Logstash 是 Elastic 技术栈中的一个技术,它是一个数据采集引擎,可以从数据库采集数据到 ES 中。可以通过设置 自增 ID 主键 或 更新时间 来控制数据的自动同步:
- 自增 ID 主键:Logstatsh 会有定时任务,如果发现有主键的值大于先前同步记录的主键值,就会将对应的增量数据同步到 ES 中
- 更新时间:其实原理与主键类似,不过如果设置使用主键作为依据的话,那么数据库的数据更新就不会被识别从而更新到 ES 中。
一、安装
1. 下载地址:https://www.elastic.co/cn/downloads/past-releases#logstash
- 注:使用Logstatsh的版本号与elasticsearch版本号需要保持一致
2. 上传并解压
先上传到服务器 /home/software/ 下,然后解压,并将解压后的文件夹移动到 /usr/local/ 下
tar -zxvf logstash-7.6.2.tar.gzmv logstash-7.6.2 /usr/local/二、配置
1. 首先在 Elasticsearch 中创建一个索引:didiok-items
2. 在 /usr/local/logstash-7.6.2/ 下创建文件夹 sync/
将数据库驱动 mysql-connector-java-5.1.41.jar 包上传到 /usr/local/logstash-7.6.2/sync/ 下,
cd /usr/local/logstash-7.6.2/
mkdir sync
cd sync/

3. 编写数据同步的SQL脚本
SELECTi.id as id,i.item_name as itemName,i.sell_counts as sellCounts,ii.url as imgUrl,tempSpec.price_discount as price,i.updated_time as updated_timeFROMitems iLEFT JOINitems_img iioni.id = ii.item_idLEFT JOIN(SELECT item_id,MIN(price_discount) as price_discount from items_spec GROUP BY item_id) tempSpeconi.id = tempSpec.item_idWHEREii.is_main = 1andi.updated_time >= :sql_last_value# :sql_last_value 是 logstash 每次同步完成之后保存的的边界值,这里保存的是 updated_time ,用于下次数据同步时,大于等于 updated_time 的数据才会进行同步将sql脚本 保存到 /usr/local/logstash-7.6.2/sync/didiok-items.sql 文件中
4. 在 sync/ 下创建 配置文件 logstash-db-sync.conf,内容如下:
input {jdbc {# 设置 MySql/MariaDB 数据库url以及数据库名称jdbc_connection_string => "jdbc:mysql://192.168.1.6:3306/didiok-shop-dev?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true"# 用户名和密码jdbc_user => "root"jdbc_password => "root"# 数据库驱动所在位置,可以是绝对路径或者相对路径jdbc_driver_library => "/usr/local/logstash-7.6.2/sync/mysql-connector-java-5.1.41.jar"# 驱动类名jdbc_driver_class => "com.mysql.jdbc.Driver"# 开启分页jdbc_paging_enabled => "true"# 分页每页数量,可以自定义jdbc_page_size => "10000"# 执行的sql文件路径statement_filepath => "/usr/local/logstash-7.6.2/sync/didiok-items.sql"# 设置定时任务间隔 含义:分、时、天、月、年,全部为*默认含义为每分钟跑一次任务schedule => "* * * * *"# 索引类型type => "_doc"# 是否开启记录上次追踪的结果,也就是上次更新的时间,这个会记录到 last_run_metadata_path 的文件use_column_value => true# 记录上一次追踪的结果值last_run_metadata_path => "/usr/local/logstash-7.6.2/sync/track_time"# 如果 use_column_value 为true, 配置本参数,追踪的 column 名,可以是自增id或者时间tracking_column => "updated_time"# tracking_column 对应字段的类型tracking_column_type => "timestamp"# 是否清除 last_run_metadata_path 的记录,true则每次都从头开始查询所有的数据库记录clean_run => false# 数据库字段名称大写转小写lowercase_column_names => false}
}
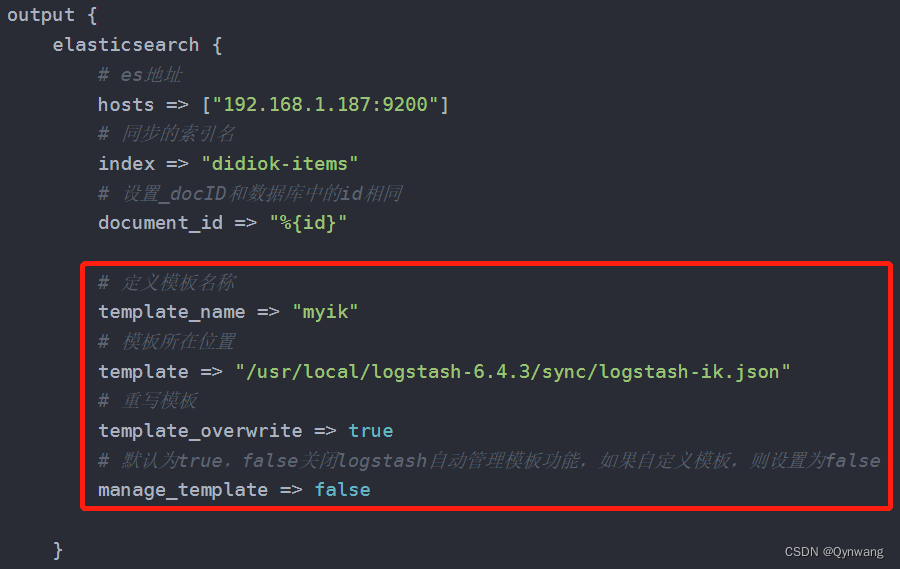
output {elasticsearch {# es地址hosts => ["192.168.1.187:9200"]# 同步的索引名index => "didiok-items"# 设置_docID和数据库中的id相同document_id => "%{id}"}# 日志输出stdout {codec => json_lines}}
5. 启动 logstash
cd /usr/local/logstash-7.6.2/bin./logstash -f /usr/local/logstash-7.6.2/sync/logstash-db-sync.conf
如果启动过程中报错如下:

报这个错是虚拟机内存不足,是因为这个Logstash要的内存太大了。这个插件在初始化的时候要了一个g的内存,但是虚拟机没有这么多的内存,所以把这个内存改小就行了。
(!!!但是,这样好像会导致 logstash 启动不了,还是想办法扩大内存吧 ,下面的方法仅供参考)
修改 /usr/local/logstash-7.6.2/config/jvm.options ,这里原来是 1g,修改成 256m:

三、在自定义模板中配置中文分词器
首先在 ES 中创建索引 didiok-items,之后启动 logstash,然后再进行以下操作。
1. 查看Logstash默认模板
请求方式:GET
路径:http://localhost:9200/_template/logstash
2. 将查询出来的模板复制出来,进行修改如下(这里只修改了3处):
{"order": 0,"version": 1, # 修改1"index_patterns": ["*"], # 修改2"settings": {"index": {"refresh_interval": "5s"}},"mappings": {"_default_": {"dynamic_templates": [{"message_field": {"path_match": "message","match_mapping_type": "string","mapping": {"type": "text","norms": false}}},{"string_fields": {"match": "*","match_mapping_type": "string","mapping": {"type": "text","norms": false,"analyzer": "ik_max_word", # 修改3 加入中文分词器"fields": {"keyword": {"type": "keyword","ignore_above": 256}}}}}],"properties": {"@timestamp": {"type": "date"},"@version": {"type": "keyword"},"geoip": {"dynamic": true,"properties": {"ip": {"type": "ip"},"location": {"type": "geo_point"},"latitude": {"type": "half_float"},"longitude": {"type": "half_float"}}}}}},"aliases": {}
}之后将其保存为 /usr/local/logstash-7.6.2/sync/logstash-ik.json
3. 在 /usr/local/logstash-7.6.2/sync/logstash-db-sync.conf 文件中进行修改,加入以下内容:
# 定义模板名称
template_name => "myik"
# 模板所在位置
template => "/usr/local/logstash-7.6.2/sync/logstash-ik.json"
# 重写模板
template_overwrite => true
# 默认为true,false关闭logstash自动管理模板功能,如果自定义模板,则设置为false
manage_template => false
4. 重新运行Logstash进行同步
./logstash -f /usr/local/logstash-7.6.2/sync/logstash-db-sync.conf
中文分词器没有设置成功?
试试下面的解决方案:
先通过postman请求 http://192.168.1.187:9200/_template/logstash,获取的json放入logstash-ik.json中,然后在 /usr/local/logstash-7.6.2/sync/logstash-db-sync.conf 文件中设置manage_template => true,然后启动logstash,启动后 ES 的 didiok-items 索引是不正确的。
删除索引,并重新创建索引 didiok-items。
然后 postman 调 http://192.168.1.187:9200/_template/myik 拿到的 myik 的 json 重新放入logstash-ik.json中,配置 logstash-db-sync.conf 改为 manage_template => false,
再次启动logstash就能在 didiok-items 的mapping中显示中文分词器了。