原创文章,如需转载请保留出处
本博客为唐宇迪老师python数据分析与机器学习实战课程学习笔记
一. 文本分析与关键词提取
1.1 文本数据
1.2 停用词
- 语料中大量出现
- 没啥大用
- 留着过年吗

1.3 Tf-idf:关键词提取
- 《中国的蜜蜂养殖》:进行词频(Term frequency,缩写TF)统计
- 出现次数最多的词:“的”、“是”、“在”…这类最常用的词(停用词)
- “中国”、“蜜蜂”、“养殖” 这三个词出现的次数一样多,重要性是一样的?
- “中国”是很常见的词,相对而言,“蜜蜂”和“养殖”不那么常见
1.4 逆文档频率(Inverse Document Frequency,IDF)
- 如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词
- 词频(TF) = 某个词在文章中的出现次数 / 该文词的个数
- 逆文档频率(IDF) = log(语料库的文档总数 / 包括该词的文档数 + 1)
1.5 Tf-idf:关键词提取计算
TF-IDF = 词频(TF) * 逆文档频率(IDF)
- 《中国的蜜蜂养殖》:假定该文长度为1000个词,“中国”、“蜜蜂”、“养殖”各出现20次,则这三个词的“词频”(TF)都是0.02
- 搜索Google发现,包含“的”字的网页共有250亿张,假定这就是中文网页总数。包含“中国”的网页共有62.3亿张,包含“蜜蜂”的网页共有0.484亿张,包含“养殖”的网页共有0.973亿张

二. 相似度计算
2.1 相识度
句子A:我喜欢看电视,不喜欢看电影
句子B:我不喜欢看电视,也不喜欢看电影
-
分词
句子A:我 / 喜欢 / 看 / 电视,不 / 喜欢 / 看 / 电影
句子B:我 / 不 / 喜欢 / 看 / 电视,也 / 不 / 喜欢 / 看 / 电影 -
语料库:我 ,喜欢,看,电视,电影,不,也
-
词频:
句子A:我1,喜欢2,看2,电视1, 电影1,不1,也0
句子B:我1,喜欢2,看2,电视1, 电影1,不2,也1、 -
词频向量
句子A:[1,2,2,1,1,1,0]
句子B:[1,2,2,1,1,2,1]
余弦相似度:

三. 新闻数据与任务简介
import pandas as pd
import numpy as np
#结吧分词
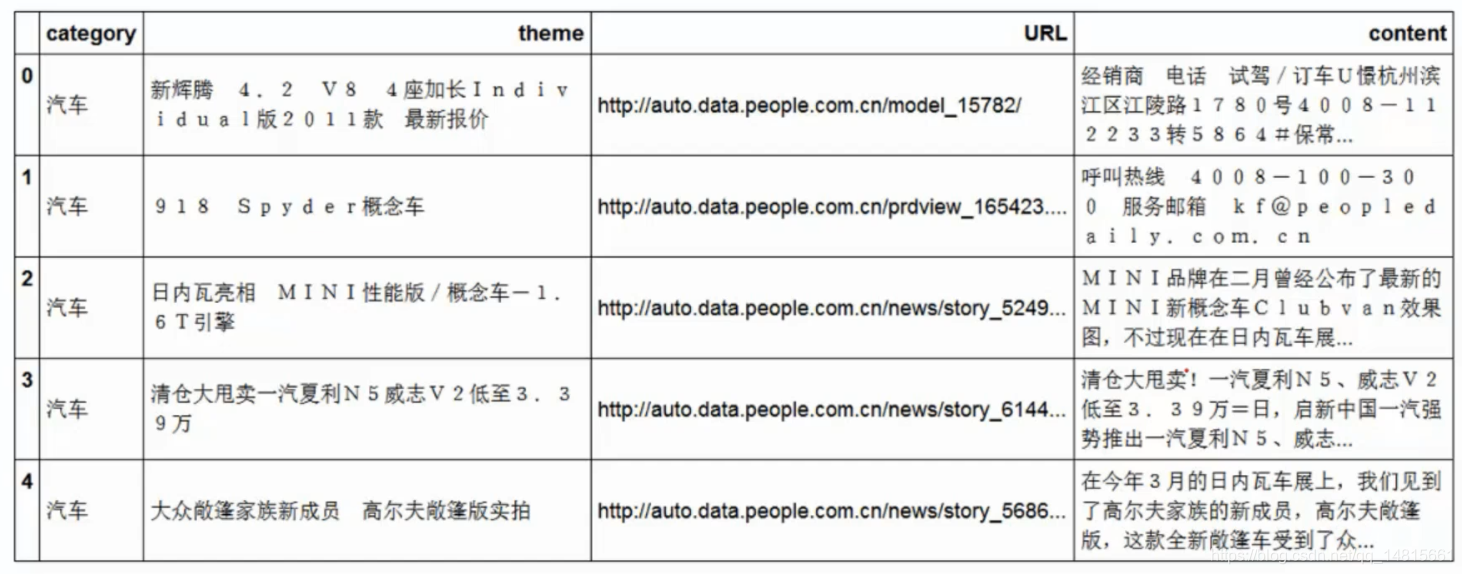
import jiebadf_news = pd.read_table('./data/val.txt',names=['category','theme','URL','content'],encoding='utf-8')
#dropna:去掉缺失值
df_news = df_news.dropna()
df_news.head()

df_news.shape
(5000, 4)
#分词:使用结吧分词器
#先将content转换成list格式
content = df_news.content.values.tolist()
print (content[1000])
阿里巴巴集团昨日宣布,将在集团管理层面设立首席数据官岗位(Chief Data Officer),阿里巴巴B2B公司CEO陆兆禧将会出任上述职务,向集团CEO马云直接汇报。>菹ぃ和6月初的首席风险官职务任命相同,首席数据官亦为阿里巴巴集团在完成与雅虎股权谈判,推进“one company”目标后,在集团决策层面新增的管理岗位。0⒗锛团昨日表示,“变成一家真正意义上的数据公司”已是战略共识。记者刘夏
#利用结吧分词
content_S = []
#line:代表content中每一条
for line in content:current_segment = jieba.lcut(line)#大于1:代表确实能切分if len(current_segment) > 1 and current_segment != '\r\n':content_S.append(current_segment)
content_S[1000]
['阿里巴巴','集团','昨日','宣布',',','将','在','集团','管理','层面','设立','首席','数据','官','岗位','(','C','h','i','e','f','\u3000','D','a','t','a','\u3000','O','f','f','i','c','e','r',')',',','阿里巴巴','B','2','B','公司','C','E','O','陆兆禧','将','会','出任','上述','职务',',','向','集团','C','E','O','马云','直接','汇报','。','>','菹','ぃ','和','6','月初','的','首席','风险','官','职务','任命','相同',',','首席','数据','官亦为','阿里巴巴','集团','在','完成','与','雅虎','股权','谈判',',','推进','“','o','n','e','\u3000','c','o','m','p','a','n','y','”','目标','后',',','在','集团','决策','层面','新增','的','管理','岗位','。','0','⒗','锛','团','昨日','表示',',','“','变成','一家','真正','意义','上','的','数据','公司','”','已','是','战略','共识','。','记者','刘夏']
df_content = pd.DataFrame({'content_S':content_S})
df_content.head()
content_S
0 [经销商, , 电话, , 试驾, /, 订车, U, 憬, 杭州, 滨江区, 江陵, …
1 [呼叫, 热线, , 4, 0, 0, 8, -, 1, 0, 0, -, 3, 0, 0…
2 [M, I, N, I, 品牌, 在, 二月, 曾经, 公布, 了, 最新, 的, M, I…
3 [清仓, 大, 甩卖, !, 一汽, 夏利, N, 5, 、, 威志, V, 2, 低至, …
4 [在, 今年, 3, 月, 的, 日内瓦, 车展, 上, ,, 我们, 见到, 了, 高尔夫…
四.TF-IDF关键词提取
stopwords = pd.read_csv('stopwords.txt',index_col = False, sep = '\t',quoting = 3,names = ['stopword'], encoding = 'utf-8')
stopwords.head()
stopword
0 !
1 "
2 #
3 $
4 %
def drop_stopwords(contents,stopwords):contents_clean = []all_words = []for line in contents:line_clean = []for word in line:if word in stopwords:continueline_clean.append(word)all_words.append(str(word))contents_clean.append(line_clean)return contents_clean,all_wordscontents = df_content.content_S.values.tolist()
stopwords = stopwords.stopword.values.tolist()
contents_clean,all_words = drop_stopwords(contents,stopwords)
df_content = pd.DataFrame({'contents_clean':contents_clean})
df_content.head()
contents_clean
0 [经销商, 电话, 试驾, 订车, U, 憬, 杭州, 滨江区, 江陵, 路, 号, 转, …
1 [呼叫, 热线, 服务, 邮箱, k, f, p, e, o, p, l, e, d, a,…
2 [M, I, N, I, 品牌, 二月, 公布, 最新, M, I, N, I, 新, 概念…
3 [清仓, 甩卖, 一汽, 夏利, N, 威志, V, 低至, 万, 启新, 中国, 一汽, …
4 [日内瓦, 车展, 见到, 高尔夫, 家族, 新, 成员, 高尔夫, 敞篷版, 款, 全新,…
df_all_words=pd.DataFrame({'all_words':all_words})
df_all_words.head()
all_words
0 经销商
1 电话
2 试驾
3 订车
4 U
words_count = df_all_words.groupby(by=['all_words'])['all_words'].agg({'count':np.size})
words_count = words_count.reset_index().sort_values(by=['count'],ascending=False)
words_count.head()
all_words count
4077 中 5199
4209 中国 3115
88255 说 3055
104747 S 2646
1373 万 2390
from wordcloud import WordCloud
import matplotlib.pyplot as plt
%matplotlib inline
import matplotlib
matplotlib.rcParams['figure.figsize'] = (10.0, 5.0)wordcloud = WordCloud(font_path='./data/simhei.ttf',background_color='white',max_font_size=80)
word_frequence = {x[0]:x[1] for x in words_count.head(100).values}
wordcloud = wordcloud.fit_words(word_frequence)
plt.imshow(wordcloud)

#提取关键字
import jieba.analyse
index = 1000
print(df_news['content'][index])
content_S_str = ''.join(content_S[index])
print(" ".join(jieba.analyse.extract_tags(content_S_str, topK=5, withWeight=False)))
阿里巴巴集团昨日宣布,将在集团管理层面设立首席数据官岗位(Chief Data Officer),阿里巴巴B2B公司CEO陆兆禧将会出任上述职务,向集团CEO马云直接汇报。>菹ぃ和6月初的首席风险官职务任命相同,首席数据官亦为阿里巴巴集团在完成与雅虎股权谈判,推进“one company”目标后,在集团决策层面新增的管理岗位。0⒗锛团昨日表示,“变成一家真正意义上的数据公司”已是战略共识。记者刘夏
阿里巴巴 集团 首席 岗位 数据
五.LDA建模
Gensim是一个用于从文档中自动提取语义主题的Python库
from gensim import corpora, models, similarities
import gensim
#做映射,相当于词袋
dictionary = corpora.Dictionary(contents_clean)
corpus = [dictionary.doc2bow(sentence) for sentence in contents_clean]
lda = gensim.models.ldamodel.LdaModel(corpus=corpus, id2word=dictionary, num_topics=20)
#一号分类结果
print(lda.print_topic(1, topn=5))
0.011*“男人” + 0.010*“中” + 0.005*“说” + 0.004*“女人” + 0.003*“於”
for topic in lda.print_topics(num_topics=20, num_words=5):print(topic[1])
0.005*“纹身” + 0.004*“中” + 0.004*“台湾” + 0.004*“台北” + 0.003*“女儿”
0.011*“男人” + 0.010*“中” + 0.005*“说” + 0.004*“女人” + 0.003*“於”
0.009*“教育” + 0.007*“学生” + 0.006*“学校” + 0.006*“工作” + 0.006*“发展”
0.009*“比赛” + 0.007*“该剧” + 0.005*“中” + 0.005*“女人” + 0.005*“节目”
0.005*“赛区” + 0.005*“说” + 0.004*“中” + 0.004*“老公” + 0.004*“工作”
0.005*“中” + 0.005*“说” + 0.004*“万” + 0.003*“D” + 0.003*“比赛”
0.007*“中” + 0.006*“吃” + 0.006*“食物” + 0.005*“含有” + 0.004*“维生素”
0.009*“节目” + 0.007*“中” + 0.005*“S” + 0.005*“V” + 0.005*“表演”
0.008*“中” + 0.005*“比赛” + 0.005*“球队” + 0.004*“说” + 0.004*“中国”
0.012*“中” + 0.006*“卫视” + 0.004*“说” + 0.003*“中国” + 0.003*“T”
0.026*“a” + 0.026*“e” + 0.020*“i” + 0.019*“o” + 0.018*“n”
0.015*“中国” + 0.005*“发展” + 0.005*“中” + 0.005*“美国” + 0.004*“文化”
0.007*“中国” + 0.007*“中” + 0.007*“观众” + 0.006*“说” + 0.004*“比赛”
0.004*“节目” + 0.003*“芒果” + 0.003*“单身” + 0.003*“男人” + 0.003*“万”
0.009*“说” + 0.005*“恋情” + 0.005*“分手” + 0.005*“中” + 0.004*“离婚”
0.009*“撒” + 0.005*“高考” + 0.004*“乳房” + 0.004*“孩子” + 0.003*“万”
0.007*“号” + 0.006*“万” + 0.004*“转” + 0.003*“学校” + 0.003*“公司”
0.010*“孩子” + 0.007*“说” + 0.004*“儿子” + 0.004*“中” + 0.003*“M”
0.017*“电影” + 0.012*“导演” + 0.008*“影片” + 0.007*“中” + 0.007*“观众”
0.006*“女人” + 0.006*“女性” + 0.003*“中” + 0.003*“快感” + 0.002*“W”
五.基于贝叶斯算法进行新闻分类
df_train = pd.DataFrame({'contents_clean':contents_clean,'label':df_news['category']})
df_train.tail()
contents_clean label
4995 [天气, 炎热, 补水, 变得, 美国, 跑步, 世界, 杂志, 报道, 喝水, 身体, 补… 时尚
4996 [不想, 说, 话, 刺激, 说, 做, 只能, 走, 离开, 伤心地, 想起, 一句, 话… 时尚
4997 [岁, 刘晓庆, 最新, 嫩照, O, 衷, 诘, 牧跸, 庆, 看不出, 岁, 秒杀, 刘… 时尚
4998 [导语, 做, 爸爸, 一种, 幸福, 无论是, 领养, 亲生, 更何况, 影视剧, 中, … 时尚
4999 [全球, 最美, 女人, 合成图, 国, 整形外科, 教授, 李承哲, 国际, 学术, 杂志… 时尚
df_train.label.unique()
array([‘汽车’, ‘财经’, ‘科技’, ‘健康’, ‘体育’, ‘教育’, ‘文化’, ‘军事’, ‘娱乐’, ‘时尚’],
dtype=object)
label_mapping = {"汽车":1,"财经":2,"科技":3,"健康":4,"体育":5,"教育":6,"文化":7,"军事":8,"娱乐":9,"时尚":0}
df_train['label'] = df_train['label'].map(label_mapping)
df_train.head()
contents_clean label
0 [经销商, 电话, 试驾, 订车, U, 憬, 杭州, 滨江区, 江陵, 路, 号, 转, … 1
1 [呼叫, 热线, 服务, 邮箱, k, f, p, e, o, p, l, e, d, a,… 1
2 [M, I, N, I, 品牌, 二月, 公布, 最新, M, I, N, I, 新, 概念… 1
3 [清仓, 甩卖, 一汽, 夏利, N, 威志, V, 低至, 万, 启新, 中国, 一汽, … 1
4 [日内瓦, 车展, 见到, 高尔夫, 家族, 新, 成员, 高尔夫, 敞篷版, 款, 全新,…
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(df_train['contents_clean'].values, df_train['label'].values, random_state=1)
x_train[0][1]
‘上海’
words = []
for line_index in range(len(x_train)):try:words.append(' '.join(x_train[line_index]))except:print (line_index,word_index)
words[0]
‘中新网 上海 日电 于俊 父亲节 网络 吃 一顿 电影 快餐 微 电影 爸 对不起 我爱你 定于 本月 父亲节 当天 各大 视频 网站 首映 葜 谱 鞣 剑 保慈 障蚣 钦 呓 樯 埽 ⒌ 缬 埃 ǎ 停 椋 悖 颍 铩 妫 椋 恚 称 微型 电影 新 媒体 平台 播放 状态 短时 休闲 状态 观看 完整 策划 系统 制作 体系 支持 显示 较完整 故事情节 电影 微 超短 放映 微 周期 制作 天 数周 微 规模 投资 人民币 几千 数万元 每部 内容 融合 幽默 搞怪 时尚 潮流 人文 言情 公益 教育 商业 定制 主题 单独 成篇 系列 成剧 唇 开播 微 电影 爸 对不起 我爱你 讲述 一对 父子 观念 缺少 沟通 导致 关系 父亲 传统 固执 钟情 传统 生活 方式 儿子 新派 音乐 达 习惯 晚出 早 生活 性格 张扬 叛逆 两种 截然不同 生活 方式 理念 差异 一场 父子 间 拉开序幕 子 失手 打破 父亲 心爱 物品 父亲 赶出 家门 剧情 演绎 父亲节 妹妹 哥哥 化解 父亲 这场 矛盾 映逋坏 嚼 斫 狻 ⒍ 粤 ⒌ 桨容 争执 退让 传统 尴尬 父子 尴尬 情 男人 表达 心中 那份 感恩 一杯 滤挂 咖啡 父亲节 变得 温馨 镁 缬 缮 虾 N 逄 煳 幕 传播 迪欧 咖啡 联合 出品 出品人 希望 观摩 扪心自问 父亲节 父亲 记得 父亲 生日 哪一天 父亲 爱喝 跨出 家门 那一刻 感觉 一颗 颤动 心 操劳 天下 儿女 父亲节 大声 喊出 父亲 家人 爱 完’
print (len(words))
3750
from sklearn.feature_extraction.text import CountVectorizer
texts = ["dog cat fish","dog cat cat","fish bird","bird"]
cv = CountVectorizer()
cv_fit = cv.fit_transform(texts)print(cv.get_feature_names())
print(cv_fit.toarray())
print(cv_fit.toarray().sum(axis=0))
[‘bird’, ‘cat’, ‘dog’, ‘fish’]
[[0 1 1 1]
[0 2 1 0]
[1 0 0 1]
[1 0 0 0]]
[2 3 2 2]
from sklearn.feature_extraction.text import CountVectorizer
texts = ["dog cat fish","dog cat cat","fish bird","bird"]
cv = CountVectorizer(ngram_range=(1,4))
cv_fit = cv.fit_transform(texts)print(cv.get_feature_names())
print(cv_fit.toarray())
print(cv_fit.toarray().sum(axis=0))
[‘bird’, ‘cat’, ‘cat cat’, ‘cat fish’, ‘dog’, ‘dog cat’, ‘dog cat cat’, ‘dog cat fish’, ‘fish’, ‘fish bird’]
[[0 1 0 1 1 1 0 1 1 0]
[0 2 1 0 1 1 1 0 0 0]
[1 0 0 0 0 0 0 0 1 1]
[1 0 0 0 0 0 0 0 0 0]]
[2 3 1 1 2 2 1 1 2 1]
from sklearn.feature_extraction.text import CountVectorizer
vec = CountVectorizer(analyzer='word', max_features=4000,lowercase=False)
vec.fit(words)
CountVectorizer(analyzer=‘word’, binary=False, decode_error=‘strict’,
dtype=<class ‘numpy.int64’>, encoding=‘utf-8’, input=‘content’,
lowercase=False, max_df=1.0, max_features=4000, min_df=1,
ngram_range=(1, 1), preprocessor=None, stop_words=None,
strip_accents=None, token_pattern=’(?u)\b\w\w+\b’,
tokenizer=None, vocabulary=None)
from sklearn.naive_bayes import MultinomialNB
classifier = MultinomialNB()
classifier.fit(vec.transform(words),y_train)
MultinomialNB(alpha=1.0, class_prior=None, fit_prior=True)
test_words = []
for line_index in range(len(x_test)):try:test_words.append(' '.join(x_test[line_index]))except:print (line_index,word_index)
test_words[0]
‘国家 公务员 考试 申论 应用文 类 试题 实质 一道 集 概括 分析 提出 解决问题 一体 综合性 试题 说 一道 客观 凝练 申发 论述 文章 题目 分析 历年 国考 申论 真题 公文 类 试题 类型 多样 包括 公文 类 事务性 文书 类 题材 从题 干 作答 材料 内容 整合 分析 无需 太 创造性 发挥 纵观 历年 申论 真题 作答 应用文 类 试题 文种 格式 作出 特别 重在 内容 考查 行文 格式 考生 平常心 面对 应用文 类 试题 准确 把握 作答 领会 内在 含义 把握 题材 主旨 材料 结构 轻松 应对 应用文 类 试题 R 弧 ⒆ 钒 盐 展文 写作 原则 T 材料 中来 应用文 类 试题 材料 总体 把握 客观 考生 材料 中来 材料 中 把握 材料 准确 理解 题材 主旨 T 政府 角度 作答 应用文 类 试题 更应 注重 政府 角度 观点 政府 角度 出发 原则 表述 观点 提出 解决 之策 考生 作答 站 政府 人员 角度 看待 提出 解决问题 T 文体 结构 形式 考查 重点 文体 结构 大部分 评分 关键点 解答 方法 薄 ⒆ ス 丶 词 明 方向 作答 题目 题干 作答 作答 方向 作答 角度 关键 向导 考生 仔细阅读 题干 作答 抓住 关键词 作答 方向 相关 要点 整理 作答 思路 年国考 地市级 真 题为 例 潦惺姓 府 宣传 推进 近海 水域 污染 整治 工作 请 给定 资料 市政府 工作人员 身份 草拟 一份 宣传 纲要 R 求 保对 宣传 内容 要点 提纲挈领 陈述 玻 体现 政府 精神 全市 各界 关心 支持 污染 整治 工作 通俗易懂 超过 字 肮 丶 词 近海 水域 污染 整治 工作 市政府 工作人员 身份 宣传 纲要 提纲挈领 陈述 体现 政府 精神 全市 各界 关心 支持 污染 整治 工作 通俗易懂 提示 归结 作答 要点 包括 污染 情况 原因 解决 对策 作答 思路 情况 原因 对策 意义 逻辑 顺序 安排 文章 结构 病 ⒋ 缶殖 龇 ⅲ 明 结构 解答 应用文 类 试题 考生 材料 整体 出发 大局 出发 高屋建瓴 把握 材料 主题 思想 事件 起因 解决 对策 阅读文章 构建 文章 结构 直至 快速 解答 场 ⒗ 硭 乘悸 罚明 逻辑 应用文 类 试题 严密 逻辑思维 情况 原因 对策 意义 考生 作答 先 弄清楚 解答 思路 统筹安排 脉络 清晰 逻辑 表达 内容 表述 础 把握 明 详略 考生 仔细阅读 分析 揣摩 应用文 类 试题 内容 答题 时要 详略 得当 主次 分明 安排 内容 增加 文章 层次感 阅卷 老师 阅卷 时能 明白 清晰 一目了然 玻埃 保蹦旯 考 考试 申论 试卷 分为 省级 地市级 两套 试卷 能力 大有 省级 申论 试题 考生 宏观 角度看 注重 深度 广度 考生 深谋远虑 地市级 试题 考生 微观 视角 观察 侧重 考查 解决 能力 考生 贯彻执行 作答 区别对待’
classifier.score(vec.transform(test_words),y_test)
0.804
from sklearn.feature_extraction.text import TfidfVectorizervectorizer = TfidfVectorizer(analyzer='word',max_features=4000,lowercase=False)
vectorizer.fit(words)
TfidfVectorizer(analyzer=‘word’, binary=False, decode_error=‘strict’,
dtype=<class ‘numpy.float64’>, encoding=‘utf-8’,
input=‘content’, lowercase=False, max_df=1.0, max_features=4000,
min_df=1, ngram_range=(1, 1), norm=‘l2’, preprocessor=None,
smooth_idf=True, stop_words=None, strip_accents=None,
sublinear_tf=False, token_pattern=’(?u)\b\w\w+\b’,
tokenizer=None, use_idf=True, vocabulary=None)
from sklearn.naive_bayes import MultinomialNB
classifier = MultinomialNB()
classifier.fit(vectorizer.transform(words),y_train)
MultinomialNB(alpha=1.0, class_prior=None, fit_prior=True)
classifier.score(vectorizer.transform(test_words),y_test)
0.8152