目录
用户评论情感极性判别
一、数据准备
二、数据预处理
三、文本特征提取
四、将数据转换为DMatrix类型
五、构建XGBoost模型
1、XGBoost模型主要参数
(1)通用参数
(2)Booster参数
(3)学习目标参数
2、XGBoost模型
(1)基于XGBoost原生接口的分类
(2)基于Scikit-learn接口的分类
六、使用XGBoost做预测,并对模型进行评估
七、LightGBM文本分类
用户评论情感极性判别
一、数据准备
训练集:data_train.csv ,样本数为82025,情感极性标签(0:负面、1:中性、2:正面)
测试集:data_test.csv ,样本数为35157
评论数据主要包括:食品餐饮类,旅游住宿类,金融服务类,医疗服务类,物流快递类;部分数据如下:

二、数据预处理
主要进行中文分词和停用词过滤。
预处理后训练集:clean_train_data.csv
预处理后测试集:clean_test_data.csv
预处理后的部分数据如下:

数据集预处理部分代码如下:
import pandas as pd
import jieba
#去除停用词,返回去除停用词后的文本列表
def clean_stopwords(contents):contents_list=[]stopwords = {}.fromkeys([line.rstrip() for line in open('data/stopwords.txt', encoding="utf-8")]) #读取停用词表stopwords_list = set(stopwords)for row in contents: #循环去除停用词words_list = jieba.lcut(row)words = [w for w in words_list if w not in stopwords_list]sentence=' '.join(words) #去除停用词后组成新的句子contents_list.append(sentence)return contents_list
# 将清洗后的文本和标签写入.csv文件中
def after_clean2csv(contents, labels): #输入为文本列表和标签列表columns = ['contents', 'labels']save_file = pd.DataFrame(columns=columns, data=list(zip(contents, labels)))save_file.to_csv('data/clean_data_test.csv', index=False, encoding="utf-8")if __name__ == '__main__':train_data = pd.read_csv('data/data_test.csv', sep='\t',names=['ID', 'type', 'review', 'label']).astype(str)labels=[]for i in range(len(train_data['label'])):labels.append(train_data['label'][i])contents=clean_stopwords(train_data['review'])after_clean2csv(contents,labels)三、文本特征提取
使用sklearn计算训练集的TF-IDF,并将训练集和测试集分别转换为TF-IDF权重矩阵,作为模型的输入。
# coding=utf-8
import pandas as pd
import xgboost as xgb
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn import metrics
from sklearn.model_selection import train_test_splitif __name__ == '__main__':train_data = pd.read_csv('data/clean_data_train.csv', sep=',', names=['contents', 'labels']).astype(str)cw = lambda x: int(x)train_data['labels']=train_data['labels'].apply(cw)x_train, x_test, y_train, y_test = train_test_split(train_data['contents'], train_data['labels'], test_size=0.1)# 将语料转化为词袋向量,根据词袋向量统计TF-IDFvectorizer = CountVectorizer(max_features=5000)tf_idf_transformer = TfidfTransformer()tf_idf = tf_idf_transformer.fit_transform(vectorizer.fit_transform(x_train))x_train_weight = tf_idf.toarray() # 训练集TF-IDF权重矩阵tf_idf = tf_idf_transformer.transform(vectorizer.transform(x_test))x_test_weight = tf_idf.toarray() # 测试集TF-IDF权重矩阵
四、将数据转换为DMatrix类型
XGBoost 的二进制的缓存文件,加载的数据存储在对象 DMatrix 中。
# 将数据转化为DMatrix类型dtrain = xgb.DMatrix(x_train_weight, label=y_train)dtest = xgb.DMatrix(x_test_weight, label=y_test)# 保存测试集数据,以便模型训练完成直接调用# dtest.save_binary('data/dtest.buffer')
五、构建XGBoost模型
XGBoost有两大类接口:XGBoost原生接口 和 scikit-learn接口 ,并且XGBoost能够实现 分类 和 回归 两种任务。
1、XGBoost模型主要参数
XGBoost所有的参数分成了三类:通用参数:宏观函数控制;Booster参数:控制每一步的booster;目标参数:控制训练目标的表现。
(1)通用参数
- booster[默认gbtree]:gbtree:基于树的模型、gbliner:线性模型
- silent[默认0]:值为1时,静默模式开启,不会输出任何信息
- nthread[默认值为最大可能的线程数]:这个参数用来进行多线程控制,应当输入系统的核数。 如果你希望使用CPU全部的核,那就不要输入这个参数,算法会自动检测它
(2)Booster参数
这里只介绍tree booster,因为它的表现远远胜过linear booster,所以linear booster很少用到
- eta[默认0.3]:和GBM中的 learning rate 参数类似。 通过减少每一步的权重,可以提高模型的鲁棒性。常用的值为0.2, 0.3
- max_depth[默认6]:这个值为树的最大深度。max_depth越大,模型会学到更具体更局部的样本。常用的值为6
- gamma[默认0]:Gamma指定了节点分裂所需的最小损失函数下降值。 这个参数的值越大,算法越保守。这个参数的值和损失函数息息相关。
- subsample[默认1]:这个参数控制对于每棵树,随机采样的比例。 减小这个参数的值,算法会更加保守,避免过拟合。但是,如果这个值设置得过小,它可能会导致欠拟合。 常用的值:0.7-1
- colsample_bytree[默认1]:用来控制每棵随机采样的列数的占比(每一列是一个特征)。 常用的值:0.7-1
(3)学习目标参数
- objective[默认reg:linear]:这个参数定义需要被最小化的损失函数。binary:logistic二分类的逻辑回归,返回预测的概率。multi:softmax 使用softmax的多分类器,返回预测的类别。这种情况下,还需要多设一个参数:num_class(类别数目)。 multi:softprob 和multi:softmax参数一样,但是返回的是每个数据属于各个类别的概率。
- eval_metric[默认值取决于objective参数的取值]:对于有效数据的度量方法。 对于回归问题,默认值是rmse,对于分类问题,默认值是error。其他的值:rmse 均方根误差; mae 平均绝对误差;logloss 负对数似然函数值;error 二分类错误率(阈值为0.5); merror 多分类错误率;mlogloss 多分类logloss损失函数;auc 曲线下面积。
- seed[默认0]:随机数的种子 设置它可以复现随机数据的结果。
2、XGBoost模型
(1)基于XGBoost原生接口的分类
#基于XGBoost原生接口的分类#xgboost模型构建param = {'silent': 0, 'eta': 0.3, 'max_depth': 6, 'objective': 'multi:softmax', 'num_class': 3, 'eval_metric': 'merror'} # 参数evallist = [(dtrain, 'train'), (dtest, 'test')]num_round = 100 # 循环次数xgb_model = xgb.train(param, dtrain, num_round,evallist)# 保存训练模型# xgb_model.save_model('data/xgb_model')# xgb_model=xgb.Booster(model_file='data/xgb_model') #加载训练好的xgboost模型(2)基于Scikit-learn接口的分类
#基于Scikit-learn接口的分类# 训练模型model = xgb.XGBClassifier(max_depth=6, learning_rate=0.1, n_estimators=100, silent=True, objective='multi:softmax')model.fit(x_train_weight, y_train)y_predict=model.predict(x_test_weight)六、使用XGBoost做预测,并对模型进行评估
'''#利用训练完的模型直接测试xgb_model = xgb.Booster(model_file='data/xgb_model') # init model #加载模型dtest = xgb.DMatrix('data/test.buffer') #加载数据xgb_test(dtest,xgb_model)'''y_predict = xgb_model.predict(dtest) # 模型预测label_all = ['负面', '中性','正面']confusion_mat = metrics.confusion_matrix(y_test, y_predict)df = pd.DataFrame(confusion_mat, columns=label_all)df.index = label_allprint('准确率:', metrics.accuracy_score(y_test, y_predict))print('confusion_matrix:', df)print('分类报告:', metrics.classification_report(y_test, y_predict))
模型分类结果如下:

七、LightGBM文本分类
# coding=utf-8
import pandas as pd
import numpy as np
from sklearn import metrics
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
import lightgbm as lgb
from sklearn.model_selection import train_test_splitif __name__ == '__main__':train_data = pd.read_csv('data/clean_data_train.csv', sep=',', names=['contents', 'labels']).astype(str)'''test_data = pd.read_csv('data/clean_data_test.csv', sep=',', names=['contents', 'labels']).astype(str)cw = lambda x: int(x)x_train = train_data['contents']y_train = np.array(train_data['labels'].apply(cw))x_test = test_data['contents']y_test = np.array(test_data['labels'].apply(cw))'''x_train, x_test, y_train, y_test = train_test_split(train_data['contents'], train_data['labels'], test_size=0.1)cw = lambda x: int(x)x_train = x_trainy_train = np.array(y_train.apply(cw))x_test = x_testy_test = np.array(y_test.apply(cw))# 将语料转化为词袋向量,根据词袋向量统计TF-IDFvectorizer = CountVectorizer(max_features=5000)tf_idf_transformer = TfidfTransformer()tf_idf = tf_idf_transformer.fit_transform(vectorizer.fit_transform(x_train))x_train_weight = tf_idf.toarray() # 训练集TF-IDF权重矩阵tf_idf = tf_idf_transformer.transform(vectorizer.transform(x_test))x_test_weight = tf_idf.toarray() # 测试集TF-IDF权重矩阵# 创建成lgb特征的数据集格式lgb_train = lgb.Dataset(x_train_weight, y_train)lgb_val = lgb.Dataset(x_test_weight, y_test, reference=lgb_train)# 构建lightGBM模型params = {'max_depth': 5, 'min_data_in_leaf': 20, 'num_leaves': 35,'learning_rate': 0.1, 'lambda_l1': 0.1, 'lambda_l2': 0.2,'objective': 'multiclass', 'num_class': 3, 'verbose': -1}# 设置迭代次数,默认为100,通常设置为100+num_boost_round = 1000# 训练 lightGBM模型gbm = lgb.train(params, lgb_train, num_boost_round, verbose_eval=100, valid_sets=lgb_val)# 保存模型到文件# gbm.save_model('data/lightGBM_model')# 预测数据集y_pred = gbm.predict(x_test_weight, num_iteration=gbm.best_iteration)y_predict = np.argmax(y_pred, axis=1) # 获得最大概率对应的标签label_all = ['负面', '中性', '正面']confusion_mat = metrics.confusion_matrix(y_test, y_predict)df = pd.DataFrame(confusion_mat, columns=label_all)df.index = label_allprint('准确率:', metrics.accuracy_score(y_test, y_predict))print('confusion_matrix:', df)print('分类报告:', metrics.classification_report(y_test, y_predict))
分类结果如下:

项目实战:XGBoost与LightGBM文本分类源代码及数据集资源下载:
XGBoost与LightGBM文本分类源代码及数据集.zip-机器学习文档类资源-CSDN下载
参考:
1、安装包下载网址
2、XGBoost学习文档
3、XGBoost和LightGBM的参数以及调参
4、XGBoost数据比赛之调参
5、LightGBM调参笔记
6、kaggle——泰坦尼克之灾(基于LGBM)
本人博文NLP学习内容目录:
一、NLP基础学习
1、NLP学习路线总结
2、TF-IDF算法介绍及实现
3、NLTK使用方法总结
4、英文自然语言预处理方法总结及实现
5、中文自然语言预处理方法总结及实现
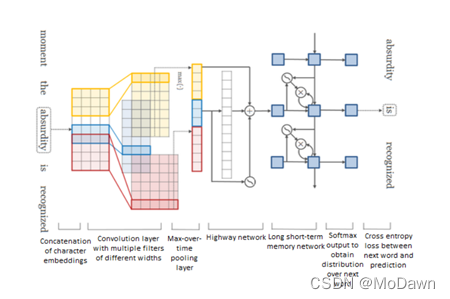
6、NLP常见语言模型总结
7、NLP数据增强方法总结及实现
8、TextRank算法介绍及实现
9、NLP关键词提取方法总结及实现
10、NLP词向量和句向量方法总结及实现
11、NLP句子相似性方法总结及实现
12、NLP中文句法分析
二、NLP项目实战
1、项目实战-英文文本分类-电影评论情感判别
2、项目实战-中文文本分类-商品评论情感判别
3、项目实战-XGBoost与LightGBM文本分类
4、项目实战-TextCNN文本分类实战
5、项目实战-Bert文本分类实战
6、项目实战-NLP中文句子类型判别和分类实战
交流学习资料共享欢迎入群:955817470(群一),801295159(群二)