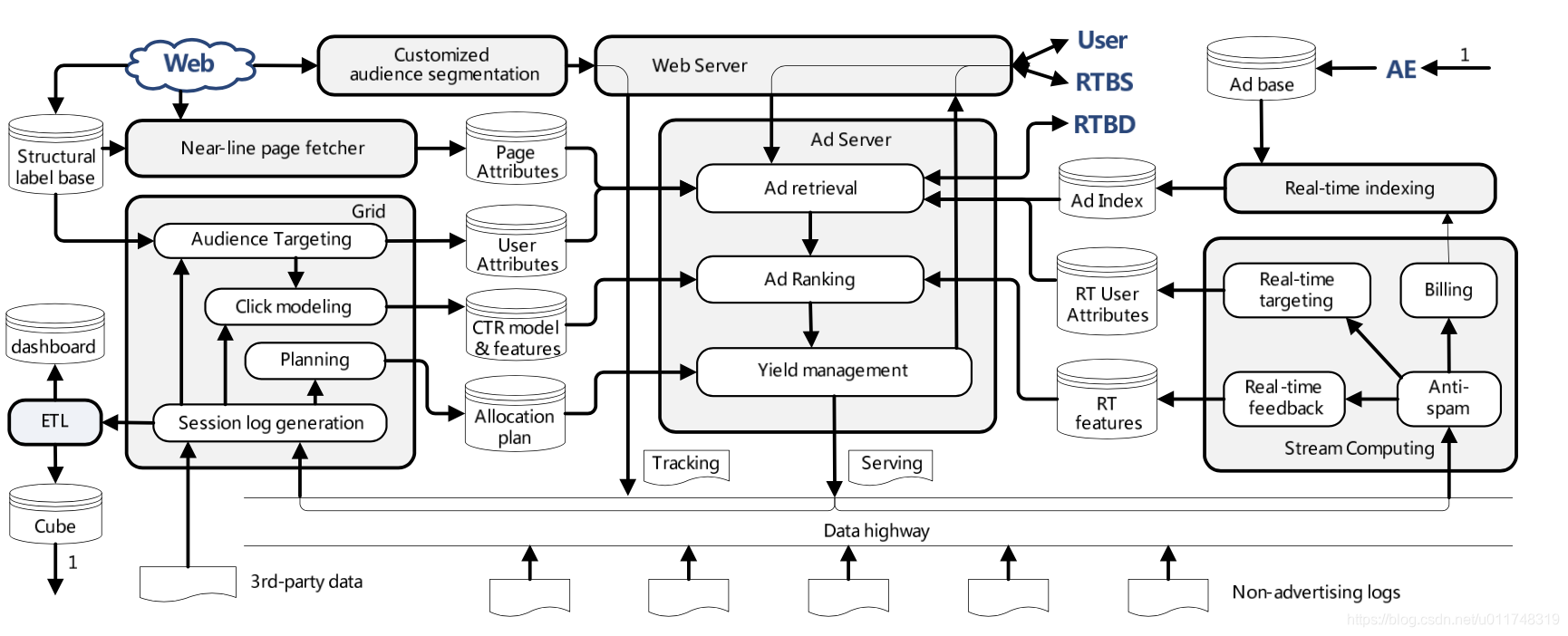
广告系统主要解决一个问题:在给定展示场景、用户的情况下,返回收益最大化的广告。下图是一个广告系统最简单的架构图。其中,Router,检索模块,排序模块一般称为广告系统的核心。同时,与之辅助的至少包含三大系统:特征计算系统,计费系统,投放系统。

先介绍一下三个辅助系统的主要功能:
-
特征计算系统:实时计算广告展示环境 (网页,APP) 的特征,用户的特征。并提供实时查询功能。
-
计费系统:实时处理广告的展现 (CPM)、点击 (CPC)、转化 (CPA)数据,并计算广告的剩余预算。需要包括反作弊功能。
-
投放系统:供广告主使用,设置广告的基本信息和定向条件。
核心部分包含了三个模块:
-
Router:对外提供HTTP服务。接收请求后,依次与特征计算系统、检索模块、排序模块交互,最后返回广告。
-
检索模块:检索模块主要解决相关性问题。首先,根据广告主设定的定向条件筛选出本次请求能否返回的广告;然后,按多种定向策略筛选出与本次请求最相关的若干个广告。
-
排序模块:排序模块主要解决收益最大化的问题。通用的排序标准是eCPM。以CPC广告系统为例,eCPM=eCTR*CPC,CPC是广告主设定的,排序模块的核心就是使预估的eCTR尽可能地接近实际CTR。
本文讨论检索模块的架构设计。在检索模块中使用的数据一般可以分为三类:
-
广告本身的信息。例如ID,标题,描述,出价,投放时间,预算余额等。
-
广告的定向数据。例如国家,设备,人群等。
-
各个定向策略使用的内部数据。例如,预先计算出的各个广告的特征,人群的兴趣点扩充数据等。
同样,讨论架构先说业务特点。
-
大型广告系统中,单机的瓶颈首先出现在内存上,通常内存的使用率在80%以上,只剩余20%的内存空间实际上是非常危险的,后文中会阐述原因。在使用的内存中,可以假定70%是广告数据,30%是各策略使用的内部数据。
-
数据的更新量占数据总量的比例很小,一般更新量会比总量少两个数量级。
-
数据存在热点。例如,一些热门搜索词会被大量广告主购买,一些热门的人群也会被广告主大量购买。
带着这些前提,接下来讨论检索模块的几个主要问题。
-
冷启动
检索模块在提供服务前,需要将最新的广告数据和策略数据加载到内存中。假定检索模块使用的是内存为64G的机器,按内存使用率80%计算,系统启动的时候需要把50G的数据加载到内存,可以想象这是一个耗时很长的操作。另外,广告系统一般都包含正排索引和倒排索引两种数据,倒排索引是根据正排索引建立的,所以系统启动的时候不仅仅是加载数据,还存在计算的过程,当然,在不存在指针的情况下,倒排索引也可以预先计算好,可以减少启动时间。
全量与增量。因为广告数据是实时在变化的,所以一般的方案是定期对数据库做快照,并记录下时间点。系统启动时,加载最新的一个快照的数据,并且加载完所有该快照生成时间之后的所有更新,才可以对外提供服务。快照一般称为全量,更新一般称为增量。另外,这里说的时间,不一定是真实的时间,也可以是逻辑时间。例如,创建一个高可用服务,对外提供始终自增的id,每一条数据更新都关联一个唯一的id,做快照的时候,快照的id就是最新一条记录的id。
预生成索引文件。数据库的快照一般是以文本文件的形式存储的。但是,系统在启动的时候处理文本文件,是非常耗时的。所以一般会使用一台单独的机器预先加载快照文件,将数据转换为与检索模块相同的二进制的格式,再dump到二进制文件中,这样检索模块启动的时候直接加载二进制文件,可以达到很好的性能。注意,为了提高加载数据的效率,二进制数据往往没有经过任何序列化,因此建立索引的服务必须使用和检索模块同样的操作系统和配置。
-
内存数据结构设计
检索模块使用的数据结构必须具备两个特性:高效存储,高效更新。
高效存储是指如何使用尽可能小的内存空间存储给定的数据。因此工程师需要对内存进行精确的控制(内存中的数据排列,分配和释放),这也是为什么大多数对内存要求严格的系统都使用C/C++开发的原因(无意引起语言之争)。位操作在检索模块中很常见,同时在设计结构体时,要充分考虑数据对齐(可参考的资料很多,这里不展开)。下面重点介绍两种常见的技术。
MemoryPool
MemoryPool是C++中常用的内存分配技术。大的对象或数组往往是分配在堆上,系统中时刻都有不同的对象被创建和销毁,如果每次都使用 malloc/free 去创建/销毁对象,则容易造成内存碎片。MemoryPool的作用是,为常见的对象批量申请内存并预留,在系统需要创建对象的时候,从预留的内存中选择一块空间,作为新的对象,供系统初始化和使用。在销毁对象时,并没有实际销毁这段内存空间,而是将该空间记录在MemoryPool内部的列表中 (freelist),在下次分配空间的时候优先从该列表分配。
常见的MemoryPool提供Create和Destroy两个方法。
-
Create即创建一个对象,如果MemoryPool中有预留的空间,则在预留的空间上分配,否则批量向系统申请空间。为了提供效率,Create方法常常返回指针而不是ID,因此MemoryPool不能移动其内部已经分配的空间。在Create方法返回后,常见的是使用Placement Constructor初始化对象。
-
Destroy方法接受指针作为参数,该指针指向的内存地址必须是MemoryPool分配的。Destroy方法可以调用对象的析构函数,然后将该指针加入到freelist。
以上讨论的是固定长度的MemoryPool,一般一个结构体对应一个MemoryPool。还有另一种可以存储多种长度的对象的MemoryPool,在实际使用中比较少见,想了解这方面的设计可以参考TCMalloc。
B+树
B树及其变种是数据库常用的数据结构。在内存-磁盘式数据库中,类B树的数据结构允许系统只将一部分节点加载到内存;在全内存数据库中,类B树的数据结构允许系统只将一部分节点的数据放入CPU的缓存中。类B树的数据主要有以下几个优点:
-
数据的插入和删除性能相对稳定。
-
在内存不足时,允许只将用户查询的索引数据全部或部分放入内存,提高查询效率
-
在执行新增和删除操作是,只需要修改很少的节点(修改次数与Fanout有关)
-
locality性比较好,尤其在系统存在热点数据的情况下更为明显。
实际使用中,B+树是比B树更好的选择。B+树相比B树,主要有两个优点:
-
索引和数据相分离,内部节点只保存索引数据。内存中相同大小的内部节点,B+树可以存储更多的索引。
-
叶子节点存储了全部的数据,并且叶子节点通过指针关联,可以方便地按顺序遍历全部或者部分数据。
B+树在使用过程中最常见的问题是,往往由于使用方式的不当,导致节点没有被填满,导致巨大的内存浪费。
在实际实现中,B+树的节点往往会根据Fanout预留全部的内存空间。以插入数据为例,在节点发生分裂时,分裂后的两个节点都会有一定的空间未被使用,如果没有合理地选择插入数据的顺序,会造成大量的节点未被充分使用。
例如,我们要将1到10十个数字插入到一颗空的B+树种,如果顺序插入,会得到如下的结果:

如果我们熟悉B+树的分裂策略,再稍微仔细的计算一下插入顺序,会得到不同的结果:

可以看到,顺序插入使用了导致B+树生成了八个节点,打乱一下次序只需要七个节点即可。不要小看这一个节点,当Fanout很大时,会节省非常可观的内存。笔者曾经通过优化B+树的内部组织,为单机节省了7G的内存。
细心的读者可以发现,在已知全部数据的情况下,是可以计算出插入B+树的最优方案的。前文提过,广告系统的数据更新量相比全量会少两个数量级,因此系统启动结束之后,内存的布局基本也就固定了,另外系统会随着上线被频繁重启,因此,解决了系统启动时候B+树的内存布局,也就解决了大部分问题。B+树的最优插入方案留给读者去思考。
-
数据更新
广告的数据和策略使用的数据都需要更新,但特点不同。广告数据对实时性要求非常高,广告主期望在秒级更新,但一天的更新量可能只占全量的1%不到。策略使用的数据往往需要通过大量的离线计算才能生成,往往几个小时甚至一天才需要更新一次,但更新的量很大,可能大部分数据都需要被更新。
增量更新 (INC)
广告数据对实时性要求高,因此一般采用增量更新的方案。回想本文开始的检索端架构图,投放系统和计费系统将广告数据更新到DB,同时发送给Message Queue,MQ中的每条数据都带着一个表示逻辑时间的ID。在各个检索模块的服务器上部署一个单独的服务从MQ订阅数据,该服务在接收到数据后,将数据以文件的形式持久化到磁盘。检索模块中有一个线程,定期从文件中读取更新的增量数据,并更新到内存中。
难点在于,检索模块在数据更新的同时,还需要继续提供服务,不能出现因为更新数据而锁住数据的情况。回想前文所说的,为了提高效率,系统中的数据都使用MemoryPool存储,MemoryPool对外暴露的都是指针,在一次请求过程中基本都在通过指针读取数据,很少有Copy数据的情况。因此,不能修改当前正在检索的数据。
这里一般使用Copy-On-Write的更新策略。即,同一个Key关联的数据有多个版本,在更新数据时,不更新原始的数据,而是Copy一份原有数据,并在此基础上最修改,新的数据比原有数据的版本号更大。在更新的过程中,老版本的数据依然可用;在下次查询中,返回的是最新版本的数据,同时在合适的时机删除老版本的数据。事实上,这个策略在目前的NoSQL系统中普遍存在。
Copy-On-Write的难点在于,如果保证Copy的数据尽量的小,最好只Copy更新的那个数据(实际上很难实现)。结合上文,读者可以考虑如何实现一个支持多版本数据的B+树,并且在Copy的时候尽可能少地Copy节点。
全量更新 (Reload)
策略数据对实时性要求不高,但更新的数量可能会很大,一般会使用Reload的方式进行更新。Reload更新最典型的方案是双Buffer切换。即,将新的数据全部导入到一个新的数据对象(Hash表)中,导入完毕后,使用新的对象替代老的对象。
Reload方法更新的数据,最大的好处是可以假定内存中的数据结构是只读的,不会出现增量更新方式中对数据结构进行插入和删除的操作。因此,可以使用一些更加简单高效的数据结构。
如果使用双Buffer切换的方式进行Reload数据,需要注意在更新的过程中,该数据的内存使用量会翻倍;如果多份数据同时进行Reload,会导致内存使用突然激增,甚至会超出系统极限,导致程序崩溃。这样的案例在生产环境中真实的出现过,虽然系统会自动重启,但如果大量机器同时触发这个情况,会出现非常危险的雪崩效应。这也是前文提到的,系统的内存使用量在80%以上,其实是有很大的风险的原因。因此,在多份数据都使用Reload的方案更新时,要注意好控制内存的使用,通过一些机制避免多个任务并行。
作为大型广告系统的核心,检索模块面临的问题非常复杂,实际的架构设计要紧密结合业务进行展开。没有统一的方案,只有不同的权衡妥协。本文重点讨论了检索模块一些常见的问题和解决方案,其中有很多细节留给读者思考。
关注我的公众号架构丛谈 | 最朴素地谈架构