目录
1.逻辑回归模型
2. KNN模型
3.随机森林模型
4.决策树模型
5.贝叶斯模型
6.支持向量机模型
步骤:
- 导入必要的第三方库
- 读取数据
- 划分数据集
- 可选操作,引入停用词,当作参数传入特征提取器
- 特征提取
- 提取的向量当作特征传入逻辑回归模型
1.逻辑回归模型
使用TF_IDF提取的向量当作特征传入逻辑回归模型
#首先将用到的包进行导入
import pandas as pd
import numpy as np
import jieba
import re
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
from sklearn import model_selection
from sklearn import preprocessing#将数据进行读取
data=pd.read_csv('评论汇总-分词后.csv',index_col=0)# 现在是划分数据集
# random_state 取值,这是为了在不同环境中,保证随机数取值一致,以便验证模型的实际效果。
train_x, test_x, train_y, test_y = model_selection.train_test_split(data.分词.values.astype('U'), data.分数.values,test_size=0.1, random_state=1)# 划分完毕,查看数据形状
print(train_x.shape, test_x.shape)
# train_x 训练集数据 test_x 测试集数据 train_y训练集的标签 test_y 测试集的标签
''''''
#定义函数,从哈工大中文停用词表里面,把停用词作为列表格式保存并返回 在这里加上停用词表是因为TfidfVectorizer和CountVectorizer的函数中
#可以根据提供用词里列表进行去停用词
def get_stopwords(stop_word_file):custom_stopwords_list = [line.strip() for line in open(stop_word_file, encoding='UTF-8').readlines()]return custom_stopwords_list#获得由停用词组成的列表
stop_words_file = 'cn_stopwords.txt'
stopwords = get_stopwords(stop_words_file)'''
使用TfidfVectorizer()和 CountVectorizer()分别对数据进行特征的提取,投放到不同的模型中进行实验
'''
# 开始使用TF-IDF进行特征的提取,对分词后的中文语句做向量化。
# 引进TF-IDF的包
TF_Vec = TfidfVectorizer(max_df=0.8,min_df=3,stop_words=frozenset(stopwords))
# 拟合数据,将数据准转为标准形式,一般使用在训练集中
train_x_tfvec = TF_Vec.fit_transform(train_x)
# 通过中心化和缩放实现标准化,一般使用在测试集中
test_x_tfvec = TF_Vec.transform(test_x)# 开始使用CountVectorizer()进行特征的提取。它依据词语出现频率转化向量。并且加入了去除停用词
CT_Vec = CountVectorizer(max_df=0.8, # 在超过这一比例的文档中出现的关键词(过于平凡),去除掉。min_df=3, # 在低于这一数量的文档中出现的关键词(过于独特),去除掉。token_pattern=u'(?u)\\b[^\\d\\W]\\w+\\b', # 使用正则表达式,去除想去除的内容stop_words=frozenset(stopwords)) # 加入停用词)
# 拟合数据,将数据转化为标准形式,一般使用在训练集中
train_x_ctvec = CT_Vec.fit_transform(train_x)
# 通过中心化和缩放实现标准化,一般使用在测试集中
test_x_ctvec = CT_Vec.transform(test_x)'''
使用TF_IDF提取的向量当作数据特征传入模型
'''
#构建模型之前首先将包进行导入
from sklearn import linear_model
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split, GridSearchCV
import time
start_time=time.time()
#创建模型
lr = linear_model.LogisticRegression(penalty='l2', C=1, solver='liblinear', max_iter=1000, multi_class='ovr')
#进行模型的优化,因为一些参数是不确定的,所以就让模型自己在训练中去确定自己的参数 模型的名字也由LR转变为modelmodel = GridSearchCV(lr, cv=3, param_grid={'C': np.logspace(0, 4, 30),'penalty': ['l1', 'l2']})
#模型拟合tf-idf拿到的数据
model.fit(train_x_tfvec,train_y)
#查看模型自己拟合的最优参数
print('最优参数:', model.best_params_)
#在训练时查看训练集的准确率
pre_train_y=model.predict(train_x_tfvec)
#在训练集上的正确率
train_accracy=accuracy_score(pre_train_y,train_y)
#训练结束查看预测 输入验证集查看预测
pre_test_y=model.predict(test_x_tfvec)
#查看在测试集上的准确率
test_accracy = accuracy_score(pre_test_y,test_y)
print('使用TF-IDF提取特征使用逻辑回归,让模型自适应参数,进行模型优化\n训练集:{0}\n测试集:{1}'.format(train_accracy,test_accracy))
end_time=time.time()
print("使用模型优化的程序运行时间为",end_time-start_time)测试结果如下:
使用ConutVector转化的向量作为特征传入逻辑回归模型
#1.首先将要用到的包进行导入
import numpy as np
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn import model_selection#2.读取数据
data = pd.read_csv('评论汇总-分词后.csv', index_col=0)#3.划分数据集
'''
备注:将“评论”数据当做X,将“评分”数据当做Y。将数据集划分成训练数据与测试数据,训练数据用来训练机器学习算法,测试数据用于检测通过训练数据训练出来的算法的效果。划分数据集的时候需要用到sklearn中的model_selection中的train_test_split()方法。需要传入的参数为“评论文本”、“文本的评分”(这里的好评还是差评对应的数字)、test_size表示是划分数据集与训练集的比例,根据划分的比例,将数据划分为10等分,测试集占据其中一份。shuffle的作用是在划分数据集时,会将数据顺序打乱。
train_x:训练数据集
test_x:测试数据集
train_y:训练数据集的标签
test_y:测试数据集的标签
random_state:这是为了在不同的环境中,保证随机数取值一致,以便验证模型的效果
'''
train_x,test_x,train_y,test_y = model_selection.train_test_split(data.分词.values.astype('U'),data.分数.values,test_size=0.1,random_state=1)
#划分完毕,查看数据形状
print(train_x.shape,test_y.shape)def get_stopwords(stop_word_file):custom_stopwords_list = [line.strip() for line in open(stop_word_file, encoding='UTF-8').readlines()]return custom_stopwords_list#获得由停用词组成的列表
stop_words_file = 'cn_stopwords.txt'
stopwords = get_stopwords(stop_words_file)
#4. CountVectorizer()分别进行特征提取
#开始使用 CountVectorizer()分别进行特征提取。他可以依据词语出现评率转化向量。并且加入去除停用词,这里数据集已经去除停用词,所以没有使用
CT_Vec = CountVectorizer(max_df=0.8, #在超过这一比例的文档中出现的关键词(过于平凡),去除掉min_df=3, #在低于这一数量的文档中出现关键词(过于独特),去除掉token_pattern=u'(?u)\\b[^\\d\\W]\\w+\\b',#使用正则表达式,去除想去的内容stop_words=frozenset(stopwords))
#拟合数据,将数据转化为标准形式,一般在使用在训练集中
train_x_ctvec = CT_Vec.fit_transform(train_x)
#通过中心化和缩放现实标准化,一般使用在测试集中
test_x_ctvec = CT_Vec.transform(test_x)#5.使用ConutVector转化的向量作为特征传入逻辑回归模型
#构造模型之前首先将包进行导入
from sklearn import linear_model
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split,GridSearchCV
import time
start_time = time.time()
#创建模型
print("无优化")
model = linear_model.LogisticRegression(penalty='l2',C=1,solver='liblinear',max_iter=1000,multi_class='ovr')
#进行模型的优化,因为一些参数是不确定的,所以就让模型自己在训练中去确定自己的参数 模型的名字也由LR转为model
'''
model = GridSearchCV(lr, cv=3,param_grid={'C':np.logspace(0,4,30),'penalty':['l1','l2']
})
'''#模型拟合CountVectorizer拿到数据
model.fit(train_x_ctvec,train_y)
#查看自己拟合的最优化参数
#print("最优化参数:",model.best_params_)
#在训练时查看数据集的准确率
pre_train_y = model.predict(train_x_ctvec)
#在训练集上的正确率
train_accuracy = accuracy_score(pre_train_y,train_y)
#训练结束查看预测 输入测试集查看预测
pre_test_y = model.predict(test_x_ctvec)
#查看在测试集上的准确率
test_accuracy = accuracy_score(pre_test_y,test_y)
print("使用CountVectorizer提取特征使用逻辑回归,让模型自适应参数,进行模型优化\n训练集:{0}\n测试集:{1}".format(train_accuracy,test_accuracy))
end_time = time.time()
print("使用模型优化的程序运行时间为:",end_time-start_time)测试结果如下:

2. KNN模型
#首先将用到的包进行导入
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
from sklearn import model_selection#将数据进行读取
data=pd.read_csv('评论汇总-分词后.csv',index_col=0)# 现在是划分数据集
# random_state 取值,这是为了在不同环境中,保证随机数取值一致,以便验证模型的实际效果。
train_x, test_x, train_y, test_y = model_selection.train_test_split(data.分词.values.astype('U'), data.分数.values,test_size=0.1, random_state=1)# 划分完毕,查看数据形状
print(train_x.shape, test_x.shape)
# train_x 训练集数据 test_x 测试集数据 train_y训练集的标签 test_y 测试集的标签
#定义函数,从哈工大中文停用词表里面,把停用词作为列表格式保存并返回 在这里加上停用词表是因为TfidfVectorizer和CountVectorizer的函数中
#可以根据提供用词里列表进行去停用词
def get_stopwords(stop_word_file):custom_stopwords_list = [line.strip() for line in open(stop_word_file, encoding='UTF-8').readlines()]return custom_stopwords_list#获得由停用词组成的列表
stop_words_file = 'cn_stopwords.txt'
stopwords = get_stopwords(stop_words_file)'''
使用TfidfVectorizer()和 CountVectorizer()分别对数据进行特征的提取,投放到不同的模型中进行实验
'''
# 开始使用TF-IDF进行特征的提取,对分词后的中文语句做向量化。
# 引进TF-IDF的包
TF_Vec = TfidfVectorizer(max_df=0.8,min_df=3,stop_words=frozenset(stopwords))
# 拟合数据,将数据准转为标准形式,一般使用在训练集中
train_x_tfvec = TF_Vec.fit_transform(train_x)
# 通过中心化和缩放实现标准化,一般使用在测试集中
test_x_tfvec = TF_Vec.transform(test_x)'''
使用KNN模型
'''
import time
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
start_time = time.time()
#创建模型
Kn = KNeighborsClassifier()
#拟合从tf-idf拿到的数据
Kn.fit(train_x_tfvec,train_y)
#在训练时查看训练集的准确率
pre_train_y = Kn.predict(train_x_tfvec)
#在训练集上的正确率
train_accuracy = accuracy_score(pre_train_y,train_y)
#训练结束查看预测 输入测试集查看预测
pre_test_y = Kn.predict(test_x_tfvec)
#查看在测试集上的准确率
test_accuracy = accuracy_score(pre_test_y,test_y)
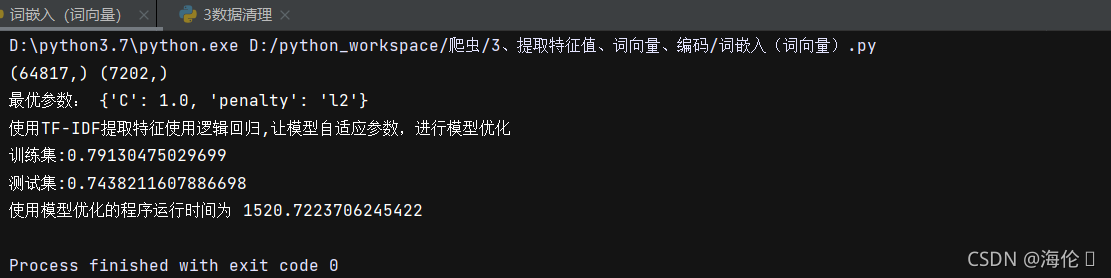
print('使用TfidfVectorizer提取特征使用KNN分类器的准确率\n训练集:{0}\n测试集:{1}'.format(train_accuracy,test_accuracy))
end_time = time.time()
print('使用KNN分类器的程序运行时间为:',end_time - start_time)
测试结果如下:
3.随机森林模型
#首先将用到的包进行导入
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
from sklearn import model_selection#将数据进行读取
data=pd.read_csv('评论汇总-分词后.csv',index_col=0)# 现在是划分数据集
train_x, test_x, train_y, test_y = model_selection.train_test_split(data.分词.values.astype('U'), data.分数.values,test_size=0.1, random_state=1)
# 划分完毕,查看数据形状
print(train_x.shape, test_x.shape)
# train_x 训练集数据 test_x 测试集数据 train_y训练集的标签 test_y 测试集的标签
#定义函数,从哈工大中文停用词表里面,把停用词作为列表格式保存并返回 在这里加上停用词表是因为TfidfVectorizer和CountVectorizer的函数中
'''
使用TfidfVectorizer()对数据进行特征的提取,投放到不同的模型中进行实验
'''
# 开始使用TF-IDF进行特征的提取,对分词后的中文语句做向量化。
# 引进TF-IDF的包
TF_Vec = TfidfVectorizer(max_df=0.8,min_df=3)
# 拟合数据,将数据准转为标准形式,一般使用在训练集中
train_x_tfvec = TF_Vec.fit_transform(train_x)
# 通过中心化和缩放实现标准化,一般使用在测试集中
test_x_tfvec = TF_Vec.transform(test_x)'''
开始训练random forest classifier (随机森林)模型
'''
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import time
start_time = time.time()
#创建模型
Rfc = RandomForestClassifier(n_estimators=8)
#拟合从TfidfVectorizer()中拿到的数据
Rfc.fit(train_x_tfvec,train_y)
#在训练时查看训练集的准确率
pre_train_y = Rfc.predict(train_x_tfvec)
#在训练集上的准确率
train_accuracy = accuracy_score(pre_train_y,train_y)
#在训练时查看测试集的准确率
pre_test_y = Rfc.predict(test_x_tfvec)
#在测试集上的正确率
test_accuracy = accuracy_score(pre_test_y,test_y)
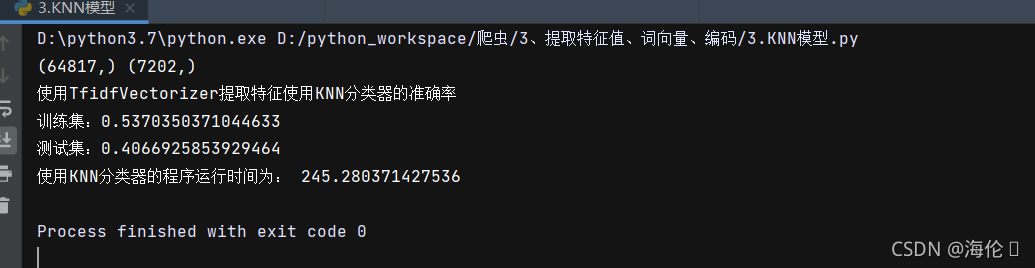
print('使用TfidfVectorizer提取特征使用随机森林分类器的准确率\n训练集:{0}\n测试集:{1}'.format(train_accuracy,test_accuracy))
end_time = time.time()
print('使用随机森林分类器的程序运行时间为:',end_time - start_time)测试结果如下:
4.决策树模型
#1.首先将包导入
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn import model_selection#2.读取数据
data = pd.read_csv('评论汇总-分词后.csv',index_col=0)#3.划分数据集
train_x, test_x, train_y, test_y = model_selection.train_test_split(data.分词.values.astype('U'),data.分数.values,test_size=0.1,random_state=1)
#划分完毕,查看数据形状
print(train_x.shape,test_x.shape)#4.使用TfidfVectorizer()对数据进行特征提取,放到模型进行训练
#银镜TF-IDF的包
TF_Vec = TfidfVectorizer(max_df=0.8,min_df=3)
#拟合数据,将数据标准化,一般使用在训练集中
train_x_tfvec = TF_Vec.fit_transform(train_x)
#通过中心化和缩放实现标准化,一般使用在测试集中
test_x_tfvec = TF_Vec.transform(test_x)'''
5.开始训练模型
Decison Tree Classifier 决策树
'''
from sklearn import tree
from sklearn.metrics import accuracy_score
import time
start_time = time.time()
#创建模型
Rf = tree.DecisionTreeClassifier()
#拟合从tf-idf拿到的数据
Rf.fit(train_x_tfvec,train_y)
#在训练时查看准确率
pre_train_y = Rf.predict(train_x_tfvec)
#在训练集上的正确率
train_accuracy = accuracy_score(pre_train_y,train_y)
#训练结束查看预测 输入测试集查看预测
pre_test_y = Rf.predict(test_x_tfvec)
#查看在测试集上的准确率
test_accuracy = accuracy_score(pre_test_y,test_y)
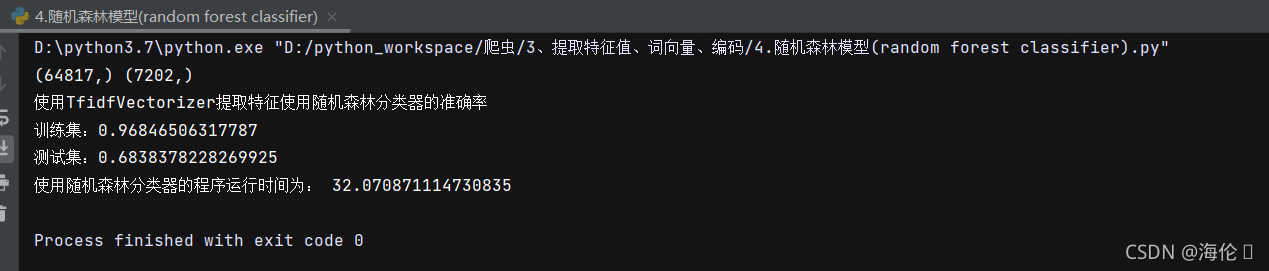
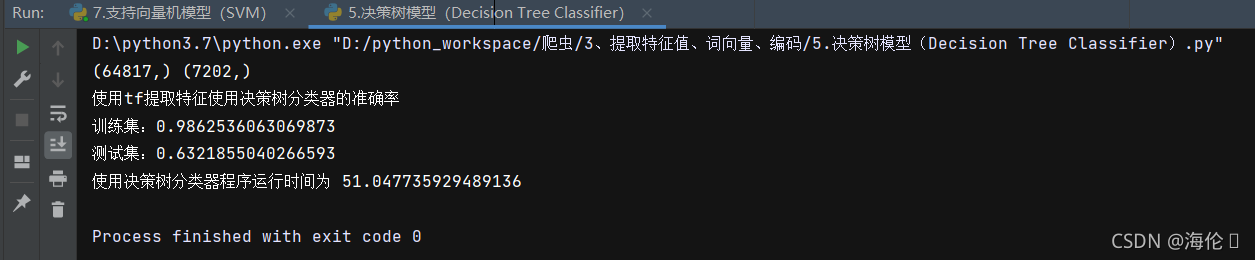
print('使用tf提取特征使用决策树分类器的准确率\n训练集:{0}\n测试集:{1}'.format(train_accuracy,test_accuracy))
end_time = time.time()
print('使用决策树分类器程序运行时间为',end_time-start_time)测试结果如下:
5.贝叶斯模型
#1.首先将包导入
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn import model_selection#2.读取数据
data = pd.read_csv('评论汇总-分词后.csv',index_col=0)#3.划分数据集
train_x, test_x, train_y, test_y = model_selection.train_test_split(data.分词.values.astype('U'),data.分数.values,test_size=0.1,random_state=1)
#划分完毕,查看数据形状
print(train_x.shape,test_x.shape)#4.使用TfidfVectorizer()对数据进行特征提取,放到模型进行训练
#银镜TF-IDF的包
TF_Vec = TfidfVectorizer(max_df=0.8,min_df=3)
#拟合数据,将数据标准化,一般使用在训练集中
train_x_tfvec = TF_Vec.fit_transform(train_x)
#通过中心化和缩放实现标准化,一般使用在测试集中
test_x_tfvec = TF_Vec.transform(test_x)'''
5.开始训练模型
Decison Tree Classifier 决策树
'''
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score
import time
start_time = time.time()
#创建模型
Bys = MultinomialNB()
#拟合数据
Bys.fit(train_x_tfvec,train_y)
#在训练时查看训练集的准确率
pre_train_y = Bys.predict(train_x_tfvec)
#在训练集上的准确率
train_accuracy = accuracy_score(pre_train_y,train_y)
#训练结束 查看预测 输入测试集查看预测
pre_test_y = Bys.predict(test_x_tfvec)
#查看在测试集上的准确率
test_accuracy = accuracy_score(pre_test_y, test_y)
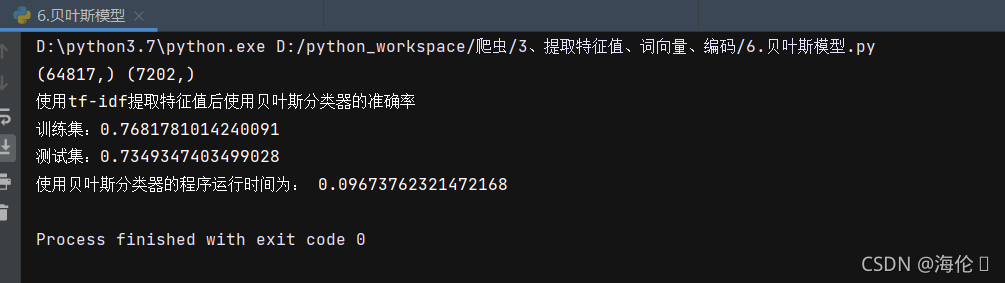
print('使用tf-idf提取特征值后使用贝叶斯分类器的准确率\n训练集:{0}\n测试集:{1}'.format(train_accuracy,test_accuracy))
end_time = time.time()
print('使用贝叶斯分类器的程序运行时间为:',end_time-start_time)测试结果如下:
6.支持向量机模型
#1.首先将包导入
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn import model_selection#2.读取数据
data = pd.read_csv('评论汇总-分词后.csv',index_col=0)#3.划分数据集
train_x, test_x, train_y, test_y = model_selection.train_test_split(data.分词.values.astype('U'),data.分数.values,test_size=0.1,random_state=1)
#划分完毕,查看数据形状
print(train_x.shape,test_x.shape)#4.使用TfidfVectorizer()对数据进行特征提取,放到模型进行训练
#银镜TF-IDF的包
TF_Vec = TfidfVectorizer(max_df=0.8,min_df=3)
#拟合数据,将数据标准化,一般使用在训练集中
train_x_tfvec = TF_Vec.fit_transform(train_x)
#通过中心化和缩放实现标准化,一般使用在测试集中
test_x_tfvec = TF_Vec.transform(test_x)'''
5.开始训练模型
SVM分类器
'''
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
import time
start_time = time.time()
#创建模型
SVM = SVC(C=1.0,kernel='rbf',gamma='auto')
#拟合数据
SVM.fit(train_x_tfvec,train_y)
#训练集
pre_train_y = SVM.predict(train_x_tfvec)
train_accuracy = accuracy_score(pre_train_y,train_y)
#测试集
pre_test_y = SVM.predict(test_x_tfvec)
test_accuracy = accuracy_score(pre_test_y,test_y)
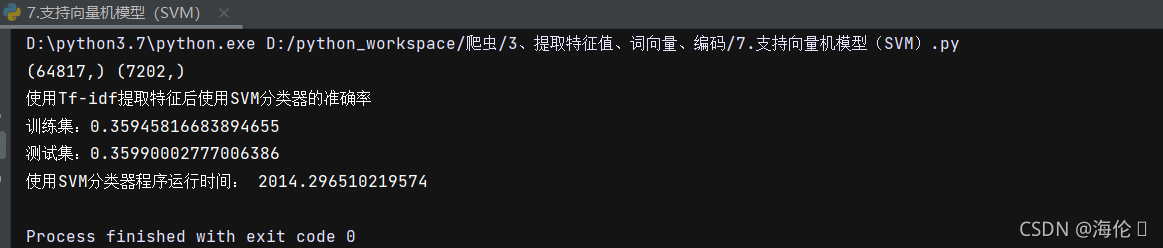
print('使用Tf-idf提取特征后使用SVM分类器的准确率\n训练集:{0}\n测试集:{1}'.format(train_accuracy,test_accuracy))
end_time = time.time()
print('使用SVM分类器程序运行时间:',end_time-start_time)测试结果如下:
参考文章:
自然语言处理(NLP)案例--机器学习进行情感分析_Dong_ZH的博客-CSDN博客_nlp案例目录一、数据清洗1.导入必要的库2.创建停用词表3.对句子进行中文分词4.给出文档路径5.将结果输出保存并且打印处理过程二、转换数据格式1.将处理完毕的数据读取查看2.新建pands对象3. 将txt文件中的评论数据按行写入csv文件4.将读取评分数据5.将评分数据以逗号形式分割6.将评分数据作为label按行写入csv文件7.查看数据,并将数据保存为CSV格式三、机器学习部分1.导入必要的第三方库2.读取数据3.划分数据集...https://blog.csdn.net/weixin_44750512/article/details/108486327















![[android基础]《疯狂android讲义》重点整理(2)](https://img-blog.csdn.net/20170204141540816?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvU0FORFlDTEFJUkU=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center)