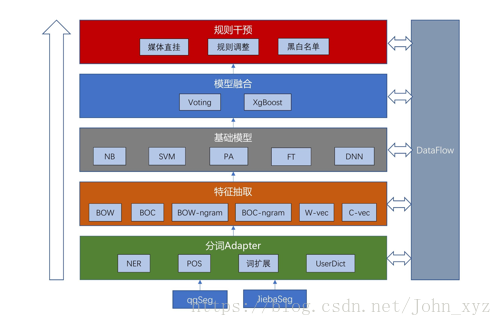
基础普及: https://zhuanlan.zhihu.com/p/25928551
综述类(有不同算法在各数据集上的性能对比):
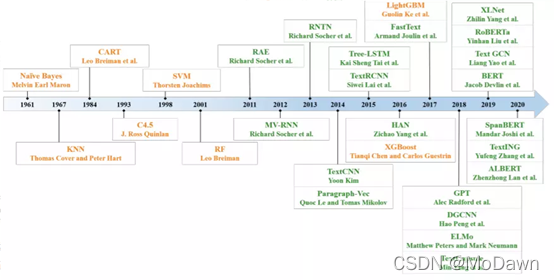
Deep Learning Based Text Classification:A Comprehensive Review(20.04)
A Survey on Text Classification: From Shallow to Deep Learning(20.08)
复现: https://github.com/wellinxu/nlp_store
总体步骤:输入文档 -> 预处理 -> 文本表示 -> 分类器 -> 类别输出
主要流程:预处理模型的文本数据;
浅层学习模型通常需要通过人工方法获得良好的样本特征,然后使用经典的机器学习算法对其进行分类,其有效性在很大程度上受到特征提取的限制;
而深度学习通过学习一组非线性变换将特征工程直接集成到输出中,从而将特征工程集成到模型拟合过程中。
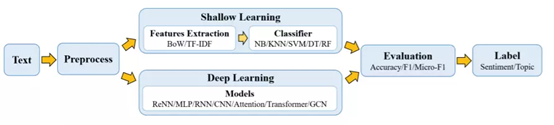
浅层学习仍然需要进行耗时又昂贵的功能设计,还通常会忽略文本数据中的自然顺序结构或上下文信息,使学习单词的语义信息变得困难,适用于小数据集。
深度学习方法避免了人工设计规则和功能,并自动为文本挖掘提供了语义上有意义的表示形式,文本分类只是其下游NLP任务之一。它是数据驱动的方法,具有很高的计算复杂性,较浅层模型难以解释其原因和工作方式。需提高其语义表示能力和鲁棒性。
常见应用:垃圾邮件识别、情感分类(SA)、新闻分类(NC)、主题分析(TL)、
问答(QA)、对话行为分类(DAC)、自然语言推理(NLI)、事件预测(EP)
类别:二分类、多分类、多标签分类;机器学习、深度学习
一、预处理
分词、去停用词(中文)、词性标注(多省略)、数据清理和数据统计
分析输入数据集,对其进行分类(如单标签,多标签,无监督,不平衡的数据集,多章,短文本,跨语言,多标签,少样本文本,包含术语词汇)
分词方法:基于字符串匹配、基于理解、
基于统计:N元文法模型(N-gram),最大熵模型(ME),
隐马尔可夫模型(Hidden Markov Model ,HMM),
条件随机场模型(Conditional Random Fields,CRF)等

句子化为等长:对于不同长度的文本,太短的就补空格,太长的就截断(利用pad_sequence 函数,也可以自己写代码pad)
数据增强:分为shuffle和drop两种,前者打乱词顺序,后者随机的删除掉某些词。有助于提升数据的差异性,对基于词word的模型有一定提升,但对于基于字char的模型可能起副作用。
二、文本表示
文本向量化 -> 向量空间模型(vecto rspace model,VSM)
- 文档、项/特征项、项的权重
向量的相似性度量(similarity)
- 相似系数Sim(D1,D2)指两个文档内容的相关程度(degree of relevance)
- 可借助n维空间中两个向量之间的某种距离来表示,常用的方法是使用向量之间的内积。如果考虑向量的归一化,则可使用两个向量夹角的余弦值来表示。
文本特征选择(常用方法)
- 基于文档频率(document frequency, DF)的特征提取法
- 信息增益(information gain, IG)法(依据为分类提供的信息量来衡量重要程度)
- χ2统计量(CHI)法(越高,与该类之间的相关性越大,携带的类别信息越多)
- 互信息(mutual information, MI)方法(越大,特征和类别共现的程度越大)
特征权重计算方法
- 一般方法是利用文本的统计信息,主要是词频,给特征项赋予一定的权重。
- 倒排文档频度(inverse document frequency, IDF)法、TF-IDF法(变种:TFC法和ITC法)、TF-IWF(inverse word frequency)法

文本表示方法:One-hot、Bag of Words(BOW)、N-gram、TF-IDF
BOW的核心是用字典大小的向量表示每个文本,向量的单个值表示对应于其在文本中固有位置的词频;
与BOW相比,N-gram考虑相邻单词的信息,并通过考虑相邻单词来构建字典;
TF-IDF使用单词频率并反转文档频率来对文本建模。
- 词袋特征方法:特征表示通常是极其稀疏的
Naive版本、考虑词频、考虑词的重要性(TF-IDF) - TF-IDF:
TF(t)= 该词语在当前文档出现的次数 / 当前文档中词语的总数
IDF(t)= log_e(文档总数 / (出现该词语的文档总数+1))
# 在实际工作中,可能先有词表,再处理文档语料,该词有可能不存在任何文档中
基于embedding: 通过词向量计算文本的特征(主要针对短文本)
- 取平均、网络特征
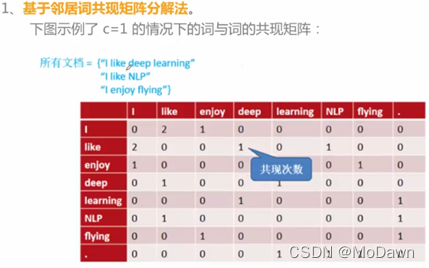
- word2vec:使用本地上下文信息来获取单词向量。
- GloVe:具有局部上下文和全局统计功能;训练单词-单词共现矩阵中的非零元素。
Word2Vec:



其他方法:
- NN Model(end2end实现模型的训练和测试,无需手工提取特征,如CNN、RNN)
- 任务本身(通过对数据的观察和感知,手工提取特征)
- 特征融合(GDBT, XGBoost等非线性模型、LR等线性模型)
- 主题特征(文档话题 LDA、文档潜在语义 LSI)
文档特征表征:

三、机器学习分类器
- XGBoost、LightGBM
- 基于支持向量机(support vector machines, SVM)的分类器
- k-最近邻法(k-nearest neighbor, kNN)
- 线性最小平方拟合(linear least-squares fit, LLSF)
- Rocchio分类方法
- 基于投票的分类方法(Bagging算法、Boosting算法->AdaBoost方法)
- 决策树分类法(decision tree)、随机森林模型(RF)
- 朴素的贝叶斯分类法(naΪve Bayesian classifier)(工业用于识别垃圾邮件)
- 模糊分类法(fuzzy classifier)
- 神经网络法(neural network, NNet)时间开销大且效果不佳
四、深度学习分类模型
与之前的表示方法不同,深度学习也可以用于文本表示,还可以将其映射到一个低纬空间。其中比较典型的例子有:FastText、Word2Vec(GloVe)和Bert
基本思路:文本 -> Embedding -> CNN/RNN/Inception -> Classifier -> 标签个数维向量
词(或者字)经过embedding层之后,利用CNN/RNN等结构,提取局部信息、全局信息或上下文信息,利用分类器进行分类,分类器的是由两层全连接层组成的。
tips:模型分数不够高,试着把模型变得更深更宽更复杂;当模型复杂到一定程度时,不同模型的分数差距很小,继续变复杂难以继续提升分数。
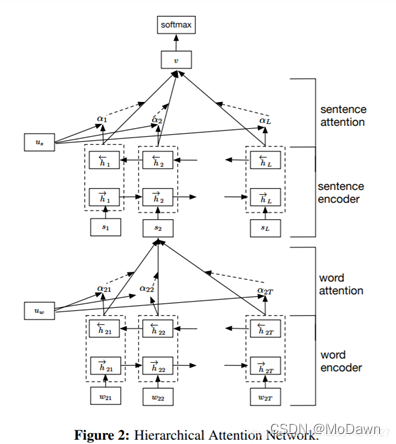
HAN:使用词和句子两层Attention,当数据中看不出句子,只用一层word时,效果不好。
RCNN:同时用到RNN和CNN的思想,训练时间很长,但效果与单独的RNN和CNN差不多。
FastText:通过Average抽象出概括性语义信息
TextCNN:仿照n-gram捕捉局部语义信息
TextRNN:提取序列语义信息
(1) 前馈神经网络FNN
结构简单,但在很多文本分类任务上有较高的准确性,如DAN模型、FastText模型。思路是将文本看作词袋,为每一个词学习一个向量表示(类似word2vec,Glove),然后取所有向量的和或者平均,传递给前向传播层(也叫多层感知机MLP),最后输入分类器进行分类。
fastText: Bag of Tricks for Efficient Text Classification(2016.7)
句子中所有的词向量进行平均(某种意义上可以理解为只有一个avg pooling的特殊CNN),然后直接连接一个 softmax 层进行分类。
doc2vec:使用非监督方法,学习一段文本(句子、段落或篇章)的向量表示。结构跟CBOW模型相似,并增加了一个段落token。用前三个词和结构文档向量预测第四个词,文档向量可以作为文档主题记忆。在训练之后,文档向量可以用作分类。
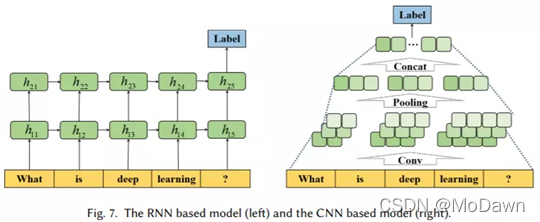
(2) 卷积神经网络CNN
跨空间识别模型
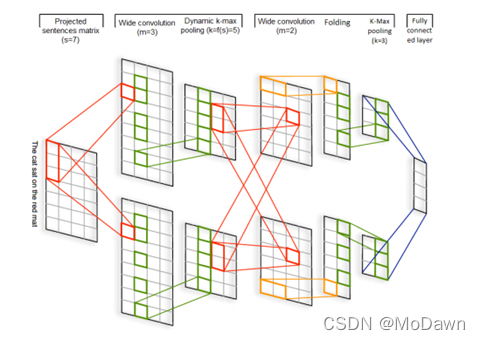
DCNN:最先使用CNN做文本分类的模型之一,动态进行k维最大池化(k根据语句长度与卷积层次进行动态选择);输入是词向量,然后交替使用宽卷积层和动态池化层,该结构可以捕获词语与短语间的长短期关系。
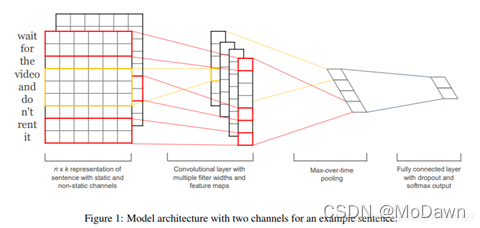
TextCNN:fastText 中的网络结果是完全没有考虑词序信息的,而TextCNN利用CNN,来提取句子中类似 n-gram 的关键信息。
CNN最大的问题是固定 filter_size 的视野,一方面无法建模更长的序列信息,另一方面 filter_size 的超参调节也很繁琐。相比DCNN,TextCNN的结构更简单,只使用一层卷积,然后将整个文本序列的每一个卷积核的结果池化成一个值,拼接所有池化结果进行最终预测。

字符级别的CNN:以固定长度字符为输入,通过6层带池化的卷积层和3层全连接层进行预测。
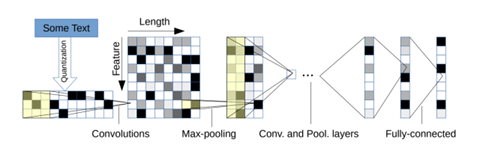
VDCNN:受VGG与ResNets的影响,直接处理字符输入,且只用小卷积跟池化操作,深度增加,效果提升。改进 -> 将模型大小压缩了10到20倍,精度只损失了0.4%-0.3%。
tips:当文本以字符序列作为输入的时候,深层模型比浅层模型表现更好;若用词作为输入,浅且宽的模型(如DenseNet)比深层模型效果更好。而使用非静态的词向量(word2vec、Glove)与最大池化操作可以获得更优的结果。
(3) 循环神经网络RNN
跨时间识别模式;将文本看作词序列,通过获取词之间的依赖以及文本结构信息进行分类。
LSTM:缓解了RNN梯度消失的问题。Tree-LSTM 是LSTM的树型结构扩展,可以学到更丰富的语义表示,在情感分析与句子相似性判断任务上证明了其有效性。
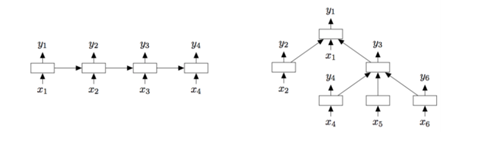
MT-LSTM:用记忆网络替代LSTM中的单个记忆单元,能够给长距离词关系建模,通过获取不同时间尺度上的信息来给长文本建模;将标准LSTM模型中隐藏状态分成多个组,每组会在不同的时间阶段激活并更新。
TopicRNN:结合RNN与主题模型的优点,前者获取局部句法信息,后者获取全局语义信息。
TextRNN:Bi-directional RNN(实际使用的是双向LSTM)从某种意义上可以理解为可以捕获变长且双向的 “n-gram” 信息。分类的时候不是只使用最后一个隐藏元的输出,而是把所有隐藏元的输出做K-MaxPooling再分类。
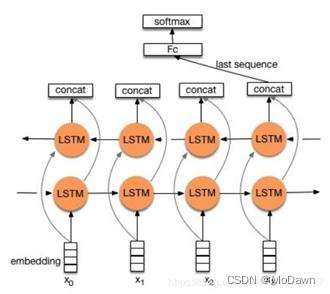
TextRCNN(TextRNN + CNN):利用前向和后向RNN得到每个词的前向和后向上下文的表示;词的表示变成词向量和前向后向上下文向量连接起来的形式;再接跟TextCNN相同卷积层(pooling层即可),唯一不同的是卷积层 filter_size = 1即可,无需更大 filter_size 以获得更大视野,这里词的表示也可以只用双向RNN输出。
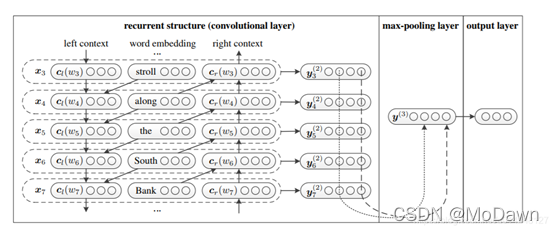
(4) 注意力机制
语言模型中的注意力可看作一组重要性权重的向量。
层次注意力网络 进行文本分类的两个特点:反映了文档的层次结构,在词级别与句子级别分别使用了注意力机制,模型在6个文本分类任务上都取得了较大进步。
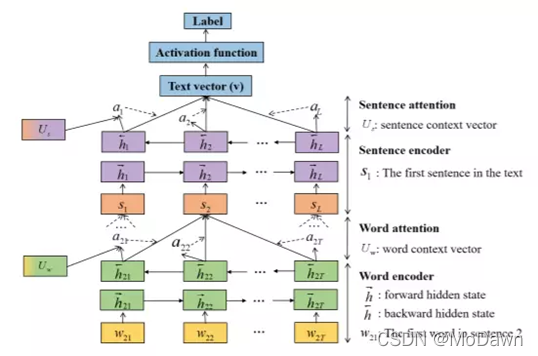
注意力池化(AP)方法:用于配对排序跟匹配任务。可以让池化层知道当前输入对,来自两个输入的信息一定程度上可以直接影响对方的表示结果。它是一种独立于底层表示学习的框架,也可以应用在CNN、RNN等模型上。

还可将文本分类问题看作是标签-文本的匹配问题,通过注意力框架与cosine相似度度量文本序列与标签之间的向量相似度。
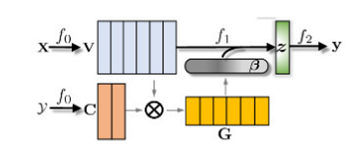
TextRNN + Attention:
注意力(Attention)机制是nlp领域一个常用的建模长时间记忆机制,能够很直观的给出每个词对结果的贡献,基本为Seq2Seq模型的标配。而文本分类可以理解为一种特殊的Seq2Seq,所以考虑引入Attention机制。
加入Attention之后最大的好处:能够直观地解释各个句子和词对分类类别的重要性。
(5) Transformers
不像RNN类模型在处理序列问题时需要很大的计算资源,通过使用self-attention来并行计算序列中每一个词跟其他所有词的关系。基于Transformers的预训练语言模型(PLM),一般具有很深的神经网络结构,并且会在非常大的语料上进行预训练(通过语言模型等任务来学习文本表示)。使用PLM进行微调,在很多下游NLP任务上都取得了SOTA的效果。大体可以分为两类:自回归与自编码模型。
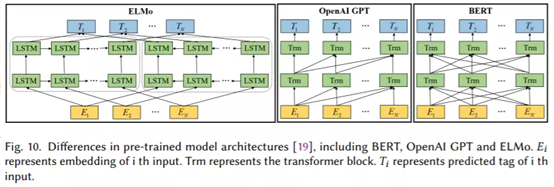
自回归模型有 OpenGPT,从左到右(或从右到左)在文本序列上一个词一个词预测的单向模型;包含12层Transformer,每一个由遮蔽的多头attention与全连接层组成,其中每一层都会加上残差并做层标准化操作。文本分类任务可以作为其下游任务,使用相关的线性分类器并在具体任务数据上微调即可。

自编码预训练模型有 BERT,使用遮蔽语言模型来做训练,随机遮蔽句子中的token,然后用双向的Transformers根据上下文给遮蔽的token进行编码,从而预测被遮蔽的token。改进包括:RoBERTa在更大的训练集上进行训练,使用动态遮蔽方式,并丢弃下一句预测任务,具有更鲁棒的效果;ALBERT降低模型的大小,提高训练速度;DistillBERT在预训练过程使用知识蒸馏方式,使模型大小减少40%,并保留99%的精度,推断速度提高60%;SpanBERT能更好表示与预测文本span。此类模型在QA、文本分类、NLI等NLP任务上都取得了很好的结果。
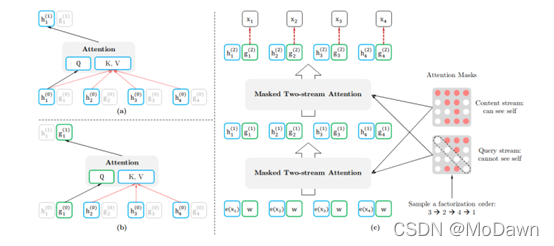
结合自回归模型与自编码模型优点的有 XLNet,在预训练过程中,使用排序操作来同时获取上下文信息。引入了双流self-attention模式来处理排序语言模型,包含两个attention,内容attention(a)即标准的attention结构,查询attention(b)则不能看到当前的token语义信息,只有当前token的位置信息。
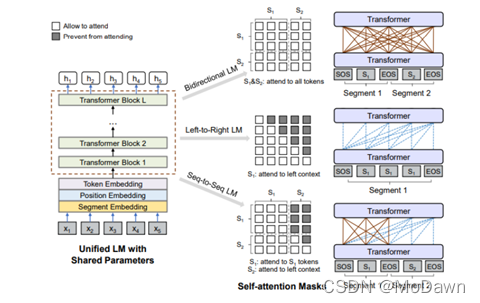
UniLM(Unified language Model):使用3种语言模型任务来进行预训练:单向、双向和seq2seq预测。通过共享Transformers网络来实现,其中以特定的self-attention遮蔽来控制预测条件的上下文。
(6) 胶囊神经网络(CapsNets)
CNN中的池化层会丢失一些信息。
一个胶囊是一组神经元,神经元中的向量表示实体的不同属性,向量的长度表示实体存在的概率,方向表示实体的属性。与池化操作不同,胶囊使用路由的方式,从底层的各个胶囊上路由到上层的父胶囊上,路由可以通过按协议动态路由或者EM等不同算法来实现。
包含一个n-gram卷积层,一个胶囊层,一个卷积胶囊层,一个全连接胶囊层。两种胶囊网络,Capsule-A跟CapsNet比较类似,Capsule-B使用了带有不同窗口大小过滤器的三个并行网络,试图学习更全面的文本表示,实验中B的效果更好。
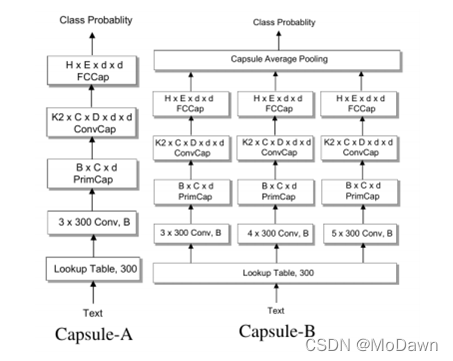
相比较于图像,物体在文本中可以更加随意地组合在一起,比如一些语句的顺序改变,文本的语义还可以保持一致,而人脸图像,五官的位置变换,就不能认为是脸了。由此提出一种静态路由模式,在文本分类任务上,取得了优于动态路由的效果。
(7) 记忆增强网络 NSE(Neural Semantic Encoder)
在编码过程中注意力模型里保存的隐藏向量可认为是模型的内部记忆;记忆增强网络结合了神经网络与外部记忆(模型可以读出与写入),可以用于文本分类与QA任务。
它具有一个大小可变的编码记忆存储器,随着时间进行改变,并通过读入、生成、写入操作来保存对输入序列的理解。
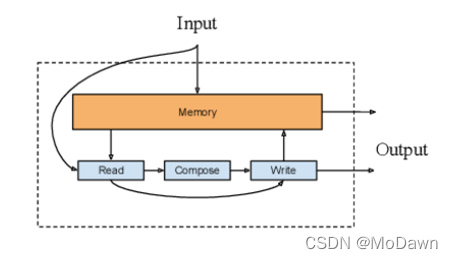
针对QA任务,将一系列的状态(记忆实体)提供给模型,作为对问题的支持事实,模型会学习如何根据问题与历史检索记忆来检索实体;该模型拓展可为端到端的形式,通过注意力机制来实现实体检索。
(8) 图神经网络GNN
虽然文本是以序列的形式展现,但其中也包含了图结构,如句法和语义树。
TextRank:NLP中最早的图模型之一,将文本看作一个图,各种类型的文本单位(如单词、搭配、整个句子)看作节点,节点之间的各种关系(如词法或语义关系、上下文重叠)看作边。
GCN(Graph Convolutional Network)及其变体:有效且高效,是最流行的结构,在很多应用上都取得了SOTA的效果。
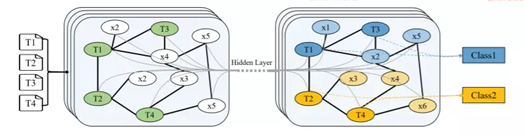
基于graph-CNN模型:首先将文本转换成词图,然后用图卷积操作来处理词图,实验表明,词图的表示能够获取文本中的非连续和长距离语义,并且CNN可以学习到不同层次的语义信息。

GCNN方式:通过词贡献关系与文档-词关系,将整个语料构建成一个单一的图。词与文档为节点,随机初始化节点表示;后用已知标签的文档进行有监督训练,从而学到词跟文档的向量。
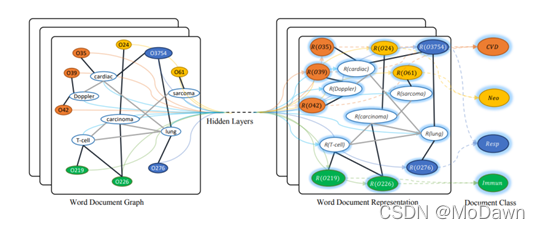
tips:在大量文本上使用GNN代价较大,一般会通过降低模型复杂度或者改变模型训练策略来减少成本。前者有SGC(Simple Graph Convolution),它移除了连续层之间的非线性转换操作;后者对文档层次进行构建图,而不对整个语料构图。
(9) 孪生神经网络S2Net
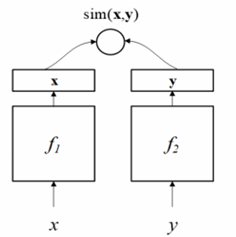
S2Net或者其变体DSSM(Deep Structured Semantic Model)主要针对文本匹配问题。
DSSM(或者S2Net):包含了一对DNN结构(f1、f2),将x、y分别映射到一个低纬语义空间,然后根据cosine距离(或其他方法)计算其相似度。S2Net中假设f1与f2具有一样的结果甚至一样的参数,但在DSSM中这两个可以根据实际情况具有不同的结构。因为文本以序列的形式展现,所以通常会用RNN类的结构来实现f1、f2,后来也有人使用CNN等其他结构,在BERT出现之后,也有不少基于BERT的模型,比如SBERT、TwinBERT等。
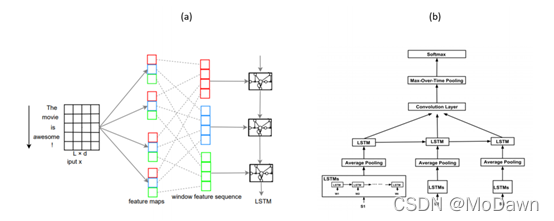
(10) 混合模型(模型融合和多任务)
很多混合模型都会结合LSTM与CNN结构来获取局部特征与全局特征,如C-LSTM与DSCNN。
C-LSTM(Convolutional LSTM):先用CNN提取文本短语(n-gram)表示,然后输入LSTM获取句子表示;
DSCNN(Dependency Sensitive CNN):先用LSTM获取学习句向量,然后输入CNN生成文本表示。
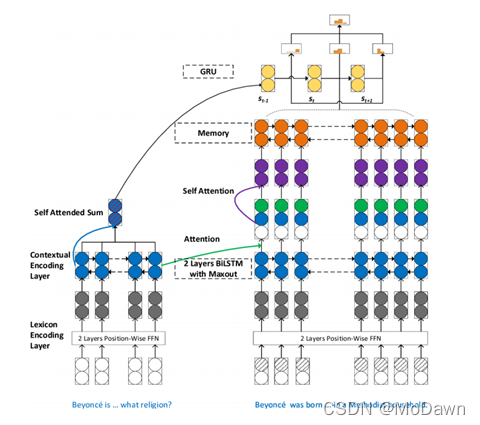
SAN模型(Stochastic Answer Network):针对阅读理解中的多步推理;包含很多结构,如记忆网络、注意力机制、LSTM、CNN。其中Bi-LSTM组件来获取问题与短文的内容表示,再用基于问题感知的注意力机制学习短文表示。
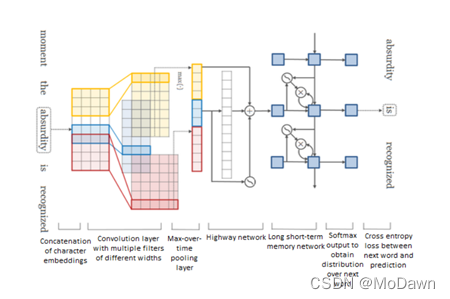
“高速公路”网络:可以解决基于梯度训练的网络随着模型深度的增加变得更加困难的问题;它允许信息在多个层上无阻地流动,有点类似于ResNet;是一种基于字符的语言模型,先用CNN获取词表示,再输入到“高速公路”网络,然后接LSTM模型,最后用softmax来预测每个词的概率。
(11) 非监督学习
- 自编码的无监督学习:跟词向量类似,通过优化一些辅助目标,如自编码器的重构loss,可以用非监督的形式学习句子的表示。
- 对抗训练:是提高分类器泛化能力的一种方法,通过扰动输入数据生成对抗样本,提高模型的鲁棒性。
- 强化学习:是训练代理根据策略执行某些动作的方法,通常用最大化奖励来进行训练。
五、其他
文本分类评测指标:
- 准确度、错误率
- 召回率、正确率、F-测度值、微平均和宏平均
- 平衡点(break-even point)、11点平均正确率(11-point average precision)
- 精确匹配(EM)、平均倒数排序(MRR)
- NAP、ACU等
数据集:
- 情感分析数据集:Yelp、IMDB、SST、MPQA、Amazon、其他
- 新闻分类数据集:AG News、20 Newsgroups、Sougo News、Reuters news、其他
- 主题分类数据集:DBpedia、Ohsumed、EUR-Lex、WOS、PubMed、其他
- 问答数据集:SQuAD、MS MARCO、TREC-QA、WikiQA、Quora、其他
- 自然语言推理数据集:SNLI、Multi-NLI、SICK、MSRP、其他
短文本分类:隐马尔可夫、最小熵MEMM、条件随机场CRF、LSTM循环神经网络
深度学习经验:
- 模型不是最重要的:要理解数据、超参调节 深度学习网络调参技巧 - 知乎专栏
- 关注迭代质量:记录和分析你的每次实验
- 一定要用 dropout:除非数据量特别小,或用了更好的正则方法如bn;默认情况下设置为0.5
- fine-tuning 是必选的:不能只使用word2vec训练的词向量作为特征表示
- 未必一定要 softmax loss:若任务是多个类别间非互斥,可尝试训练多个二分类器
- 类目不均衡问题:可尝试类似 booststrap 方法,调整 loss 中样本权重方式
- 避免训练震荡:增加随机采样因素、默认shuffle机制、调整学习率或 mini_batch_size
模型融合:依靠差异性(改变输入->字/词;人为定义不同的偏差计算方式);加权融合
- 利用预训练好的单模型初始化复杂模型的某一部分参数:
模型过拟合很严重,难以学习到新的东西(单模型在训练集上的分数逼近理论上的极限分数)-> 采用较高的初始学习率从过拟合点拉出来,使得模型在训练集上的分数迅速降低到0.4左右,然后再降低学习率,缓慢学习,提升模型的分数。 - 共享embedding(这种做法更优):
能够一定程度上抑制模型过拟合,减少参数量。虽然CNN/RNN等模型的参数过拟合,但是由于相对应的embedding没有过拟合,所以模型一开始分数就会下降许多,然后再缓慢提升。