每天给你送来NLP技术干货!
来自:圆圆的算法笔记
随着预训练模型参数量越来越大,迁移学习的成本越来越高,parameter-efficient tuning成为一个热点研究方向。在以前我们在下游任务使用预训练大模型,一般需要finetune模型的所有参数。随着parameter-efficient tuning技术的发展,一些注入adaptor、prefix tuning、LoRA等成本更低的finetune方法被提出。那么各种各样的parameter-efficient tuning方法之间是否存在某些潜在的关系呢?ICLR 2022就有一篇相关的研究,从统一的视角理解现有的各类parameter-efficient tuning方法,并提出了一套迁移框架,可以实现更接近全量参数finetune效果的部分参数finetune。

论文标题:TOWARDS A UNIFIED VIEW OF PARAMETER-EFFICIENT TRANSFER LEARNING
下载地址:https://arxiv.org/pdf/2110.04366.pdf
1
各类tuning方法回顾
比较经典的高效finetune方法主要包括adaptor、prefix-tuning、LoRA这三类,这里进行一个简单的回顾。
Adaptor核心是在原Bert中增加参数量更小的子网络,finetune时固定其他参数不变,只更新这个子网络的参数。Adaptor是最早的一类高效finetune方法的代表,在Parameter-Efficient Transfer Learning for NLP(ICML 2019)这篇文章中被提出。在原来的Bert模型的每层中间加入两个adapter。Adapter通过全连接对原输入进行降维进一步缩小参数量,经过内部的NN后再将维度还原,形成一种bottleneck的结构。在finetune过程中,原预训练Bert模型的参数freeze住不更新,只更新adapter的参数,大大减少了finetune阶段需要更新和保存的参数量。
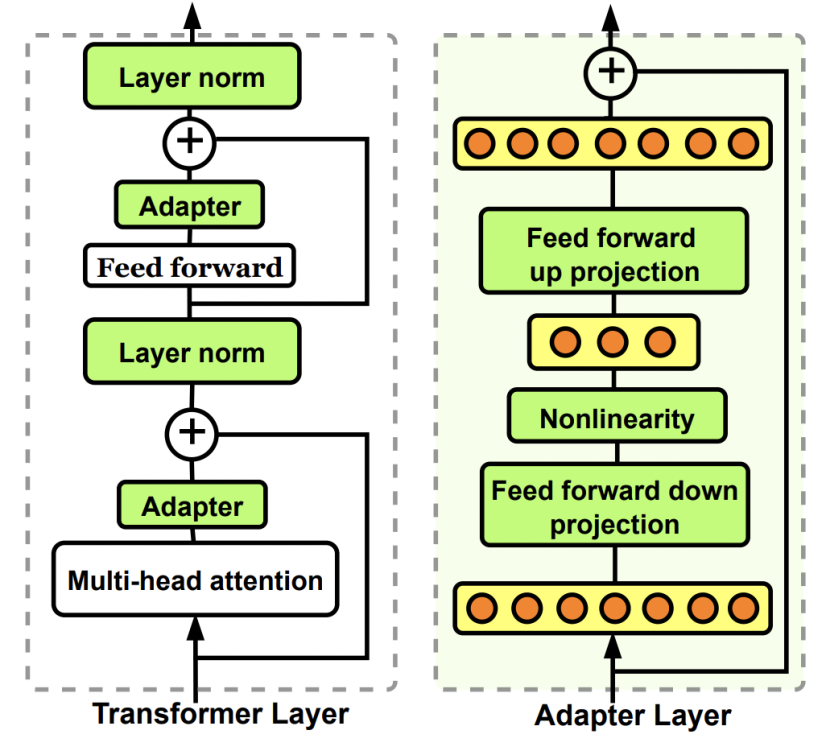
Prefix-tuning的核心是为每个下游任务增加一个prefix embedding,只finetune这些embedding,其他参数freeze。Prefix-tuning对应的论文是Prefix-Tuning: Optimizing Continuous Prompts for Generation(2021),这类方法的思想来源于prefix prompt,prefix embedding相当于一个上下文信息,对模型最终产出的结果造成影响,进而只finetune这个embedding实现下游任务的迁移。
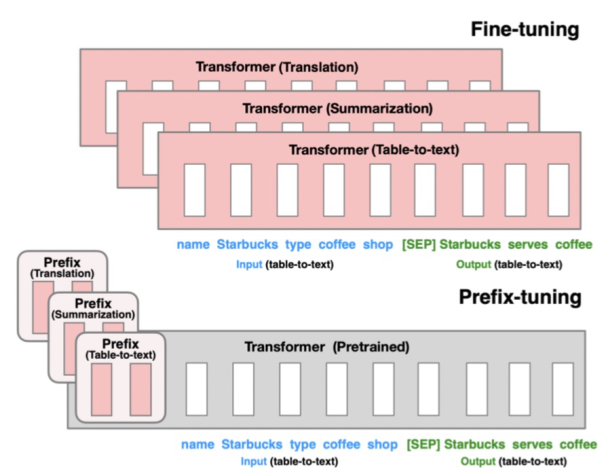
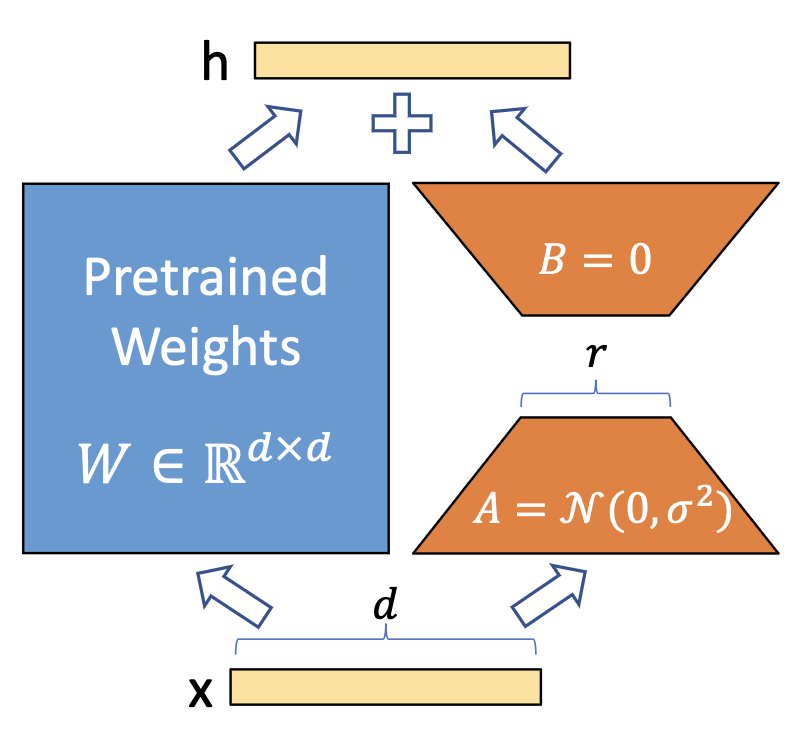
LoRA的核心是通过引入参数量远小于原模型的可分解的两小矩阵建立一个旁路,通过finetune这个旁路来影响预训练模型。LoRA于LoRA: Low-rank adaptation of large language models(2021)论文中被提出,利用低秩矩阵替代原来全量参数的训练,提升finetune效率。
2
统一视角看高效finetune方法
ICLR 2022的这篇文章从统一的视角来看各类不同的parameter-efficient tuning方法。首先对于prefix tuning,Transformer的每个head的结果可以进行如下的公式推导变换:

其中,第一行的P就是prefix embedding,C对应着key和value的序列向量,x代表query。经过中间的变换后,可以发现prefix tuning的attention计算可以分为两个部分的加权求和,第一部分是原始的attention,第二部分是和key或value无关的一项,只用query和prefix embedding进行self-attention的计算。而权重则是根据prefix embedding的attention权重。通过上述公式,我们可以从另一个视角来看prefix-tuning:即在原始attention的输出结果上,对位相加一个由prefix embedding得到的attention值,实现对原始attention score的修正。
我们再来看Adaptor和LoRA两种tuning方式的数学表示。Adaptor和LoRA方法可以分别表示为如下公式:
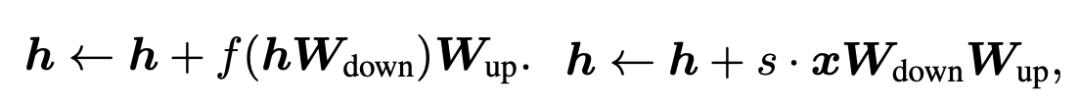
我们把prefix embedding也可以转换成相同的表达形式:
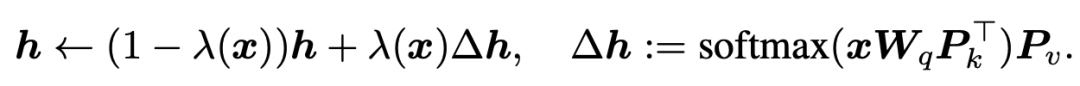
可以发现这些finetune方法都具有相似的表达形式。并且,prefix-tuning中prefix embedding的数量其实和Adapter中降维的维度具有相似的功能。三种方法在这个视角下的对比如下图所示:
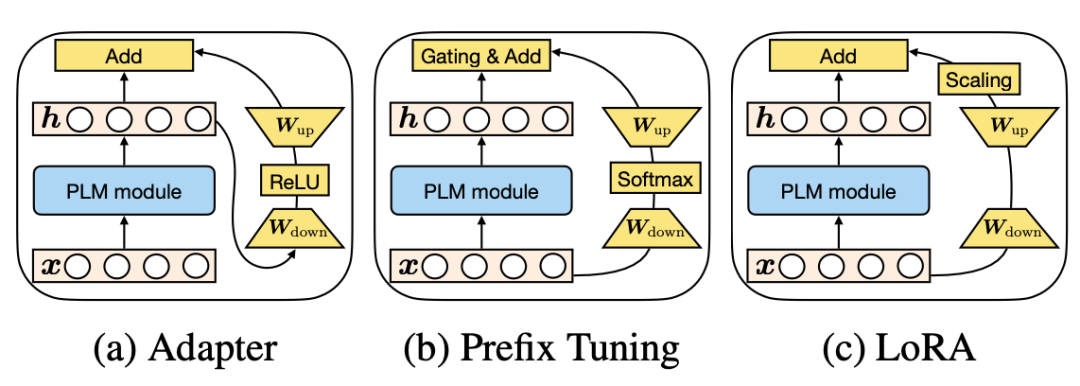
3
统一的高效finetune框架
既然上述几类方法表达形式相似,并且主要学的都是如何修改原来attention的输出结果,那么我们可以建立一个统一的框架,涵盖上述各类finetune方法。这个框架的核心是如何生成修改原始attention score的向量。为了生成这个向量,需要考虑以下4个核心模块:
Functional Form:用什么样的函数生成,上述方法基本都是全连接降维+激活函数+全连接升维的形式,当然也可以设计更复杂的函数形式;
Modified Representation:对哪个位置的信息进行直接修改;
Insertion Form:向量引入的形式,Adapter采用的是串联的方式,根据上一层的隐状态生成向量;而prefix tuning和LoRA采用并联的方式,直接根据输入序列生成向量;
Composition Function:向量的使用方式,利用adapter中采用简单的对位相加的形式。
Adapter、Prefix-tuning、LoRA等方法按照 上面4个维度拆分,各自的实现形式如下表:
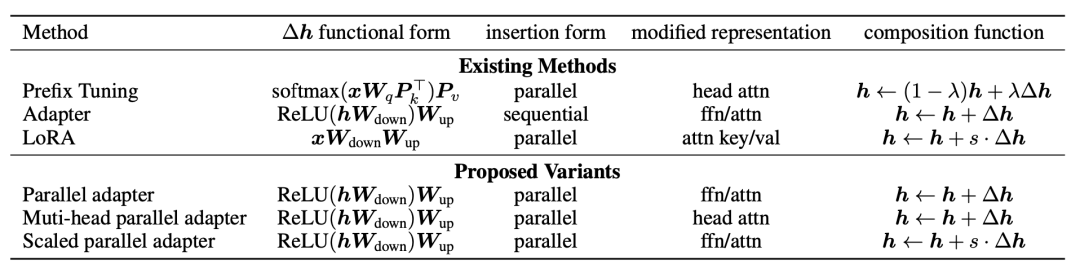
接下来,文中基于上述4个模块设计了一些新的方法:
Parallel Adapter:将Adapter的串联形式修改为并联形式;
Multi-head Parallel Adapter:在Parallel Adapter基础上修改了Modified Representation,使用旁路向量修改attention输出结果;
Scaled Parallel Adapter:将LoRA的scaling引入进来。
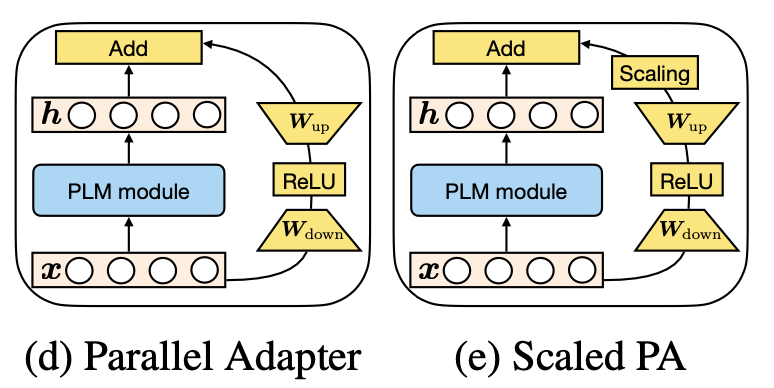
4
实验结果
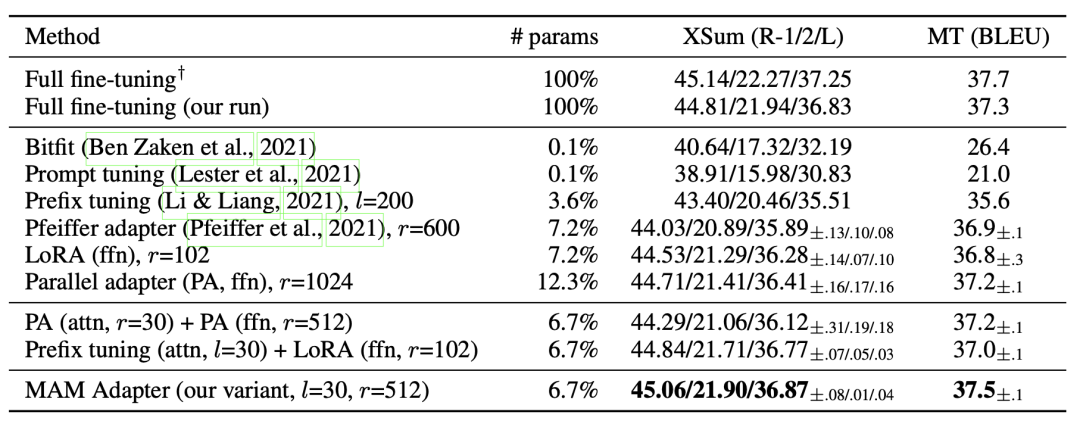
本文由于站在了更高的视角,看到了parameter-efficient tuning的统一形式,因此可以实现更加灵活的建模方式,基于这个框架寻找最节省参数量、最能达到更好效果的结构。从下图可以看出,本文提出的方法实现接接近全量参数finetune的效果,参数量也比Adapter、LoRA等方法有所减少。
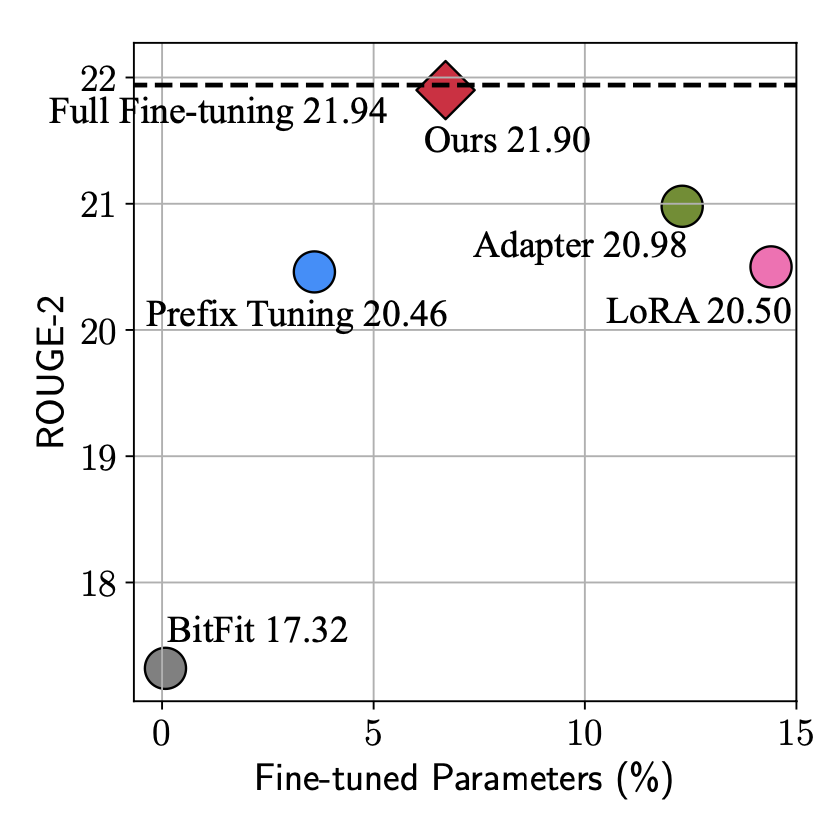
文中通过大量的实验对比各个模块采用什么样的形式能带来最好的效果-效率的这种,并最终提出最优的模型MAM-Adapter。核心的实验发现包括:并联的方式比串联的好;对FFN输出结果的修改比对Attention输出结果修改要好等。
5
总结
本文从统一视角看parameter-efficient tuning,实现了更高视角的最优tuning框架设计。这也启发我们寻找同类问题不同建模方式背后原理的统一性,能够跳出一种模型结构去看各类建模方式的相似性,实现更高视角下对问题的理解。
📝论文解读投稿,让你的文章被更多不同背景、不同方向的人看到,不被石沉大海,或许还能增加不少引用的呦~ 投稿加下面微信备注“投稿”即可。
最近文章
COLING'22 | SelfMix:针对带噪数据集的半监督学习方法
ACMMM 2022 | 首个针对跨语言跨模态检索的噪声鲁棒研究工作
ACM MM 2022 Oral | PRVR: 新的文本到视频跨模态检索子任务
点击这里进群—>加入NLP交流群和求职群