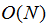一.红黑树定义
红黑树(Red Black Tree) 是一种自平衡二叉查找树,是在计算机科学中用到的一种数据结构,典型的用途是实现关联数组。
它是在1972年由Rudolf Bayer发明的,当时被称为平衡二叉B树(symmetric binary B-trees)。后来,在1978年被 Leo J. Guibas 和 Robert Sedgewick 修改为如今的"红黑树"。
红黑树和AVL树类似,都是在进行插入和删除操作时通过特定操作保持二叉查找树的平衡,从而获得较高的查找性能。
它虽然是复杂的,但它的最坏情况运行时间也是非常良好的,并且在实践中是高效的: 它可以在O(log n)时间内做查找,插入和删除,这里的是树中元素的数目。
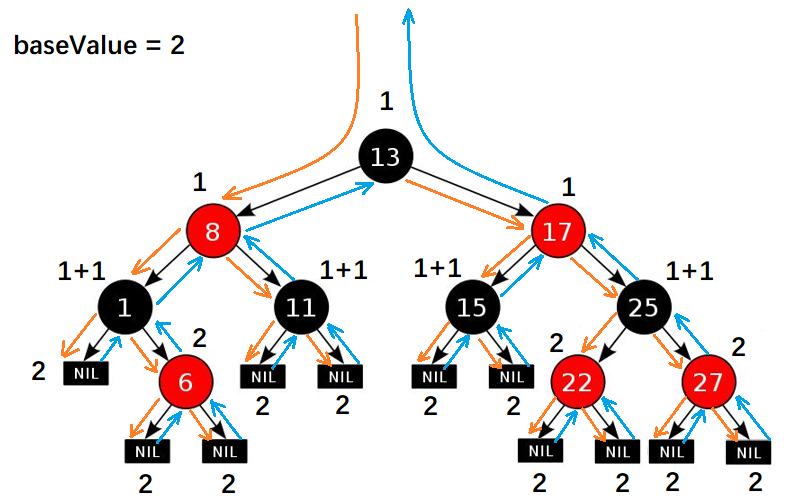
二.红黑树是一种含有红黑结点并能自平衡的二叉查找树。它必须满足下面性质:
- 性质1:每个节点要么是黑色,要么是红色。
- 性质2:根节点是黑色。
- 性质3:每个叶子节点(NULL)是黑色。(同234树)
- 性质4:每个红色结点的两个子结点一定都是黑色。
- 性质5:任意一结点到每个叶子结点的路径都包含数量相同的黑结点。
- 性质5.1:如果一个结点存在黑子结点,那么该结点肯定有两个子结点。(由5推出)
- 这些约束强制了红黑树的关键性质: 从根到叶子的最长的可能路径不多于最短的可能路径的两倍长。结果是这个树大致上是平衡的。因为操作比如插入、删除和查找某个值的最坏情况时间都要求与树的高度成比例,这个在高度上的理论上限允许红黑树在最坏情况下都是高效的,而不同于普通的二叉查找树。
-
要知道为什么这些特性确保了这个结果,注意到性质4导致了路径不能有两个毗连的红色节点就足够了。最短的可能路径都是黑色节点,最长的可能路径有交替的红色和黑色节点。因为根据性质5所有最长的路径都有相同数目的黑色节点,这就表明了没有路径能多于任何其他路径的两倍长。
在很多树数据结构的表示中,一个节点有可能只有一个子节点,而关联数组不包含数据。用这种范例表示红黑树是可能的,但是这会改变一些属性并使算法复杂。为此,本文中我们使用 "nil 叶子" 或"空(null)叶子",如上图所示,它不包含数据而只充当树在此结束的指示。这些节点在绘图中经常被省略,导致了这些树好象同上述原则相矛盾,而实际上不是这样。与此有关的结论是所有节点都有两个子节点,尽管其中的一个或两个可能是空叶子。
三.构建原则
因为红黑树是一颗二叉平衡树,并且查找不会破坏树的平衡,所以查找跟二叉平衡树的查找无异:
- 从根结点开始查找,把根结点设置为当前结点;
- 若当前结点为空,返回null;
- 若当前结点不为空,用当前结点的key跟查找key作比较;
- 若当前结点key等于查找key,那么该key就是查找目标,返回当前结点;
- 若当前结点key大于查找key,把当前结点的左子结点设置为当前结点,重复步骤2;
- 若当前结点key小于查找key,把当前结点的右子结点设置为当前结点,重复步骤2;
插入操作包括两部分工作:一查找插入的位置;二插入后自平衡。查找插入的父结点很简单,跟查找操作区别不大:
- 从根结点开始查找;
- 若根结点为空,那么插入结点作为根结点,结束。
- 若根结点不为空,那么把根结点作为当前结点;
- 若当前结点为null,返回当前结点的父结点,结束。
- 若当前结点key等于查找key,那么该key所在结点就是插入结点,更新结点的值,结束。
- 若当前结点key大于查找key,把当前结点的左子结点设置为当前结点,重复步骤4;
- 若当前结点key小于查找key,把当前结点的右子结点设置为当前结点,重复步骤4;

红黑树的删除操作也包括两部分工作:一查找目标结点;而删除后自平衡。查找目标结点显然可以复用查找操作,当不存在目标结点时,忽略本次操作;当存在目标结点时,删除后就得做自平衡处理了。删除了结点后我们还需要找结点来替代删除结点的位置,不然子树跟父辈结点断开了,除非删除结点刚好没子结点,那么就不需要替代。
二叉树删除结点找替代结点有3种情情景:
- 情景1:若删除结点无子结点,直接删除
- 情景2:若删除结点只有一个子结点,用子结点替换删除结点
- 情景3:若删除结点有两个子结点,用后继结点(大于删除结点的最小结点)替换删除结点
补充说明下,情景3的后继结点是大于删除结点的最小结点,也是删除结点的右子树种最左结点。那么可以拿前继结点(删除结点的左子树最右结点)替代吗?
可以的。但习惯上大多都是拿后继结点来替代,后文的讲解也是用后继结点来替代。另外告诉大家一种找前继和后继结点的直观的方法(不知为何没人提过,大家都知道?):把二叉树所有结点投射在X轴上,所有结点都是从左到右排好序的,所有目标结点的前后结点就是对应前继和后继结点。
具体内容可见链接:https://www.jianshu.com/p/e136ec79235c