13.1 pandas与建模代码的结合
使用pandas用于数据载入和数据清洗,之后切换到模型库去建立模型是一个常见的模型开发工作流。在机器学习中,特征工程时模型开发的重要部分之一,特征工程就是指从原生数据集中提取可用于模型上下文的有效信息的数据转换过程或分析。
pandas和其他分析库的结合点通常是numpy数组,要将datafram转换层numpy数组,使用的时.value 属性
data = pd.DataFrame({'x0': [1, 2, 3, 4, 5],'x1': [0.01, -0.01, 0.25, -4.1, 0.],'y': [-1.5, 0., 3.6, 1.3, -2.]})
data.values
array([[ 1. , 0.01, -1.5 ],[ 2. , -0.01, 0. ],[ 3. , 0.25, 3.6 ],[ 4. , -4.1 , 1.3 ],[ 5. , 0. , -2. ]])df2 = pd.DataFrame(data.values, columns=['one', 'two', 'three']) # 再转换成dataframe
df2
one two three
0 1.0 0.01 -1.5
1 2.0 -0.01 0.0
2 3.0 0.25 3.6
3 4.0 -4.10 1.3
4 5.0 0.00 -2.0df3=data.copy()
df3['strings']=['a','b','c','d','e'] # 数据有多种类型
df3.values
array([[1, 0.01, -1.5, 'a'],[2, -0.01, 0.0, 'b'],[3, 0.25, 3.6, 'c'],[4, -4.1, 1.3, 'd'],[5, 0.0, -2.0, 'e']], dtype=object)model_cols=['x0','x1']
data.loc[:,model_cols].values # 使用loc 来索引一部分列
array([[ 1. , 0.01],[ 2. , -0.01],[ 3. , 0.25],[ 4. , -4.1 ],[ 5. , 0. ]])
有些库对pandas有本地化支持,可以自动为你做以下工作: 将数据从datafraem 转换到numpy 中并将模型参数名称附于输出表的列或series 上。其他情况下,你将不得不去手动处理这元数据管理的操作
data['category'] = pd.Categorical(['a', 'b', 'a', 'a', 'b'],categories=['a', 'b'])
datax0 x1 y category
0 1 0.01 -1.5 a
1 2 -0.01 0.0 b
2 3 0.25 3.6 a
3 4 -4.10 1.3 a
4 5 0.00 -2.0 bdummies = pd.get_dummies(data.category, prefix='category') # 使用虚拟变量代替 category 列。
data_with_dummies = data.drop('category', axis=1).join(dummies)
data_with_dummiesx0 x1 y category_a category_b
0 1 0.01 -1.5 1 0
1 2 -0.01 0.0 0 1
2 3 0.25 3.6 1 0
3 4 -4.10 1.3 1 0
4 5 0.00 -2.0 0 1
13.2 使用Patsy创建模型描述
Patsy 是一个用于描述统计模型(尤其是线性模型)的python库。它使用一种基于字符串的公式语法,这种语法受到了R,S 统计编程语言中公式语法的启发,
pasty可以很好的支持statsmodels中特定的线性模型,因此我们专注于它的主要特性帮助你把程序跑起来。
pasty的公式是特殊字符串语法:y ~ x0+x1
例如,我们有一些变量y ,想要使用x , a, b ,a和b的相互影响,这些变量来进行回归,可以写成patsy.dmatrices("y ~ x + a + b + a:b", data)。pasty负责构建适当的矩阵。
到底讲个啥啊,,,找文档研究研究吧。。。脑补链接
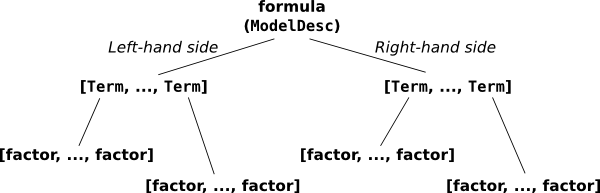
个人感觉这个公式就是把dataframe 拆成几个series吧。。。。在右边加个截距列。。
y ~ a + a:b + np.log(x) 这个就是分成两半,左边是y,右边有四个: a, a:b(a,b的相互作用,,是不是这么翻译啊),np.log(x),和一个隐藏的截距。截距项是零因子之间的相互作用(就是一列1)。还有 这个+ 号就是将这几个结合的组术语,计算出来的是并集
ModelDesc([Term([EvalFactor("y")])], # y ~ a + a:b + np.log(x)的底层形式[Term([]), # 这就是截距Term([EvalFactor("a")]),Term([EvalFactor("a"), EvalFactor("b")]),Term([EvalFactor("np.log(x)")])])
这个截距术语,,其实就是一个看不见的 +1。。。。所以为什么要加一。。
y ~ x - 1 # 这些就是去掉默认的截距列。。。
y ~ x + -1
y ~ -1 + x
y ~ 0 + x
y ~ x - (-0)
反正大概看了一下,,好像说这个截距啥用没有。。就是给你找事的(创建冗余)。。。啊???
语法 a+b 不是加法,而是指为模型而创建的设计矩阵中的名词。patsy.dmatrices 函数再数据集上(可以是一个dataframe或数组的字典)使用了一个公式字符串,并为一个线性模型产生了设计矩阵:
data = pd.DataFrame({'x0': [1, 2, 3, 4, 5],'x1': [0.01, -0.01, 0.25, -4.1, 0.],'y': [-1.5, 0., 3.6, 1.3, -2.]})
import patsy
y, X = patsy.dmatrices('y ~ x0 + x1', data) # y回归到x0,x1上,返回一个元组,第一个表示公式的左侧,第二个表示右侧
y
DesignMatrix with shape (5, 1) # 设计矩阵,截距已经自动添加到了右侧,这些就是带有额外元数据的numpy数组y-1.50.03.61.3-2.0Terms:'y' (column 0)X
DesignMatrix with shape (5, 3)Intercept x0 x11 1 0.011 2 -0.011 3 0.251 4 -4.101 5 0.00Terms:'Intercept' (column 0) # 截距???是不是y=ax+b 的那个b ..不过为啥是1呢。。'x0' (column 1)'x1' (column 2)np.asarray(y) # 这是patsy
array([[-1.5],[ 0. ],[ 3.6],[ 1.3],[-2. ]])
np.asarray(X)
array([[ 1. , 1. , 0.01],[ 1. , 2. , -0.01],[ 1. , 3. , 0.25],[ 1. , 4. , -4.1 ],[ 1. , 5. , 0. ]])# 可以通过给模型添加名词列+o来加入截距
patsy.dmatrices('y ~ x0 + x1 + 0', data)[1]
DesignMatrix with shape (5, 2) # 所以说到底啥是截距。。。x0 x11 0.012 -0.013 0.254 -4.105 0.00Terms:'x0' (column 0)'x1' (column 1)# pasty对象(因为其实就是numpy数组)可以直接传递给一些算法,比如numpy.linalg.lstsq等,这算法会执行一个最小二乘回归。。。等去学学数学。。。
coef, resid, _, _ = np.linalg.lstsq(X, y)coef # 模型元数据保留再design_info属性中,因此你可以将模型列名重新附加到拟合系数以获得一个series
array([[ 0.31290976], # 这是最小二乘解[-0.07910564],[-0.26546384]])coef=pd.Series(coef.squeeze(),index=X.design_info.column_names)
Intercept 0.312910
x0 -0.079106
x1 -0.265464
dtype: float64
来自知乎的图,,,可以帮助理解下最小二乘吧。。简单说,它就是用最小二乘法拟合数据得到一个形如y = mx + c的线性方程
13.2.1 Patsy公式中的数据转换
将python代码混合到你的pasty公式中,再执行公式时,pasty库会尝试再封闭作用域中寻找你使用的函数
y,x=patsy.dmatrices('y~x0 +np.log(np.abs(x1)+1)',data)
x
DesignMatrix with shape (5, 3)Intercept x0 np.log(np.abs(x1) + 1)1 1 0.009951 2 0.009951 3 0.223141 4 1.629241 5 0.00000Terms:'Intercept' (column 0)'x0' (column 1)'np.log(np.abs(x1) + 1)' (column 2)y,x=patsy.dmatrices('y~standardize(x0)+center(x1)',data) # 一些常用的变量转换包括标准化(对均值0和方差1)
x # 和居中(减去平均值)。pasty有内置函数:
DesignMatrix with shape (5, 3)Intercept standardize(x0) center(x1)1 -1.41421 0.781 -0.70711 0.761 0.00000 1.021 0.70711 -3.331 1.41421 0.77Terms:'Intercept' (column 0)'standardize(x0)' (column 1)'center(x1)' (column 2)new_data = pd.DataFrame({'x0': [6, 7, 8, 9],'x1': [3.1, -0.5, 0, 2.3],'y': [1, 2, 3, 4]})
new_X = patsy.build_design_matrices([X.design_info], new_data)
new_X # pasty.build_design_matrices函数可以使用原始样本内数据集中保存的信息将变换应用于新的样本外数据上。
[DesignMatrix with shape (4, 3)Intercept x0 x11 6 3.11 7 -0.51 8 0.01 9 2.3Terms:'Intercept' (column 0)'x0' (column 1)'x1' (column 2)]y, X = patsy.dmatrices('y ~ I(x0 + x1)', data) # 对数据集中两列案列名相加,必须将列名封装到特殊函数I中。
X
DesignMatrix with shape (5, 2)Intercept I(x0 + x1)1 1.011 1.991 3.251 -0.101 5.00Terms:'Intercept' (column 0)'I(x0 + x1)' (column 1)
13.2.2 分类数据与pasty
将非数字类型转换以用于模型的设计矩阵
再pasty公式中使用非数字名词列时,会默认转换为虚拟变量。如果有拦截,其中一个级别将被排除以避免共线性。
data = pd.DataFrame({'key1': ['a', 'a', 'b', 'b', 'a', 'b', 'a', 'b'],'key2': [0, 1, 0, 1, 0, 1, 0, 0],'v1': [1, 2, 3, 4, 5, 6, 7, 8],'v2': [-1, 0, 2.5, -0.5, 4.0, -1.2, 0.2, -1.7]
})
y, X = patsy.dmatrices('v2 ~ key1', data)
X
DesignMatrix with shape (8, 2)Intercept key1[T.b]1 01 01 1 # a,b被转换成虚拟变量了。1 11 01 11 01 1Terms:'Intercept' (column 0)'key1' (column 1)y, X = patsy.dmatrices('v2 ~ key1 + 0', data) # 这是忽略了截距,每个类别值的列将被包含再模型的设计矩阵中。
X
DesignMatrix with shape (8, 2)key1[a] key1[b]1 01 00 10 11 00 11 00 1Terms:'key1' (columns 0:2)y, X = patsy.dmatrices('v2 ~ C(key2)', data) # 数字类型列可以使用 C 函数解释为分类类型。
X
DesignMatrix with shape (8, 2)Intercept C(key2)[T.1]1 01 11 01 11 01 11 01 0Terms:'Intercept' (column 0)'C(key2)' (column 1)data['key2'] = data['key2'].map({0: 'zero', 1: 'one'}) # 再模型中使用多个分类名词时,事情可能会更加复杂,因为你可以包含
y, X = patsy.dmatrices('v2 ~ key1 + key2', data) # key1 : key2的交互项,例如用于方差分析模型
X
DesignMatrix with shape (8, 3)Intercept key1[T.b] key2[T.zero]1 0 11 0 01 1 11 1 01 0 11 1 01 0 11 1 1Terms:'Intercept' (column 0)'key1' (column 1)'key2' (column 2)y, X = patsy.dmatrices('v2 ~ key1 + key2 + key1:key2', data)
X
DesignMatrix with shape (8, 4)Intercept key1[T.b] key2[T.zero] key1[T.b]:key2[T.zero]1 0 1 01 0 0 01 1 1 11 1 0 01 0 1 01 1 0 01 0 1 01 1 1 1Terms:'Intercept' (column 0)'key1' (column 1)'key2' (column 2)'key1:key2' (column 3)
说实话,,,从一开始我就看不懂了。。。。