编者按:基于基础通用模型构建领域或企业特有模型是目前趋势。本文简明介绍了最大化挖掘语言模型潜力的三大法宝——Finetune, Prompt Engineering和RLHF——的基本概念,并指出了大模型微调面临的工具层面的挑战。
以下是译文,Enjoy!
作者 | Ben Lorica
编译 | 岳扬
随着语言模型越来越流行,采用一套通用的方法和工具来充分释放语言模型的潜力就变得至关重要。这些方法中最重要的是提示工程(prompt engineering),其涉及到如何在提示(prompt)或查询(query)中选择和组合词语来请求模型产生所需的回复(response)。如果能够从ChatGPT或Stable Diffusion中获得所需的输出(output),那么你就离成为一名熟练的提示工程师(prompt engineer)又近了一步。
在tuning spectrum的背后是基于人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF),当模型需要在多种输入和准确率要求极高的情况下训练时,这种方法是最有效的。RLHF被广泛用于微调通用模型,如ChatGPT、谷歌的Bard、Anthropic的Claude或DeepMind的Sparrow。
下图中,我们总结了Finetune,Prompt Engineering, RLHF的核心特点和适用场景。
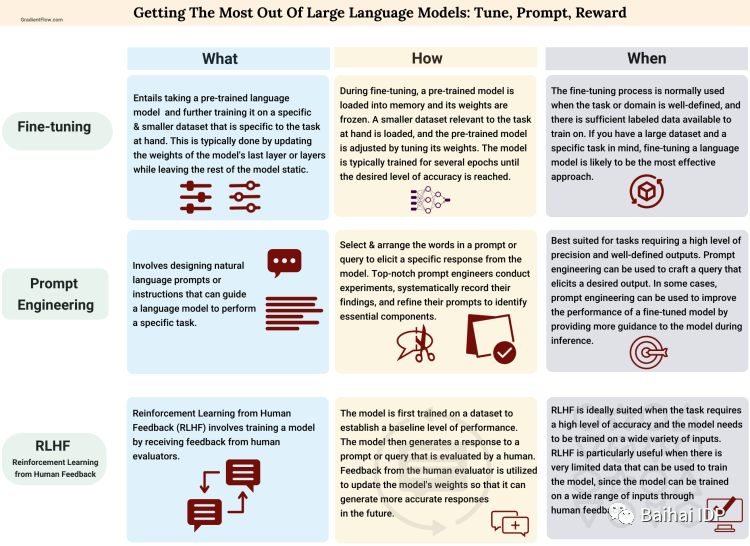

帮助我们充分利用基础模型的策略(中文图片由Baihai IDP翻译)
对于大多数团队来说,最佳选择是使用一个已初步训练好的模型,并将其Fine-tune以适应特定的任务或数据集。这个过程需要从大型语言模型(LLM)开始,这种模型已经在大量文本数据上进行了训练。虽然许多LLM目前是专有的(proprietary),只能通过API访问,但开源数据集、学术论文甚至开源模型代码的出现使技术团队能够用在他们特定的领域和应用程序。
另一个有趣的趋势是出现了更易于私有化部署和管理的基础模型,例如LLaMA和Chinchilla,这为将来出现更多的中型模型提供了可能性。选择合适的模型进行微调需要团队不仅考虑特定领域中可用数据的数量,还要评估模型的(开源)许可证与其具体要求的兼容性。
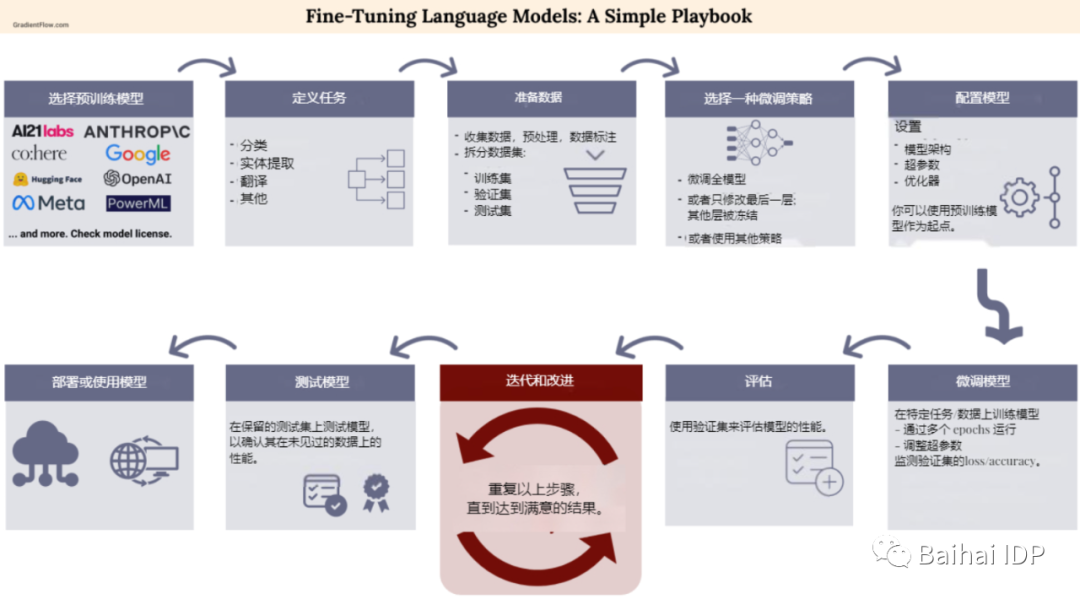
微调基础模型的简略手册
随着我们对基础模型实际应用的理解不断拓展,出现了很多定制化的工具(bespoke tools),能够方便在模型部署前完善这些模型。这里有一些用于微调和定制语言模型的资源:
-
Hugging Face的微调教程[1][2])。
-
OpenAI的微调指南[3]
-
co:here编写的关于如何创建自定义模型的指南[4]
-
AI21 Labs编写的关于创建自定义模型的教程[5]
在NLP(John Snow Labs[6])和CV(Matroid[7])领域中,已经有了无代码工具开发的实例,可以无代码创建自定义模型。在大模型领域,我期待类似的工具的出现,以完善基础模型的微调和应用。
尽管RLHF在训练顶尖语言模型的团队中获得了肯定,但由于缺乏可用的工具,其可及性( accessibility )仍然不足。此外,RLHF需要开发一个容易受misalignment(即出现了统计分布不一致现象)和其他问题影响的奖励函数(reward function),并且RLHF仍然是一种只有少数团队掌握的专有技术。
虽然提示工程有用,但在生成针对特定任务和领域优化的可靠基础模型方面仍然不足。尽管有些团队可能会选择从头开始构建自己的模型,但由于从头开始训练模型的成本,这些团队不太可能总是这样做。因此,现在的趋势是倾向于微调预训练模型。
这就会导致,技术团队需要简单而多功能的工具,使他们能够使用各种技术[8]来创建自定义模型。
尽管微调(fine-tuning)可以产生最佳模型(optimal models),但在部署模型之前,还需要进一步使用RHLF进行调整。此外,Anthropic最近进行的一项研究表明[9],提示方法(prompting methods)可以帮助使用RLHF训练的LLMs产生更少有害内容。
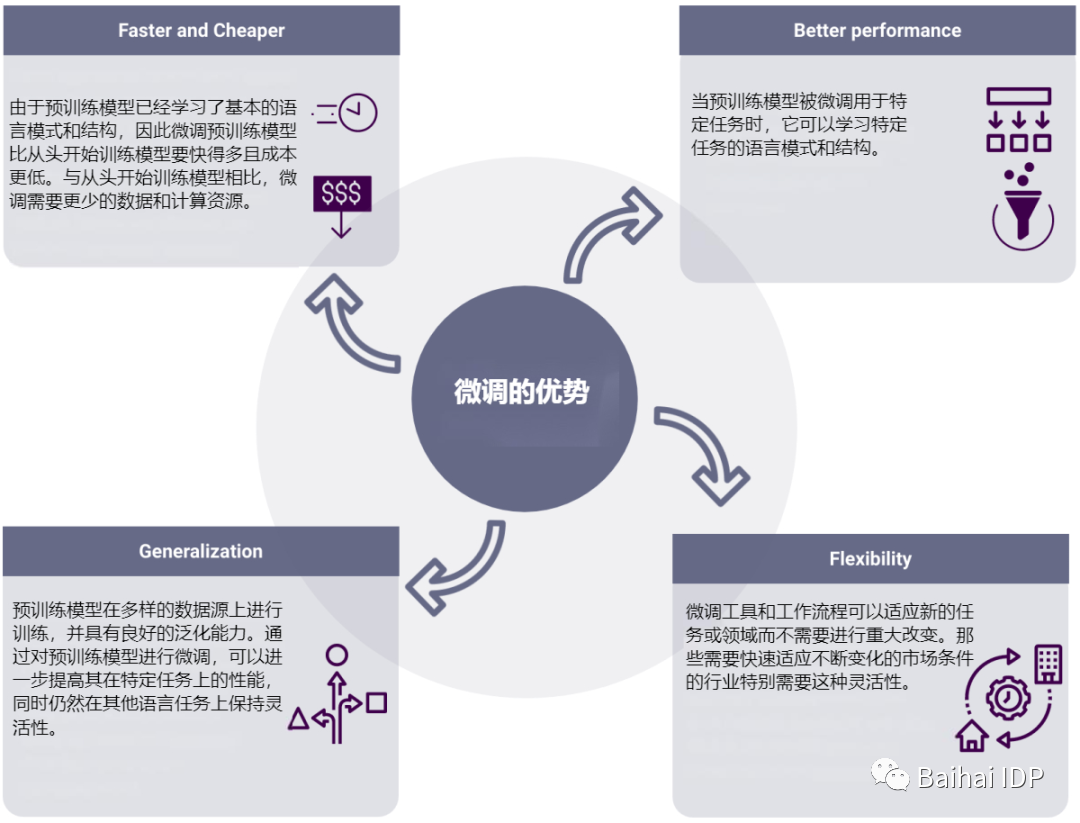
微调预训练模型比提示工程,或从头开始训练模型更有优势
END
小编注:需要大语言模型微调和训练工具平台的小伙伴,欢迎体验IDP。我们也基于平台,快速搭建了多模态模型IDPChat,欢迎关注和贡献。https://github.com/BaihaiAI/IDPChat
参考资料
[1]https://huggingface.co/docs/transformers/training
[2]https://huggingface.co/blog/trl-peft
[3]https://platform.openai.com/docs/guides/fine-tuning
[4]https://dashboard.cohere.ai/models/create
[5]https://docs.ai21.com/docs/custom-models
[6]https://nlp.johnsnowlabs.com/docs/en/alab/training_configurations
[7]https://www.matroid.com/detector-creation/
[8]https://powerml.co/?utm_source=newsletter&utm_id=gradientflow
[9]https://arxiv.org/abs/2302.07459
本文经原作者授权,由Baihai IDP编译。如需转载译文,请联系获取授权。
原文链接:
https://gradientflow.com/llm-triad-tune-prompt-reward/