一、什么是簇?
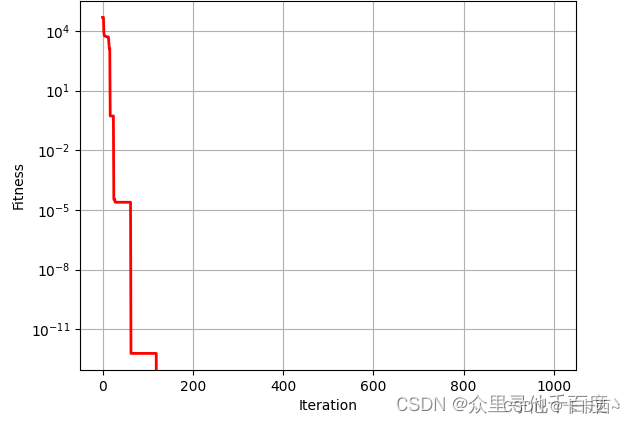
我们知道聚类就是让机器把数据集中的样本按照特征的性质分组,直观上来看,簇是一组一组聚集在一起的数据,在 一个簇 中的数据就认为是 同一类 ,簇就是聚类的结果表现。实际上簇并没有明确的定义,并且簇的划分没有客观标准,我们可以利用下图来理解什么是簇。该图显示了20个点和将它们划分成簇的3种不同方法,标记的形状(口、△、☆等)表示簇的隶属关系。
图中分别将数据划分成两个簇、四个簇和六个簇。直观地看,将图b的2个较大的簇再划分成4个簇好像也不无道理,这可能是人的视觉系统造成的假象。
该图表明簇的定义是不精确的,而最好的定义依赖于数据的特性和期望的结果。
二、什么是质心?
簇中所有 数据的均值 通常被称为这个 簇的“质心”( centroids) 。在一个二维平面中,一簇数据点的质心的横坐标就是这一簇数据点的横坐标的均值,质心的纵坐标就是这一簇数据点的纵坐标的均值。同理可推广至高维空间。
一、KMeans算法原理
KMeans算法作为聚类算法的典型代表,那它是怎么完成聚类的呢?
在 KMeans 算法中, 簇的个数用k表示,k是一个超参数,需要我们人为输入来确定。 Kmeans 的核心任务就是根据我们设定好的 k ,找出 k个最优的质心,并将离这些质心最近的数据分别分配到这些质心代表的簇中去。
二、KMeans算法流程
(1)首先设置参数k, k的含义为将数据聚合成几类(这里取k=3);
(2)从数据当中,随机的选择三(k)个点,成为聚类初始中心点;(图中初始三个中心点用蓝色、红色和黄色标记)

(3)计算所有其他点到这三(k)个点的距离, 然后找出离每个数据点最近的中心点, 将该点划分到这个中心点所代表的的簇当中去。那么所有点都会被划分到三(k)个簇当中去。
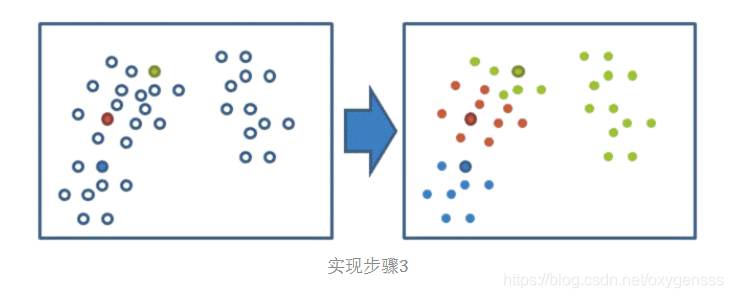
(4)重新计算三个簇的质心,作为下一次聚类的中心点;
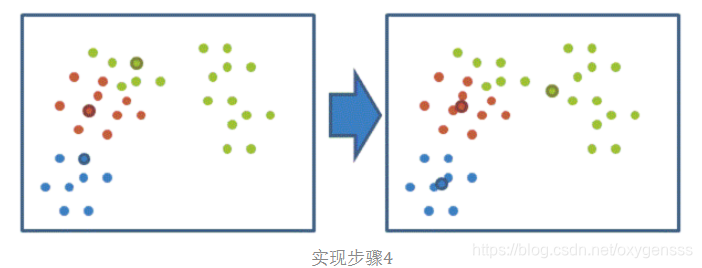
(5)重复上面的3-4步的过程,重新进行聚类,不断迭代重复这个过程。
(6)停止条件:
第一种:当重新聚类后,所有样本点归属类别都没有发生变化的时候。
第二种:当迭代次数达到规定的最大次数时,也会停止。
在什么情况下,质心的位置会不再变化呢?
引言: 在上节介绍KMeans算法流程中,我们简单介绍了聚类停止的条件,其中簇不再发生变化的条件,本质上是指簇的质心位置不再发生改变。为什么呢?
因为:在我们找质心的过程中,当每次迭代中被分配到这个质心上的样本都是一致时,也就是说:每次新生成的簇都是一致的,所有的样本点都不会再从一个簇转移到另一个簇,质心就不会变化了。
接下来,我们以可视化的形式详细讨论质心的位置的变化情况。
质心位置变化的可视化展示过程
上面论述的过程,我们可以由下图来显示:我们规定,将数据分为 4 簇(k=4),其中白色 X 代表质心的位置,每个颜色块代表着围绕着质心所形成的簇。

注:灰色箭头表示质心的变化情况
在数据集下多次迭代(iteration),就会有:

第六次迭代之后,基本上质心的位置就不再改变了,生成的簇也变得稳定。此时我们的聚类就完成了。