目录
- 线性回归
- 特点
- 最小二乘法
- 代码实现
- 多项式回归
- 特点
- 岭回归
- 特点:
- 共线性collinearity
- 优化函数
- 代码实现
- 套索回归Lasso
- 岭回归和套索回归对比
- 代码实现
- 弹性回归网络
- 特点:
线性回归
线性回归指的是全部由线性变量组成的回归模型
特点
建模速度快、对每个变量可以通过系数进行解释、对异常值很敏感
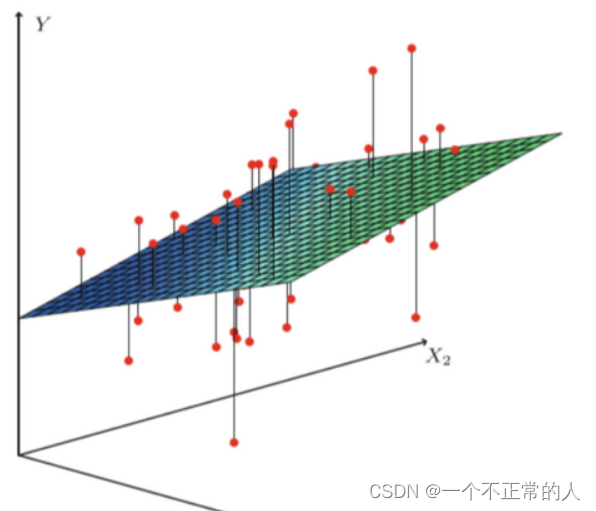
最小二乘法
通过数据点找到参数w和b,使得对训练集的预测值y与真实的回归目标值y’之间的MSE(均方误差)最小。
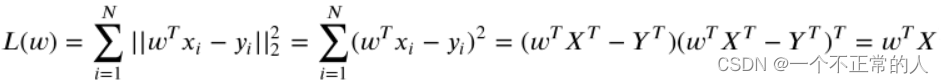
适用范围:
线性回归模型简单,但要求数据对目标变量成线性关系,所以如果面对非线性关系,需要转换非线性模型
特征变量较多的数据集
代码实现
from sklearn.linear_model import LinearRegression
reg = LinearRegression()
reg.fit(X,y)
print('直线的系数是:{:.2f}'.format(reg.coef_[0]))
print('直线的截距是:{:.2f}'.format(reg.intercept_))
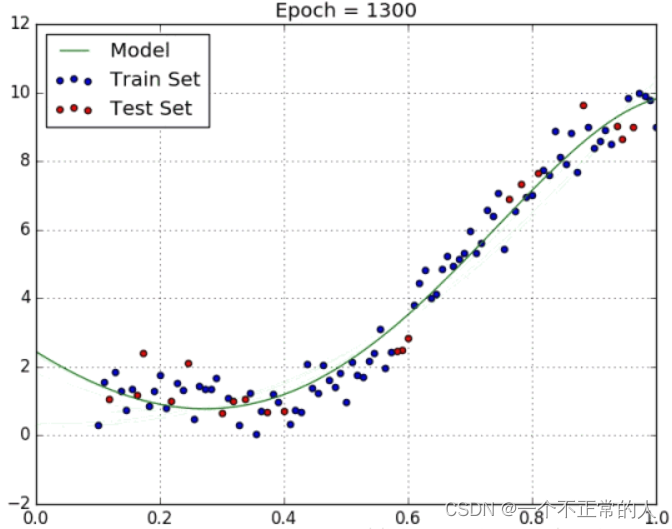
多项式回归
非线性模型——多项式回归
特点
拟合非线性变量,需要一些数据的先验知识来选择指数,选择不当会产生过拟合
岭回归
L2正则化的线性模型——岭回归
L2正则化保留全部特征变量,但会降低特征的系数值来避免过拟合
特点:
1、领回归的假设和最小平方回归相同,但是在最小平方回归的时候我们假设数据服从高斯分布使用的是极大似然估计(MLE),在领回归的时候由于添加了偏差因子,即w的先验信息,使用的是极大后验估计(MAP)来得到最终的参数
2、没有特征选择功能
共线性collinearity
自变量之间存在的,近似线性的关系。
回归分析需要我们了解每个变量与目标变量之间的关系,如果有两个变量x1和x2存在高共线性,那么x1的改变会影响x2也发生改变,这样就没办法确定是否是x1单独改变而对目标变量造成了影响,因为x1改变总是会混杂x2的作用,这样就造成了分析误差,所以回归分析时需要排除高共线性的影响。
判断高共线性的存在:
1、理论上变量x1与Y高度相关,但回归系数很低,不明显,有可能是因为x2的存在
2、添加或删除x1特征变量,回归系数发生明显变化,(x2会变化明显)
3、X特征变量具有较高的成对相关性(pairwise correlations)(检查相关矩阵)>0.7
4、回归分析时,直接查看VIF值,如果全部小于10(严格是5),则说明模型没有多重共线性问题,模型构建良好;反之若VIF大于10说明模型构建较差。
解决方法:

处理原则:
1、多共线性是普遍存在的,轻微的多重共线性问题可不采取措施,如果VIF值大于10说明共线性很严重,这种情况需要处理,如果VIF值在5以下不需要处理,如果VIF介于5~ 10之间视情况而定。
2、严重的多重共线性问题,一 般可根据经验或通过分析回归结果发现。如影响系数符号,重要的解释变量t值很低。要根据不同情况采取必要措施。
3、如果模型仅用于预测,则只要拟合程度好,可不处理多重共线性问题,存在多重共线性的模型用于预测时,往往不影响预测结果。
优化函数
岭回归是针对模型中存在的共线性关系的为变量增加一个小的平方偏差因子(也就是正则项)
代码实现
from sklearn.linear_model import Ridge
ridge = Ridge(alpha=1) #
ridge.fit(X,y)
print('岭回归的训练集得分是:{:.2f}'.format(ridge.score(X_train,y_train)))
print('岭回归的测试集得分是:{:.2f}'.format(ridge.score(X_test,y_test)))
套索回归Lasso
L1正则化的线性模型——套索回归
在回归优化函数中增加了一个偏置项以减少共线性的影响
套索回归会让模型更容易理解
岭回归和套索回归对比
岭回归和Lasso回归之间的差异可以归结为L1正则和L2正则之间的差异:
内置的特征选择(Built-in feature selection):这是L1范数很有用的一个属性,二L2范数不具有这种特性。因为L1范数倾向于产生稀疏系数。例如,模型中有100个系数,但其中只有10个系数是非零系数,也就是说只有这10个变量是有用的,其他90个都是没有用的。而L2范数产生非稀疏系数,所以没有这种属性。因此可以说Lasso回归做了一种参数选择形式,未被选中的特征变量对整体的权重为0。
稀疏性:指矩阵或向量中只有极少个非零系数。L1范数具有产生具有零值或具有很少大系数的非常小值的许多系数的属性。
计算效率:L1范数咩有解析解,但L2范数有。这使得L2范数的解可以通过计算得到。L1范数的解具有稀疏性,这使得它可以与稀疏算法一起使用,这使得在计算上更有效率。
代码实现
from sklearn.linear_model import Lasso
lasso = Lasso(alpha=0.1, max_iter=10000) #max_iter最大迭代次数
lasso.fit(X,y)
print('Lasso回归的训练集得分是:{:.2f}'.format(lasso.score(X_train,y_train)))
print('Lasso回归的测试集得分是:{:.2f}'.format(lasso.score(X_test,y_test)))
弹性回归网络
弹性回归网络是Lesso回归和岭回归技术的混合体。它使用了L1和L2正则化
特点:
1、鼓励在高度相关变量的情况下的群体效应,而不像Lasso那样将其中一些置为0.当多个特征和另一个特征相关的时候弹性网络非常有用。Lasso倾向于随机选择其中一个,而弹性网络倾向于选择两个。
2、 对所选变量的数量没有限制。