前言
对于一些库的说明
numpy:支持矩阵运算,在矩阵运算这方面可以完全替代基于向量编程的matlab
pandas:这个是一个数据存储库,是以表单(dataframe)为基本单位,这个库的好处在于行列
索引并不是规定死的0和1(numpy就是规定死了的,numpy是以矩阵作为基本单位),索引可以改为文字
数字等符号,灵活性很好
scipy:一个科学运算的库,里面封装了很多科学计算的模块
statsmodels:这是一个包含很多统计模型的库,这个是统计学学生最常用的库了
前面这四个库是回归课程里面最常用的库,当然这门课程要求的编程能力不高,主要掌握应用回归的
内核即可,毕竟现在很多软件都能做应用回归,甚至比python更方便
案例
对于森林火灾数据进行线性回归分析
import numpy as np
import statsmodels.api as sm
import statsmodels.formula.api as smf
import matplotlib.pyplot as plt
import pandas as pd
from patsy import dmatrices#patsy.dmatrices把数据按要求分割
from statsmodels.stats.api import anova_lm#anova_lm计算方差
import scipy# Load data
df = pd.read_csv('C:/Users/33035/Desktop/data2.1.csv')
df.head(15)#显示所有列
pd.set_option('display.max_columns',None)#显示所有行
pd.set_option('display.max_rows', None)#设置value的显示长度为100,默认为50
pd.set_option('max_colwidth',200)# 计算相关系数
cor_matrix = df.corr(method='pearson') # 使用皮尔逊系数计算列与列的相关性
#cor_matrix = df.corr(method='kendall')使用Kendall计算算列与列的相关性
#cor_matrix = df.corr(method='spearman')使用spearman计算列与列的相关性
print(cor_matrix)#answer
x y x 1.000000 0.960978 y 0.960978 1.000000
#一元线性回归建模(最小二乘法)
# ==========第一种建模方式======================================
# y,X = dmatrices('y~x', data=df, return_type = 'dataframe')
# print(X)
# mod = sm.OLS(y,X)
# result = mod.fit()
# ==========第二种建模方式(类R语言方式)======================================
result = smf.ols('y~x', data=df).fit()
#值得注意的是:'y是因变量对于x自变量,数据是df中的数据,
进行ols(最小二乘法)来进行线性回归拟合,自变量与因变量的符号要与df中的符号一致,
不然无法定位数据'
print(result.summary())#summary摘要,
注意的是在进行ols返回的结果已经把线性回归中所需要的计算量都已经计算好了,
存在result里面,现在把概要以表单形式返回 OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.923
Model: OLS Adj. R-squared: 0.918
Method: Least Squares F-statistic: 156.9
Date: Wed, 28 Sep 2022 Prob (F-statistic): 1.25e-08
Time: 16:46:19 Log-Likelihood: -32.811
No. Observations: 15 AIC: 69.62
Df Residuals: 13 BIC: 71.04
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [95.0% Conf. Int.]
------------------------------------------------------------------------------
Intercept 10.2779 1.420 7.237 0.000 7.210 13.346
x 4.9193 0.393 12.525 0.000 4.071 5.768
==============================================================================
Omnibus: 2.551 Durbin-Watson: 1.318
Prob(Omnibus): 0.279 Jarque-Bera (JB): 1.047
Skew: -0.003 Prob(JB): 0.592
Kurtosis: 1.706 Cond. No. 9.13
==============================================================================
# 注解
Intercept:截距,对应于p0 x:x前的系数,对应于p1 coef:p0 p1 系数估计值 t分布:看p值与0.05比较 conf int:参数估计的置信区间
Intercept:截距,对应于p0
x:x前的系数,对应于p1
coef:p0 p1 系数估计值
t分布:看p值与0.05比较
conf int:参数估计的置信区间'
y_fitted = result.fittedvalues#把拟合曲线上的y值调出来print(y_fitted)0 27.003653 1 19.132724 2 32.906850 3 21.592389 4 25.527854 5 37.334248 6 13.721460 7 25.035921 8 23.068188 9 31.431051 10 20.608523 11 15.689192 12 40.285846 13 33.890716 14 28.971385 dtype: float64
#画图(线性回归)
fig, ax = plt.subplots(figsize=(8, 6))#fig是画布,ax是坐标系
ax.plot(df['x'], df['y'], 'o', label='data')
ax.plot(df['x'], y_fitted, 'r-', label='OLS')
ax.legend(loc='best')
plt.show()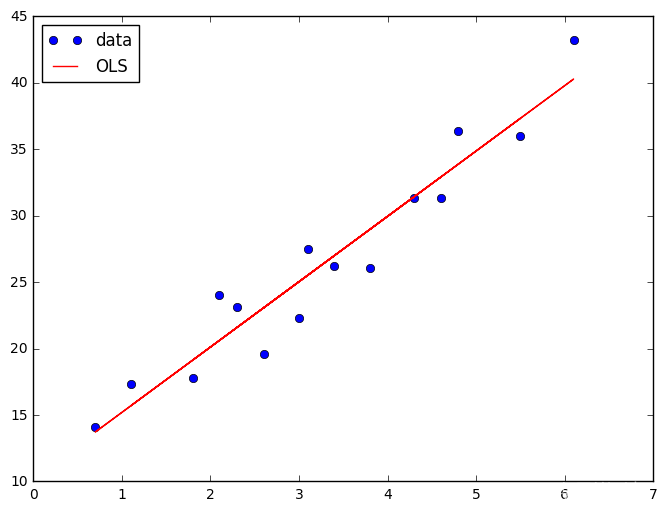
# 方差分析(F检验:对整个模型进行分析,看P值<0.05)
table = anova_lm(result, typ=2)#对于结果进行方差分析即可,
会自动匹配到result对应的估计值与实际值 、均值等所需数据print(table)sum_sq df F PR(>F) x 841.766358 1.0 156.88616 1.247800e-08 Residual 69.750975 13.0 NaN NaN
# pearson相关系数检验(看x与y的相关性程度:这一步感觉放在回归前更好)
cortest = scipy.stats.pearsonr(df['x'], df['y'])
print(cortest)(0.96097771513210861, 1.2478000079204785e-08)
# 计算残差(比3大的就是异常值)
eres = result.resid
print(eres)0 -0.803653 1 -1.332724 2 -1.606850 3 1.507611 4 1.972146 5 -1.334248 6 0.378540 7 -2.735921 8 -3.468188 9 -0.131051 10 3.391477 11 1.610808 12 2.914154 13 2.509284 14 -2.871385 dtype: float64
# 标准化残差(找比3大的就是异常值)
stand_eres = eres / np.sqrt(result.scale) # eres.std()
print(stand_eres)0 -0.346949 1 -0.575356 2 -0.693700 3 0.650857 4 0.851404 5 -0.576014 6 0.163421 7 -1.181136 8 -1.497267 9 -0.056576 10 1.464149 11 0.695409 12 1.258082 13 1.083294 14 -1.239618 dtype: float64
# 学生化残差(找比3大的就是异常值)
infl = result.get_influence()#学生化残差已经算好存在result中,只需要调用即可
# studentied_eres = infl.summary_table()
studentied_eres = infl.resid_studentized_internal
print(studentied_eres)[-0.35920557 -0.61671822 -0.7381288 0.68389288 0.88172686 -0.647391550.18972092 -1.2240712 -1.56097482 -0.05952374 1.54912299 0.779095721.49866138 1.16347978 -1.28850409]
#置信区间(想看参数估计的置信区间,这里的做法好在我可以调alpha)
confinterval = result.conf_int(alpha=0.05, cols=None)
print(confinterval)0 1 Intercept 7.209605 13.346252 x 4.070851 5.767811
以上就是已经把回归模型训练好了(回归模型对象为result)
下面进行应用
# 预测新值
# 单值
predictvalues = result.predict(pd.DataFrame({'x': [3.5]}))
#需要注意的是pandas的基本单位是表单df,所以预测的x应该是以表单形式写入“键”:[值]
print(predictvalues)[ 27.49558609]
# 单值
predictvalues = result.predict(pd.DataFrame({'x': [3.5]}))
#需要注意的是pandas的基本单位是表单df,所以预测的x应该是以表单形式写入“键”:[值]
print(predictvalues)[ 27.49558609 28.47945224]
代码总述
# -*- coding: UTF-8 -*-import numpy as np
import statsmodels.api as sm
import statsmodels.formula.api as smf
import matplotlib.pyplot as plt
import pandas as pd
#from patsy import dmatrices
from statsmodels.stats.api import anova_lm
import scipy# 显示所有列
pd.set_option('display.max_columns', None)
# 显示所有行
pd.set_option('display.max_rows', None)
# 设置value的显示长度为100,默认为50
pd.set_option('max_colwidth', 200)# # Load data
df = pd.read_csv('data2.1.csv')# 计算相关系数
cor_matrix = df.corr(method='pearson') # 使用皮尔逊系数计算列与列的相关性
# cor_matrix = df.corr(method='kendall')
# cor_matrix = df.corr(method='spearman')# print(cor_matrix)# ==========第一种建模方式======================================
# y,X = dmatrices('y~x', data=df, return_type = 'dataframe')
# print(X)
# mod = sm.OLS(y,X)
# result = mod.fit()# ==========第二种建模方式(类R语言方式)======================================
result = smf.ols('y~x', data=df).fit()# print(result.params)
print(result.summary())y_fitted = result.fittedvaluesfig, ax = plt.subplots(figsize=(8, 6))
ax.plot(df['x'], df['y'], 'o', label='data')
ax.plot(df['x'], y_fitted, 'r-', label='OLS')
ax.legend(loc='best')
# plt.show()# 方差分析
table = anova_lm(result, typ=2)# print(table)# print(result.scale)# pearson相关系数检验
cortest = scipy.stats.pearsonr(df['x'], df['y'])
print(cortest)# 计算残差
eres = result.resid
# print(eres)fig, ax = plt.subplots(figsize=(8, 6))
ax.plot(eres, 'o', label='resid')
# plt.show()# 标准化残差
stand_eres = eres / np.sqrt(result.scale) # eres.std()
print(stand_eres)# 学生化残差
infl = result.get_influence()
# studentied_eres = infl.summary_table()
studentied_eres = infl.resid_studentized_internalprint(studentied_eres)##置信区间confinterval = result.conf_int(alpha=0.05, cols=None)
print(confinterval)# =========预测新值======================================================
# 单值
predictvalues = result.predict(pd.DataFrame({'x': [3.5]}))
print(predictvalues)# 区间
predictions = result.get_prediction(pd.DataFrame({'x': [3.5]}))
print(predictions.summary_frame(alpha=0.05))