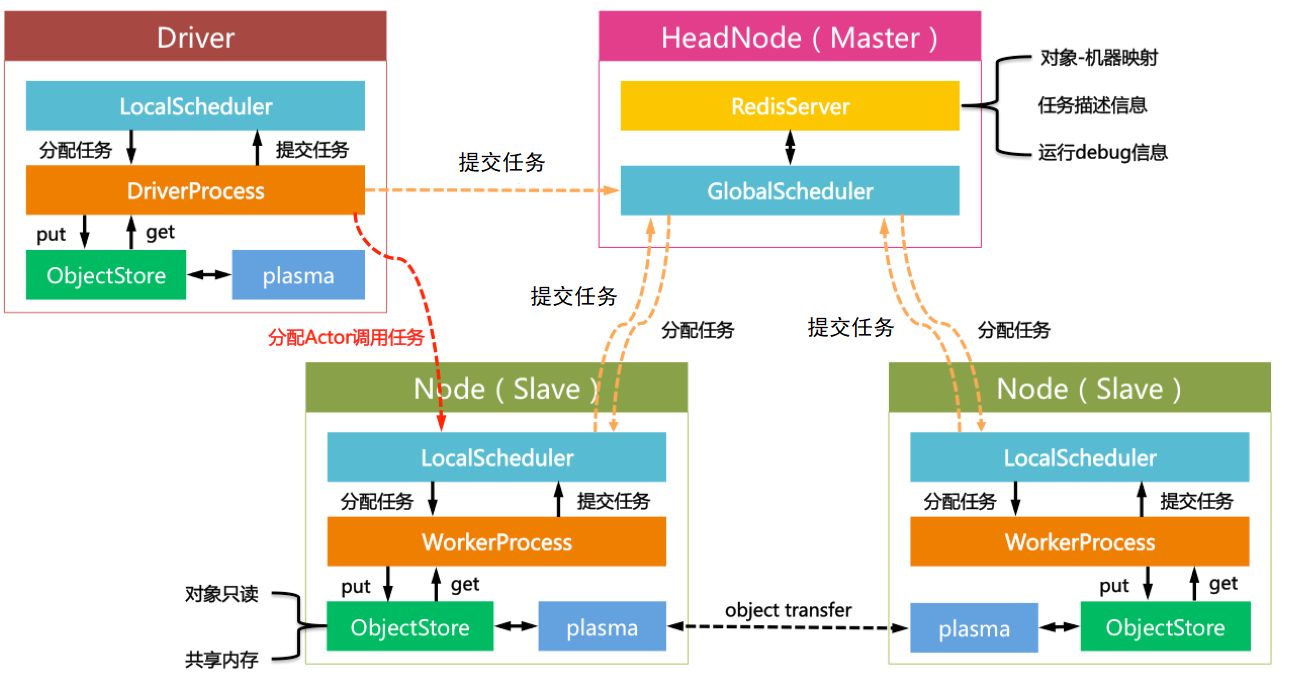
Ray的Driver节点和和Slave节点启动的组件几乎相同;不过却有以下区别:
- Driver上的工作进程DriverProcess一般只有一个,即用户启动的PythonShell;Slave可以根据需要创建多个WorkerProcess。
- Driver只能提交任务却不能来自全局调度器分配的任务。Slave可以提交任务也可以接收全局调度器分配的任务。
- Driver可以主动绕过全局调度器给Slave发送Actor调用任务(此处设计是否合理尚不讨论);Slave只能接收全局调度器分配的计算任务。
6. ray基础(待补充)
- ray.init() 启动ray
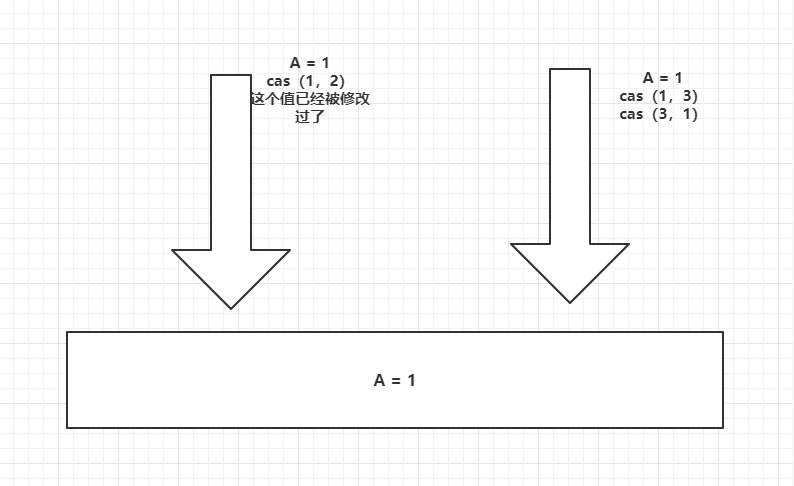
- ray.put(x) 获取一个对象的ID
- ray.get(x_id) 接受一个对象ID,并从相应的远程对象创建一个Python对象。
result_ids = [ray.put(i) for i in range(10)]
ray.get(result_ids) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
ray.get(result_ids[5]) # 5
ray.get(result_ids[1]) # 1
- Ray的异步计算:可以执行任意Python函数
"远程函数"
@ray.remote #在普通函数基础上添加@ray.remote
def add2(a, b):return a + b
x_id = add2.remote(1, 2)
ray.get(x_id) # 3
- 远程函数:不返回实际值,它们总是返回对象ID,返回的对象ID可以是多个。
- ray.error_info() 可以获取任务执行时产生的错误信息。
- ray.wait() 支持批量的任务等待
# 启动5个remote函数调用任务
results = [f.remote(i) for i in range(5)]
# 阻塞等待4个任务完成,超时时间为2.5s
ready_ids, remaining_ids = ray.wait(results, num_returns=4, timeout=2500)
上述例子中,results包含5个ObjectID,使用ray.wait()操作可以一直等待有4个任务完成后返回;并将完成的数据对象放在第一个list类型返回值内;未完成的ObjectID放在第二个list返回值内。如果设置了超时时间;那么在超时时间结束后仍未等到预期的返回值个数;则已超时完成时的返回值为准。
-
动态任务图:Ray应用程序或作业中的基础基元是一个动态任务图,这与TensorFlow中的计算图非常不同,TensorFlow中一个计算图代表一个神经网络,并且在单个应用程序中执行多次。 在Ray中任务图代表整个应用程序;并且只执行一次,任务图不是事先知道的,是在应用程序运行时动态构建的,执行一个任务可能会触发创建更多任务。
-
任务之间的依赖关系:下面的第二个任务在第一个任务完成之前不会执行,第三个任务在第二个任务完成之前不会执行。在这个例子中,没有体现并行,体现的是任务之间的依赖关系。
@ray.remote
def f(x):return x + 1
x = f.remote(0)
y = f.remote(x)
z = f.remote(y)
ray.get(z) # 3
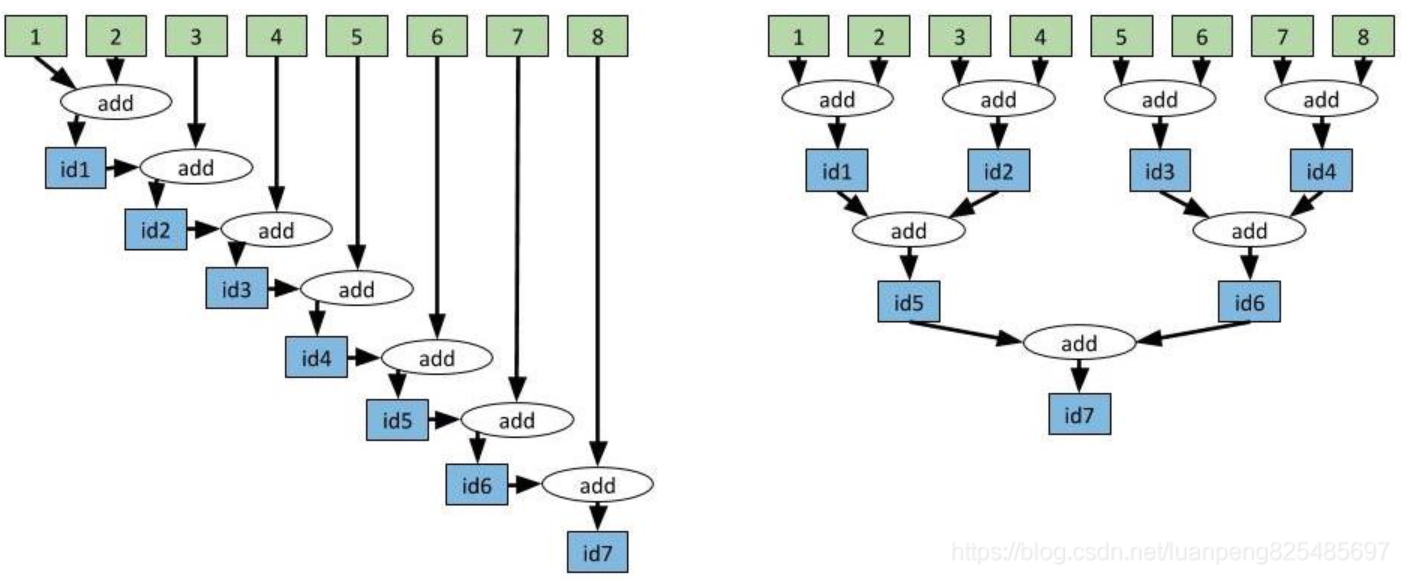
- 有效的聚合函数:左边是线性聚合方式,右边是树型聚合方式。
代码实现:
import time
import ray
@ray.remote
def add(x, y):time.sleep(1)return x + y
"====================线性聚合,时间复杂度O(n) ========================="
id1 = add.remote(1, 2)
id2 = add.remote(id1, 3)
id3 = add.remote(id2, 4)
id4 = add.remote(id3, 5)
id5 = add.remote(id4, 6)
id6 = add.remote(id5, 7)
id7 = add.remote(id6, 8)
result = ray.get(id7)
"===================树型聚合,时间复杂度 O(log(n))======================"
id1 = add.remote(1, 2)
id2 = add.remote(3, 4)
id3 = add.remote(5, 6)
id4 = add.remote(7, 8)
id5 = add.remote(id1, id2)
id6 = add.remote(id3, id4)
id7 = add.remote(id5, id6)
result = ray.get(id7)
- Actor待补充。
目前参考资源:
https://blog.csdn.net/weixin_43255962/article/details/88689665
https://blog.csdn.net/luanpeng825485697/article/details/88242020