1 前言
在计算机视觉领域,卷积神经网络(CNN)已经成为最主流的方法,比如最近的GoogLenet,VGG-19,Incepetion等模型。CNN史上的一个里程碑事件是ResNet模型的出现,ResNet可以训练出更深的CNN模型,从而实现更高的准确度。ResNet模型的核心是通过建立前面层与后面层之间的“短路连接”(shortcuts,skip connection),这有助于训练过程中梯度的反向传播,从而能训练出更深的CNN网络。今天我们要介绍的是DenseNet模型,它的基本思路与ResNet一致,但是它建立的是前面所有层与后面层的密集连接(dense connection),它的名称也是由此而来。DenseNet的另一大特色是通过特征在channel上的连接来实现特征重用(feature reuse)。这些特点让DenseNet在参数和计算成本更少的情形下实现比ResNet更优的性能,DenseNet也因此斩获CVPR 2017的最佳论文奖。
简单总结DenseNet的几个优点:
1、减轻了vanishing-gradient(梯度消失)
2、加强了feature的传递
3、更有效地利用了feature
4、一定程度上较少了参数数量
2 网络结构
DenseNet的网络结构主要由DenseBlock和Transition组成,一个DenseNet中有3个或4个DenseBlock。
其中DenseBlock是包含很多层的模块,每个层的特征图大小相同,层与层之间采用密集连接方式。而Transition模块是连接两个相邻的DenseBlock,并且使特征图大小降低(通过其内部的Pooling使特征图大小降低)。下面给出了DenseNet的其中一种网路结构,它共包含4个DenseBlock,各个DenseBlock之间通过Transition连接在一起。
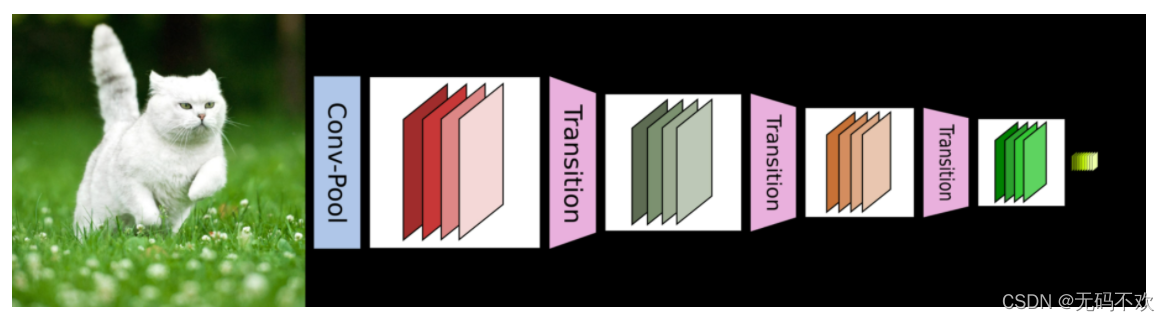
对于Transition层,它主要是连接两个相邻的DenseBlock,并且降低特征图大小。Transition层包括一个1x1的卷积和2x2的AvgPooling,
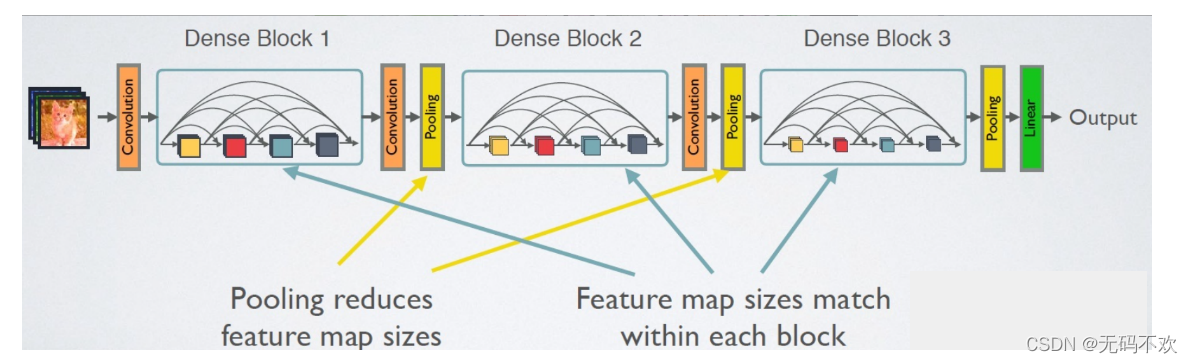
在下图给出了DenseNet的的另一种网路结构图,它中包含了3个dense block。作者将DenseNet分成多个dense block,原因是希望各个dense block内的feature map的size统一,这样在做concatenation就不会有size的问题。
3 DenseBlock
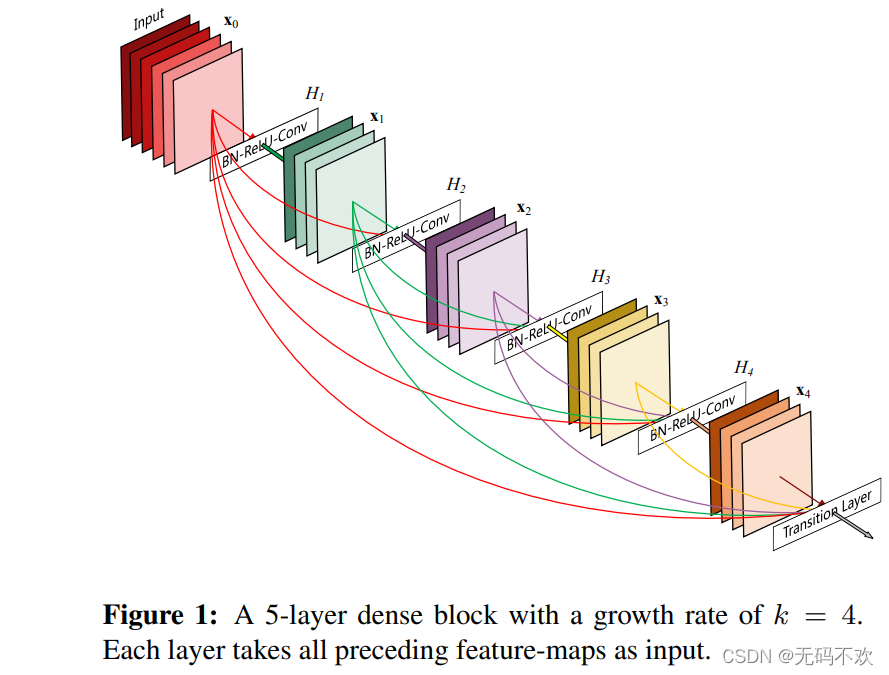
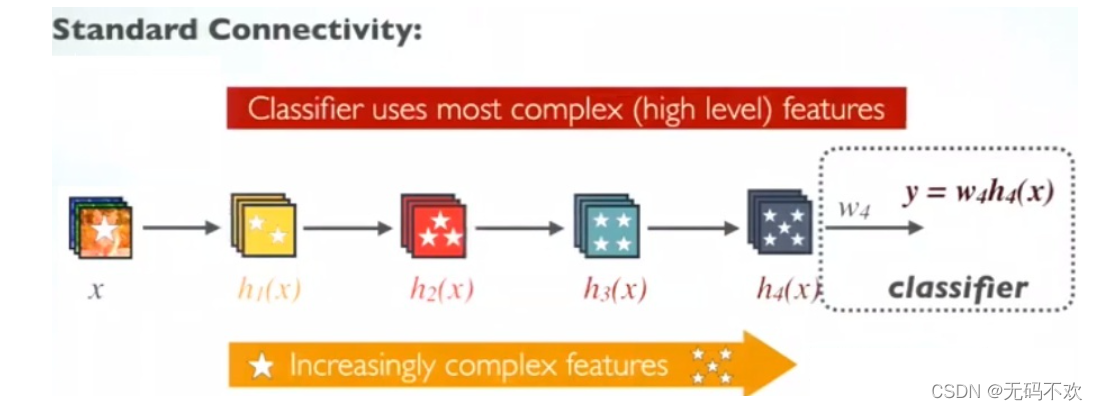
在传统的卷积神经网络中,如果你有L层,那么就会有L个连接,但是在DenseNet的DenseBlock 中,提出了一个更激进的密集连接机制:即互相连接所有的层,具体来说就是每一层的输入都来自于它前面所有层的特征图,每一层的输出均会直接连接到它后面所有层的输入。下面是 DenseBlock 的示意图,该图中共有5个网络层,即 H 1 H_1 H1 , H 2 H_2 H2 , H 3 H_3 H3 , H 4 H_4 H4 以及最后的 Transtion Layer层 ,所以它一共有1+2+3+4+5=15个连接。如果对于一个L层的DenseBlock,共包含 L*(L+1)/2 个连接
下面我们将标准的卷积网络,ResNet中残差模块的连接机制和DenseBlock的密集连接机制作一共对比:
下面是标准的卷积网络图, 它的输入和输出的公式是
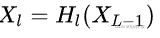
其中是 H 1 H_1 H1一个组合函数,通常包括BN,ReLU,Pooling,Conv操作.

下图是ResNet网络的连接机制,可以看到ResNet是每个层与前面的某层(一般是2~3层)短路连接在一起,连接方式是通过元素级相加。因为ResNet增加了来自上一层输入的identity函数,所以它的输入和输出的公式是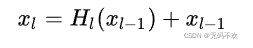
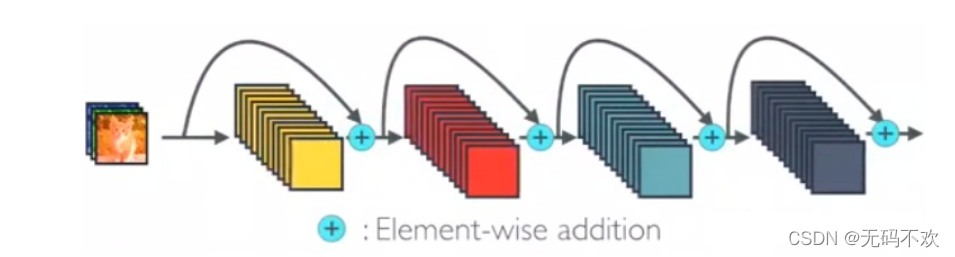
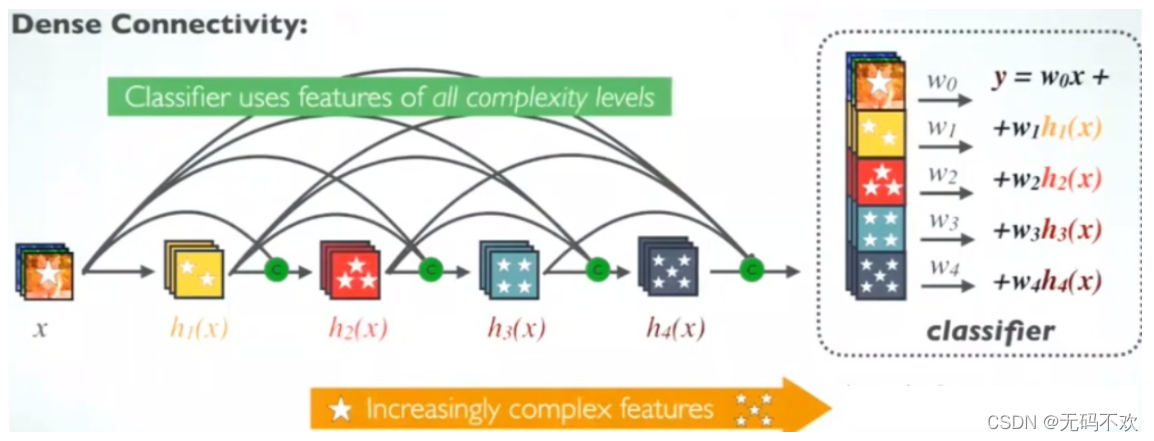
下图是DenseNet的密集连接机制。可以看到每个层都会与前面所有层在channel维度上连接(concat)在一起(这里各个层的特征图大小是相同的),并作为下一层的输入。对于一个L层的DenseBlock,共包含 L*(L+1)/2 个连接,相比ResNet,这是一种密集连接。而且DenseNet是直接concat来自不同层的特征图,这可以实现特征重用,提升效率,这一特点是DenseNet与ResNet最主要的区别。
在DenseNet中,输入输出公式是:
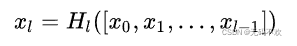
其中,上面的 H l ( . ) H_l(.) Hl(.)代表是非线性转化函数(non-liear transformation),它是一个组合操作,其可能包括一系列的BN(Batch Normalization),ReLU,Pooling及Conv操作。注意这里 L L L层和 L − 1 L-1 L−1层之间可能实际上包含多个卷积层。
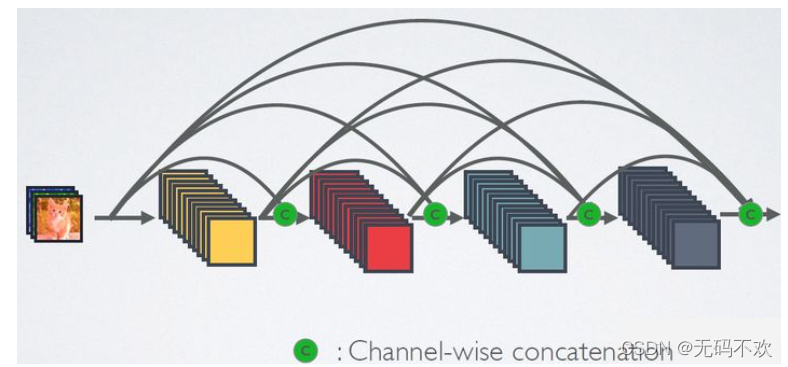
DenseBlock的特征复用过程可以用下图来表示,可以更直观地理解其密集连接方式,其中原始特征 x 0 x_0 x0输入到 h 1 h_1 h1层后输出了特征 x 1 x_1 x1, h 2 h_2 h2层 的输入不仅包括来自 h 1 h_1 h1层的输出特征 x 1 x_1 x1,还包括原始特征 x 0 x_0 x0 ,而 h 3 h_3 h3层 的输入不仅包括来自 h 2 h_2 h2层的输出特征 x 2 x_2 x2,还包括前面 h 1 h_1 h1层的输出特征 x 1 x_1 x1以及原始特征 x 0 x_0 x0

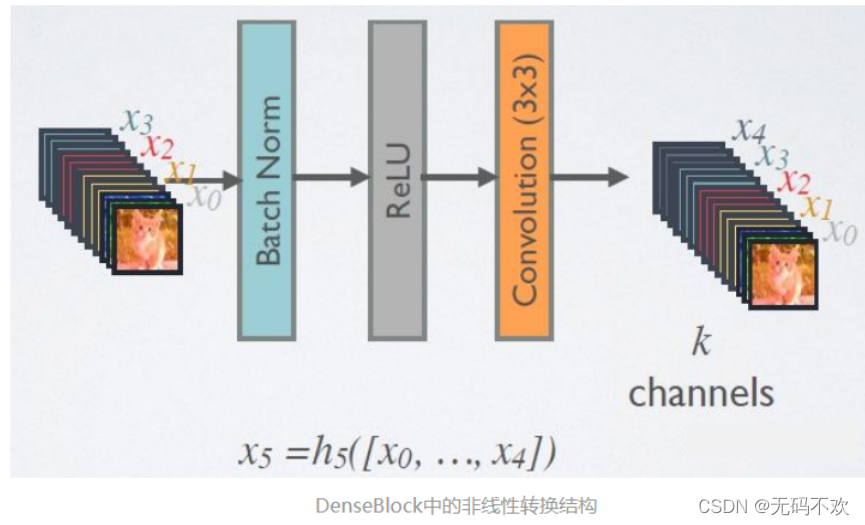
在DenseBlock中,各个层的特征图大小一致,可以在channel维度上连接。DenseBlock中的非线性组合函数 H l ( . ) H_l(.) Hl(.)采用的是BN+ReLU+3x3 Conv的结构,如下图所示。另外值得注意的一点是,与ResNet不同,所有DenseBlock中各个层卷积之后均输出k个特征图,即得到的特征图的channel数为 k,或者说采用 k个卷积核。k在DenseNet称为growth rate(增长率),这是一个超参数。一般情况下使用较小的k(比如12),就可以得到较佳的性能。假定输入层的特征图的channel数为 k 0 k_0 k0,那么 l l l层输入的channel数为 k 0 k_0 k0+k( l l l-1),因此随着层数增加,尽管k设定得较小,但是由于特征重用的原因,DenseBlock中每一层输入仍然会越来越多。
注意:
这里一般情况下,如果某卷积层中同时包含BN,激活函数和卷积。那么它们的位置顺序一般都是: 卷积—>BN—>激活函数,但是在这里,由于卷积层的输入包含了它前面所有层的输出特征,比如x0 ,x1, x2, x3 ,而这些特征由于是来自不同层的输出,所以它们的数值分布差异比较大,因此它们在输入下一个卷积层时,必须先经过BN层将其数值进行标准化,然后才可以进行卷积操作,所以此时对应的卷积层结构顺序应该是:BN—>激活函数—>卷积
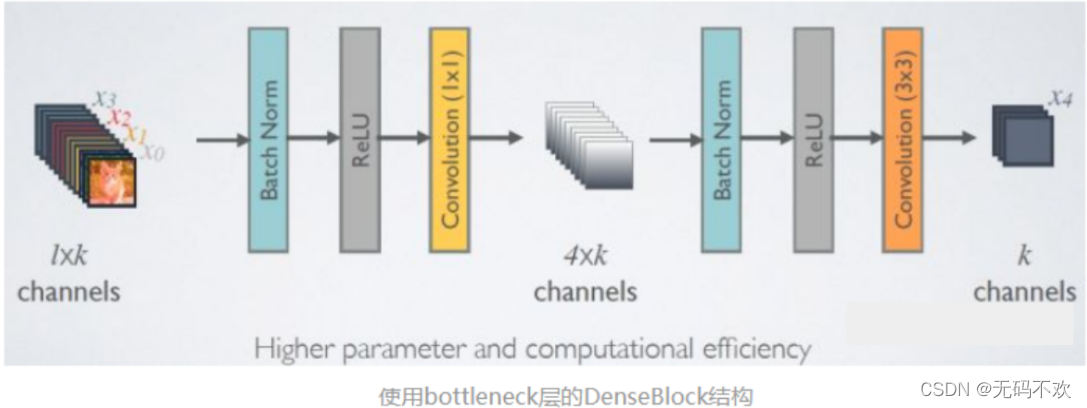
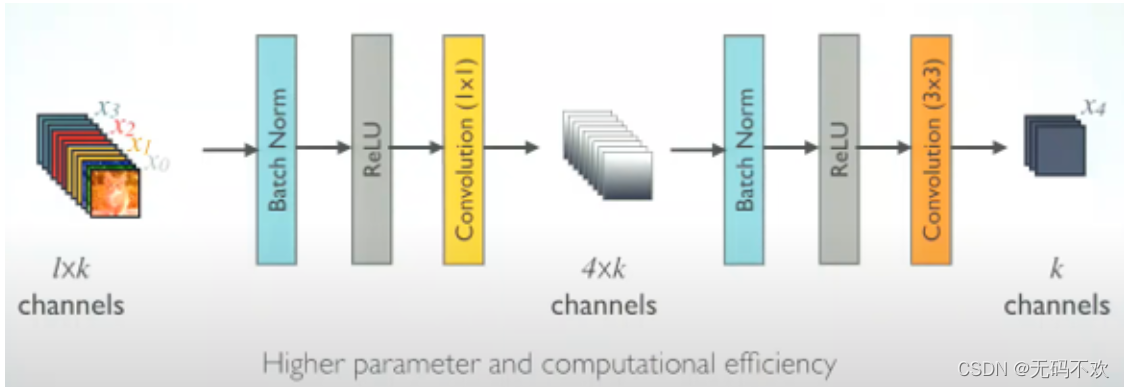
在刚才Dense Block中的非线性组合函数是指BN+ReLU+3x3 Conv的组合,但是出于减少参数的目的,一般会先加一个1x1的卷积来减少参数量.所以我们的非线性组合函数就变成了BN+ReLU+1x1 Conv+BN+ReLU+3x3 Conv的结构.
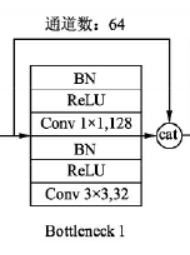
由于后面层的输入会非常大,DenseBlock内部可以采用 bottleneck layers(瓶颈层)来减少计算量,主要是原有的结构中增加1x1 Conv,如下图所示,即BN+ReLU+1x1 Conv+BN+ReLU+3x3 Conv,其对应的网络称为DenseNet-B。其中1x1 Conv得到 4k个特征图它起到的作用是降低特征数量,从而提升计算效率。
4 Transition层
对于Transition层,它主要是连接两个相邻的DenseBlock,并且降低特征图大小。Transition层包括一个1x1的卷积和2x2的AvgPooling,结构为BN+ReLU+1x1 Conv+2x2 AvgPooling。另外,Transition层可以起到压缩模型的作用 。假定Transition的上接DenseBlock得到的特征图channels数为,Transition层可以产生 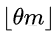
个特征(通过卷积层),其中 θ \theta θ是是压缩系数(compression rate)。它的取值范围是 (0,1],当 θ \theta θ=1时,特征个数经过Transition层没有变化,即无压缩,而当压缩系数小于1时,这种结构称为DenseNet-C,文中使用 θ \theta θ=0.5对于使用bottleneck层的DenseBlock结构和压缩系数小于1的Transition组合结构称为DenseNet-BC。后面在使用的DenseNet默认都是DenseNet-BC,因为它的效果最好。
如果Transition上接的DenseBlock中共有 l l l层,,那么该Transition层的输入通道数是 k 0 k_0 k0+ k ∗ l k*l k∗l
5 网络构建
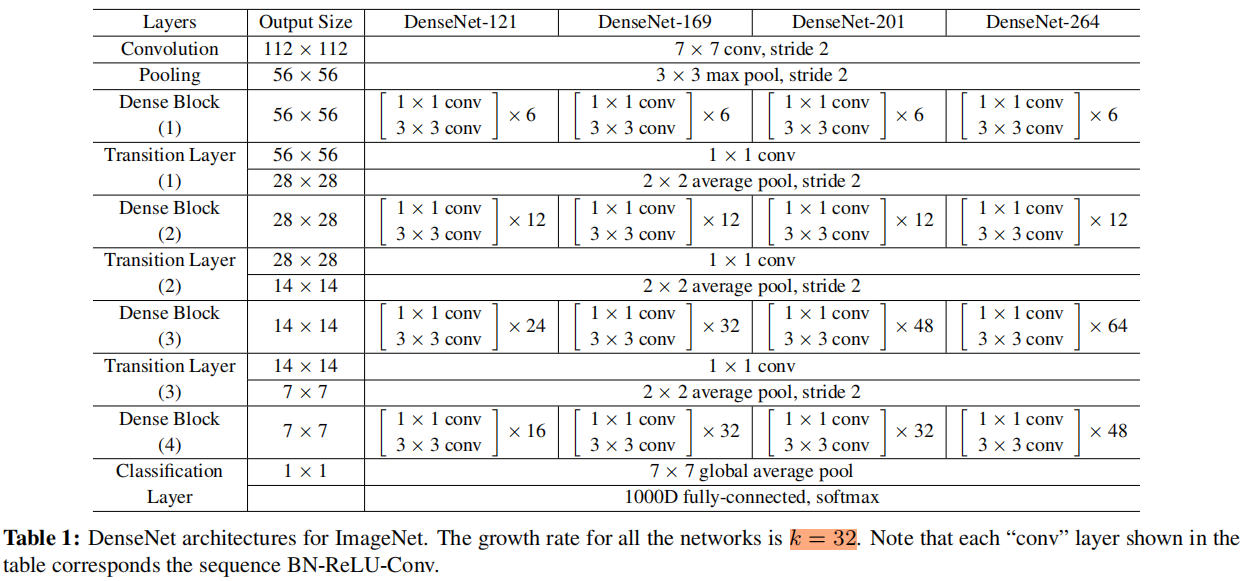
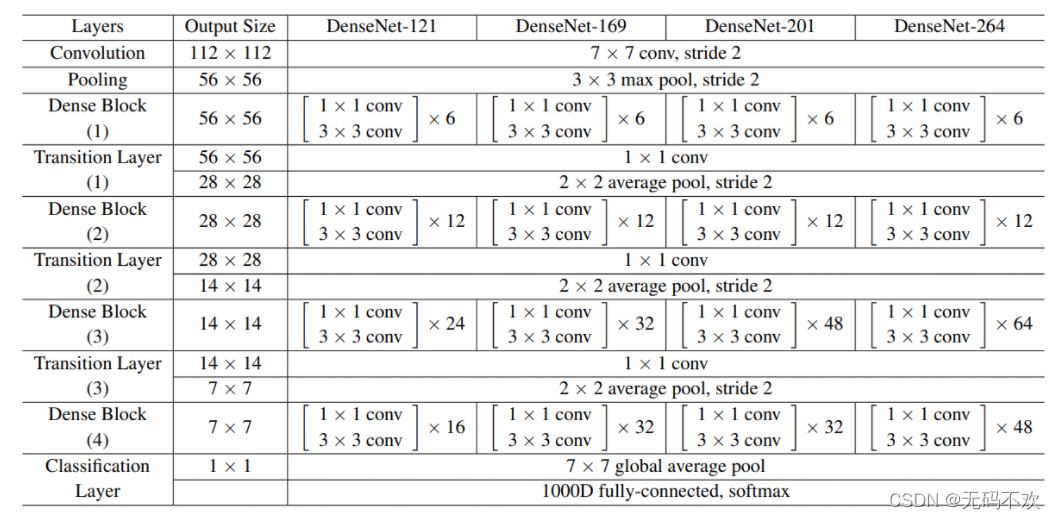
下面我们按照下面的表格来构建4种不同深度的DenseNet
DenseNet的网络结构主要由DenseBlock和Transition组成,一个DenseNet中有3个或4个DenseBlock。而一个DenseBlock中也会有多个Bottleneck layers(下图的DenseBlock结构中的每一个圆圈代表一个Bottleneck layers)。 在代码中,我们将Bottleneck layers,称为Dense layers

DenseNet共在三个图像分类数据集(CIFAR,SVHN和ImageNet)上进行测试。对于前两个数据集,其输入图片大小为32x32,所使用的DenseNet在进入第一个DenseBlock之前,首先进行进行一次3x3卷积(stride=1),卷积核数为16(对于DenseNet-BC为) 。DenseNet共包含三个DenseBlock,各个模块的特征图大小分别为 32x32, 16x16 和8x8 ,每个DenseBlock里面的层数相同。最后的DenseBlock之后是一个global AvgPooling层,然后送入一个softmax分类器。注意,在DenseNet中,所有的3x3卷积均采用padding=1的方式以保证特征图大小维持不变。对于基本的DenseNet,使用如下三种网络配置:
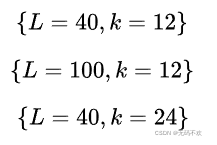
而对于DenseNet-BC结构,使用如下三种网络配置:
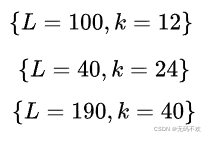
这里的 L L L指的是网络总层数(网络深度),一般情况下,我们只把带有训练参数的层算入其中,而像Pooling这样的无参数层不纳入统计中,此外BN层尽管包含参数但是也不单独统计,而是可以计入它所附属的卷积层。对于普通的 L L L=40, K K K=12 网络,除去第一个卷积层、2个Transition中卷积层以及最后的Linear层,共剩余36层,均分到三个DenseBlock可知每个DenseBlock包含12层。其它的网络配置同样可以算出各个DenseBlock所含层数。
下图是DenseNet-100的参数计算图:它的输出尺寸是 32x32 x3, K K K=12, θ \theta θ=0.5, D x D_x Dx是第 x x x个DenseBlock, D L x DL_x DLx是DenseBlock中的第 x x x个bottleneck layers (瓶颈层), T x T_x Tx是第 x x x个Transition模块, C 1 C_1 C1是一个卷积层 (3x3卷积,stride=1), C 1 C_1 C1中卷积核数个数是2*k=24
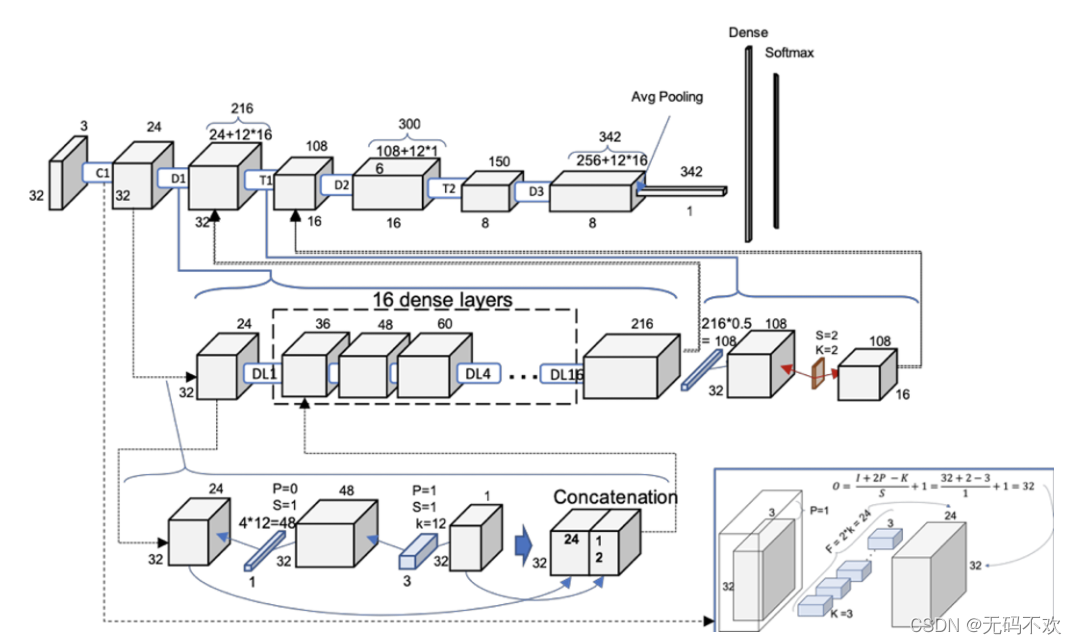
- 在上面示意图中,我们将Bottleneck layers称为dense layers
- 这里展示的DenseNet默认都是DenseNet-BC,因为它的效果最好。
对于ImageNet数据集,图片输入大小为224x224x3, 网络结构采用包含4个DenseBlock的DenseNet-BC,其首先是一个stride=2的7x7卷积层(卷积核数为 ),然后是一个stride=2的3x3 MaxPooling层,后面才进入DenseBlock。ImageNet数据集所采用的网络配置如表1所示:
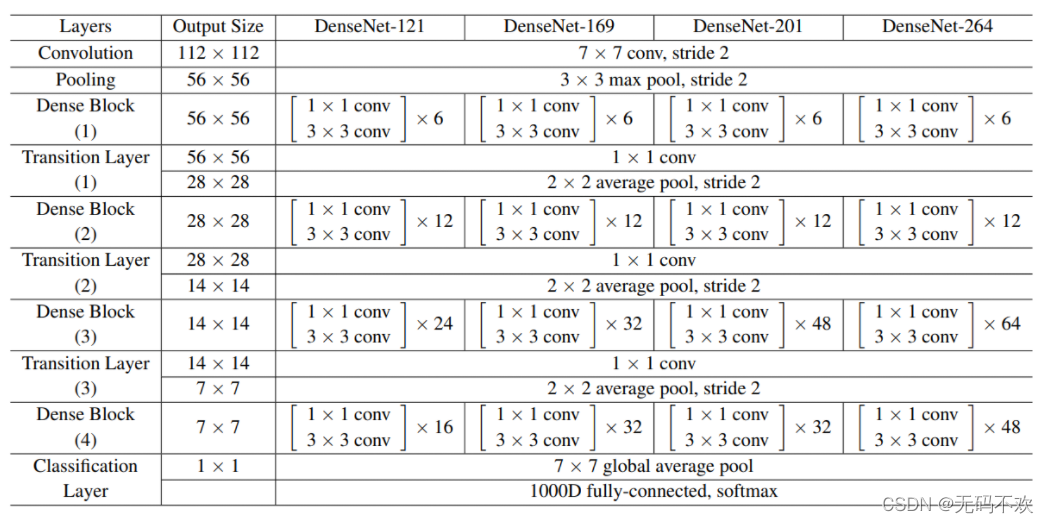
下图是DenseNet-121的参数计算图:其中 K K K=32, θ \theta θ=0.5, D x D_x Dx是第 x x x个DenseBlock, D L x DL_x DLx是DenseBlock中的第 x x x个bottleneck layers (瓶颈层), T x T_x Tx是第 x x x个Transition模块, C 1 C_1 C1是上面表格中的Convolution部分(包括一个7x7的卷积和一个3x3的最大池化), C 1 C_1 C1中卷积核数个数是2*k=64
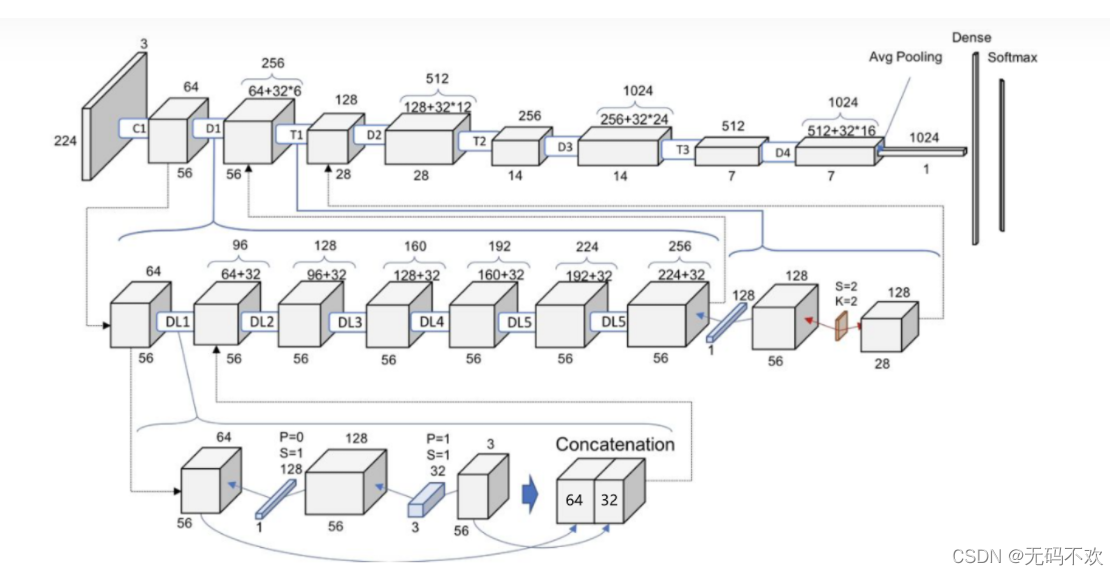
- C_1中卷积核数个数是2*k=64
- 在上面示意图中,我们将Bottleneck layers称为dense layers
- 这里展示的DenseNet默认都是DenseNet-BC,因为它的效果最好。
6 DenseNet和其它模型的性能对比
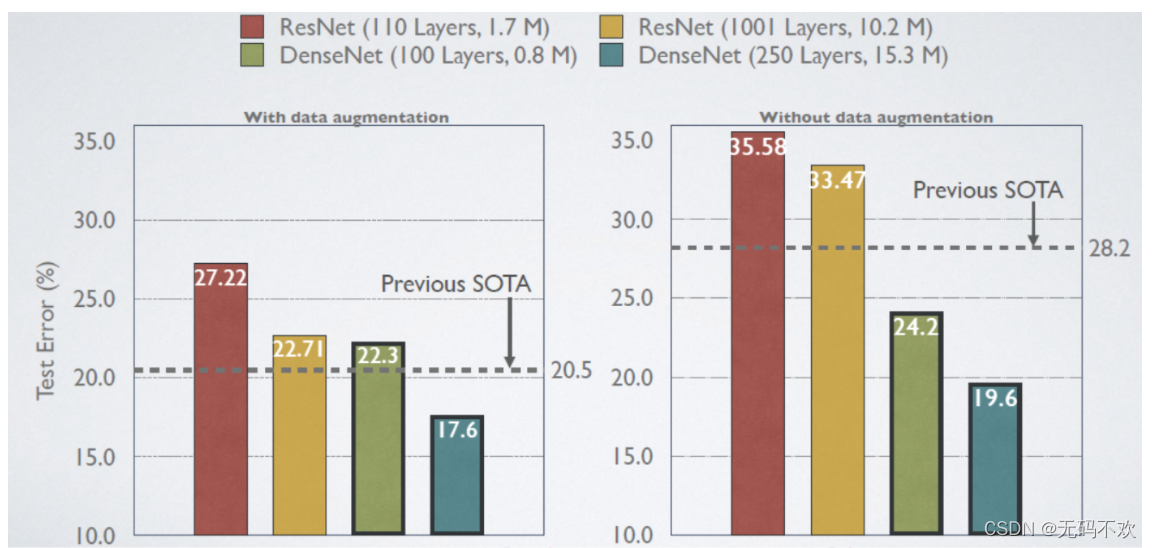
这里给出DenseNet在CIFAR-100数据集上与ResNet的对比结果,从下图中可以看到,只有0.8M的DenseNet-100性能已经超越ResNet-1001,并且后者参数大小为10.2M。
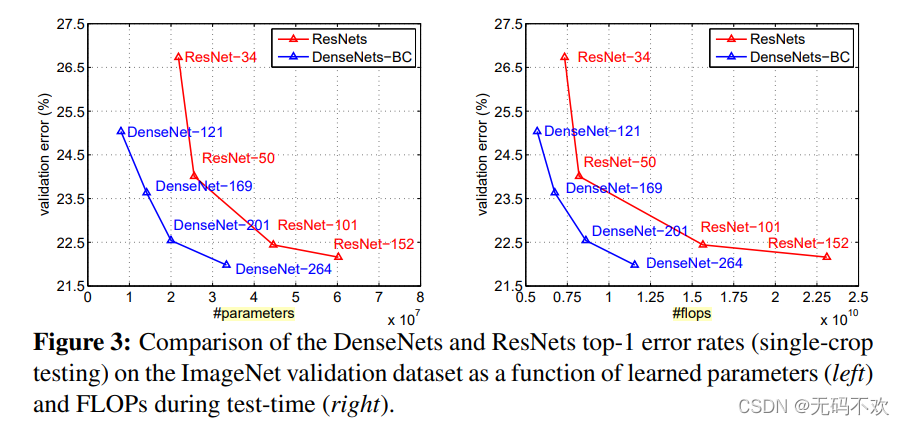
DenseNet-BC和ResNet在Imagenet数据集上的对比,左边那个图是参数复杂度和错误率的对比,你可以在相同错误率下看参数复杂度,也可以在相同参数复杂度下看错误率,提升还是很明显的!右边是flops(可以理解为计算复杂度)和错误率的对比,同样有效果。
下面给出了DenseNet更其它模型在 CIFAR-10 (C10) , CIFAR-100 (C100),SVHN 数据集的错误率 (%)。 k 表示网络的增长率。超越所有竞争方法的结果用粗体进行表示,整体最佳结果为蓝色。 “+”表示标准数据增强(翻译和/或镜像)。
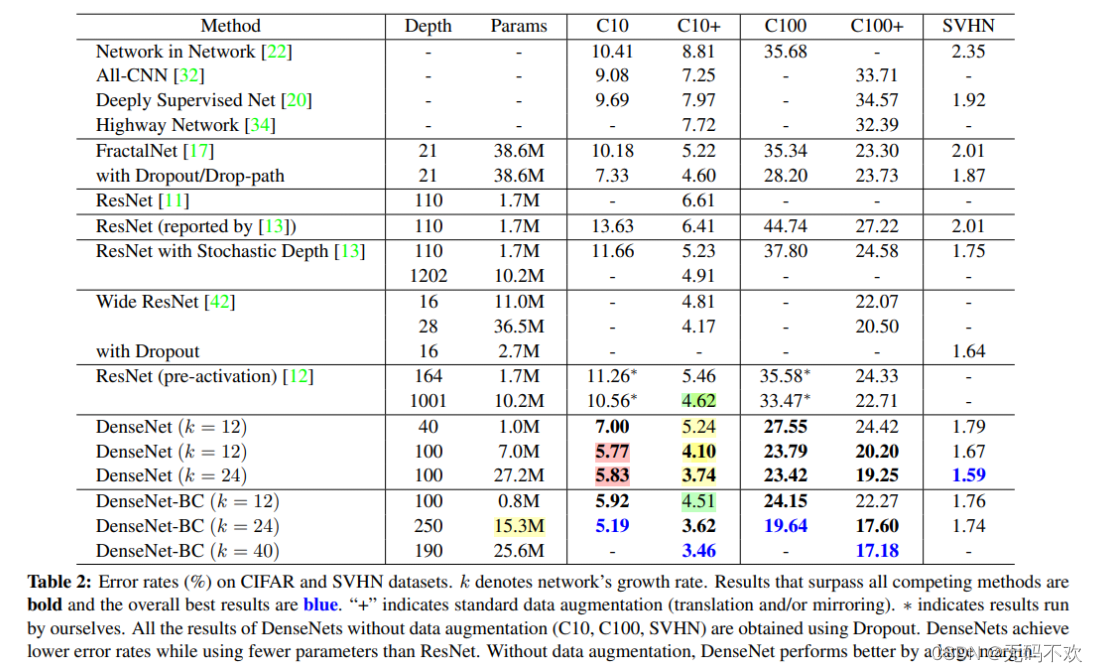
由上表可得到如下结论:
- DenseNets 在使用比 ResNet 更少的参数的同时实现了更低的错误率
- DenseNet-BC-190获得最优成绩
- DenseNet的性能随K和L增大而提升
- DenseNet-BC-100十分省参数,在达到100层的适合模型参数仅0.8M
- 由粉红色部分的结果可知,在网络参数增大的同时错误率反而没有随之降低,这可能是出现了过拟合情况,需要用数据增强来解决。
- 由绿色部分的结果可知,在错误率相差相同的情况下,DenseNet比 ResNet 更省参数,参数量是或者的十分之一不到
下图是DenseNet模型在CIFAR-10数据集 (使用了数据增强) 上的表现结果
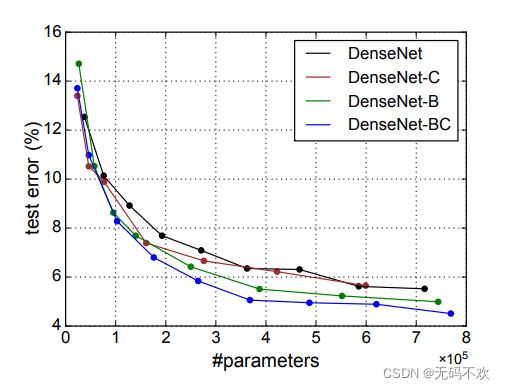
由上图可得到如下结论:
- DenseNet-C 优于DenseNet
- DenseNet-B优于 DenseNet-C
- DenseNet-BC 优于DenseNet-B
下图是不同深度的DenseNet-在ImageNet数据集上的错误率:
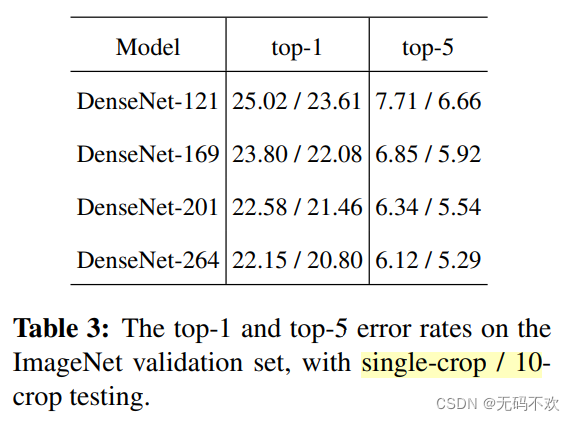
结论:
- 10-crop均比single-crop精度高
- 网络越深,精度越高
7 DenseNet的思考
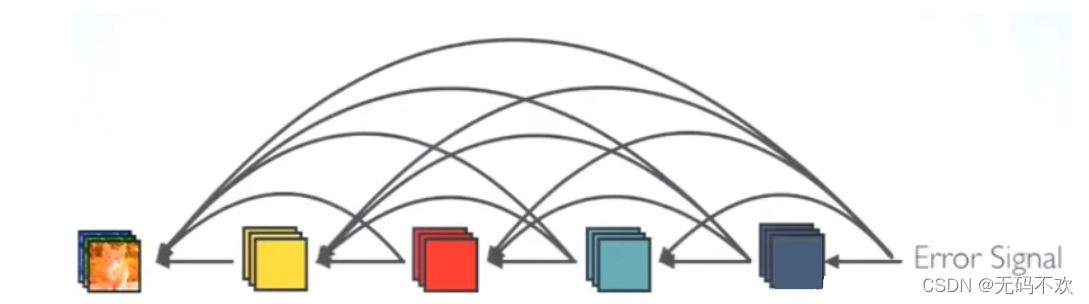
更强的梯度流动
DenseNet可以说是一种隐式的强监督模式,因为每一层都建立起了与前面层的连接,误差信号可以很容易地传播到较早的层,所以较早的层可以从最终分类层获得直接监管。
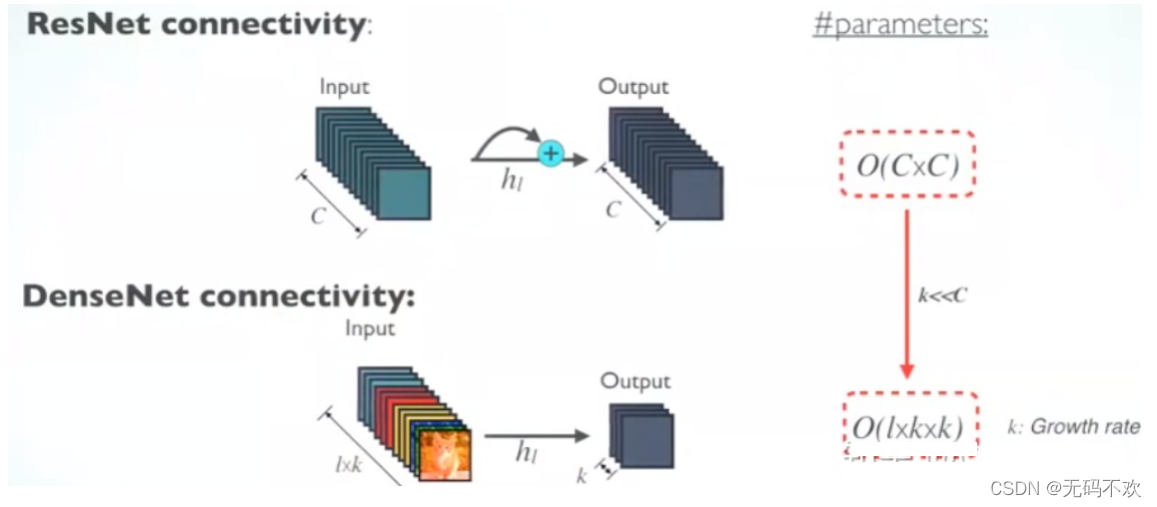
参数更少计算效率更高
我们可以看到,在ResNet中,参数量与 C C Cx C C C成正比,而在DenseNet中参数量与 l l lx k k kx k k k 成正比,因为 k k k远小于 C C C,所以DenseNet的参数量小得多.
保存了低维度的特征
在标准的卷积网络中,最终输出只会利用提取最高层次的特征.
而在DenseNet中,它使用了不同层次的特征,它倾向于给出更平滑的决策边界。这也解释了为什么训练数据不足时DenseNet表现依旧良好。
8 代码实现1
本节来实现输出尺寸为224x224的DenseNet模型
8.1 DenseBlock的构建
一个DenseBlock是由多个Bottleneck layers组成 在代码中,我们将Bottleneck layers 称为Dense layers ( 注意:这里实现的DenseNet默认都是DenseNet-BC,因为它的效果最好)。所以我们首先构建来Dense layers
class _DenseLayer(nn.Module):def __init__(self, num_input_features, growth_rate, bn_size, drop_rate, memory_efficient=False):super(_DenseLayer, self).__init__()# memory_efficient:是否使用节省内存的方法# 1*1卷积,执行“压缩”通道数至, 4*K, bn_size * growth_rate = 4*k# self.add_module:给当前模块添加子模块self.add_module('norm1', nn.BatchNorm2d(num_input_features)),self.add_module('relu1', nn.ReLU(inplace=True)),self.add_module('conv1', nn.Conv2d(num_input_features, bn_size *growth_rate, kernel_size=1, stride=1,bias=False)),self.add_module('norm2', nn.BatchNorm2d(bn_size * growth_rate)),self.add_module('relu2', nn.ReLU(inplace=True)),self.add_module('conv2', nn.Conv2d(bn_size * growth_rate, growth_rate,kernel_size=3, stride=1, padding=1,bias=False)),self.drop_rate = float(drop_rate)self.memory_efficient = memory_efficient# bn_function 执行的是1*1卷积那部分的操作 def bn_function(self, inputs):# type: (List[Tensor]) -> Tensorconcated_features = torch.cat(inputs, 1)bottleneck_output = self.conv1(self.relu1(self.norm1(concated_features))) # noqa: T484return bottleneck_output# torchscript does not yet support *args, so we overload method# allowing it to take either a List[Tensor] or single Tensordef forward(self, input): # noqa: F811if isinstance(input, Tensor):prev_features = [input]else:prev_features = inputif self.memory_efficient and self.any_requires_grad(prev_features):if torch.jit.is_scripting():raise Exception("Memory Efficient not supported in JIT")bottleneck_output = self.call_checkpoint_bottleneck(prev_features)else:bottleneck_output = self.bn_function(prev_features)# 执行 3*3 卷积那部分操作new_features = self.conv2(self.relu2(self.norm2(bottleneck_output)))if self.drop_rate > 0:new_features = F.dropout(new_features, p=self.drop_rate,training=self.training)return new_features
然后我们来构建DenseBlock
import torch
import torch.nn as nn
from collections import OrderedDict
from torch import Tensor
import torch.nn.functional as Fclass _DenseBlock(nn.ModuleDict):_version = 2# 这是一个nn.ModuleDict类 ,是一个可迭代对象,就像python中的字典,可以通过 dict.items() 进行循环#由于densenet在训练过程中十分消耗内存,所以pytorch官方实现了可以节省内存的方法可供选择,#当然这是一个可选项,它可以通过参数memory_efficient来选择是否使用节省内存的方法,默认不使用#pytorch官方实现了可以节省内存的方法其实是是以时间换空间,如果想节省内存的必然导致训练时间的加长def __init__(self, num_layers, num_input_features, bn_size, growth_rate, drop_rate, memory_efficient=False):super(_DenseBlock, self).__init__()for i in range(num_layers):# 调用 _DenseLayer 构建每个 _DenseLayer, 等同于论文中 Bottleneck layerlayer = _DenseLayer (num_input_features + i * growth_rate, growth_rate=growth_rate,bn_size=bn_size,drop_rate=drop_rate,memory_efficient=memory_efficient,)self.add_module('denselayer%d' % (i + 1), layer) #self.add_module:给当前模块添加子模块def forward(self, init_features):features = [init_features]for name, layer in self.items():new_features = layer(features)features.append(new_features)# 将特征图再通道维度,进行拼接。 B*C*H*Wreturn torch.cat(features, 1)8.2 Transition层的构建
Transition层包括一个1x1的卷积和2x2的AvgPooling,结构为BN+ReLU+1x1 Conv+2x2 AvgPooling。
class _Transition(nn.Sequential):def __init__(self, num_input_features, num_output_features):# num_output_features 是1*1卷积的卷积核数量,决定了transition输出特征图的通道数,前边我们提到的压缩系数θ其实通过 num_output_features就可以实现,比如θ=0.5等效于 num_output_features = num_input_features//2super(_Transition, self).__init__()self.add_module('norm', nn.BatchNorm2d(num_input_features))self.add_module('relu', nn.ReLU(inplace=True))self.add_module('conv', nn.Conv2d(num_input_features, num_output_features,kernel_size=1, stride=1, bias=False))self.add_module('pool', nn.AvgPool2d(kernel_size=2, stride=2))
8.3 DenseNet的构建
# DenseNet 系列 类定义, 初始化函数中可接受一系列参数,用于生产不同深度、宽度的DenseNet
class DenseNet(nn.Module):r"""Densenet-BC model class, based on`"Densely Connected Convolutional Networks" <https://arxiv.org/pdf/1608.06993.pdf>`_Args:growth_rate (int) - how many filters to add each layer (`k` in paper)block_config (list of 4 ints) - how many layers in each pooling blocknum_init_features (int) - the number of filters to learn in the first convolution layerbn_size (int) - multiplicative factor for number of bottle neck layers(i.e. bn_size * k features in the bottleneck layer)drop_rate (float) - dropout rate after each dense layernum_classes (int) - number of classification classesmemory_efficient (bool) - If True, uses checkpointing. Much more memory efficient,but slower. Default: *False*. See `"paper" <https://arxiv.org/pdf/1707.06990.pdf>`_"""__constants__ = ['features']def __init__(self, growth_rate=32, block_config=(6, 12, 24, 16),num_init_features=64, bn_size=4, drop_rate=0, num_classes=1000, memory_efficient=False):super(DenseNet, self).__init__()# First convolutionself.features = nn.Sequential(OrderedDict([('conv0', nn.Conv2d(3, num_init_features, kernel_size=7, stride=2,padding=3, bias=False)),('norm0', nn.BatchNorm2d(num_init_features)),('relu0', nn.ReLU(inplace=True)),('pool0', nn.MaxPool2d(kernel_size=3, stride=2, padding=1)),]))# Each denseblocknum_features = num_init_features # 64 , 2*k for i, num_layers in enumerate(block_config):# 利用 _DenseBlock 构建每一个 Dense Blockblock = _DenseBlock(num_layers=num_layers,num_input_features=num_features,bn_size=bn_size,growth_rate=growth_rate,drop_rate=drop_rate,memory_efficient=memory_efficient)# 添加一个model到 Sequential当中self.features.add_module('denseblock%d' % (i + 1), block)# 计算经过该Dense block,特征图通道数变为了多少num_features = num_features + num_layers * growth_rate# 如果不是最后一个Dense Block,则需要进行 transition layerif i != len(block_config) - 1:# 构建transition layertrans = _Transition(num_input_features=num_features,num_output_features=num_features // 2) # compression θ=0.5# 将_Transition类, 添加到Sequential当中;;;注:_Transition类是一个 nn.Sequentialself.features.add_module('transition%d' % (i + 1), trans)# 当前特征图通道数量, compression θ=0.5, 所以除以2num_features = num_features // 2# Final batch normself.features.add_module('norm5', nn.BatchNorm2d(num_features))# 最后一个FC层的定义# Linear layerself.classifier = nn.Linear(num_features, num_classes)# Official init from torch repo.for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight)elif isinstance(m, nn.BatchNorm2d):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):nn.init.constant_(m.bias, 0)def forward(self, x):# 头部卷积 + DenseBlock堆叠features = self.features(x) # 池化+全连接,分类输出out = F.relu(features, inplace=True)out = F.adaptive_avg_pool2d(out, (1, 1))out = torch.flatten(out, 1)out = self.classifier(out)return out# 定义函数 用于创建模型,同时加载与训练参数
def _densenet(arch, growth_rate, block_config, num_init_features, pretrained, progress,**kwargs):model = DenseNet(growth_rate, block_config, num_init_features, **kwargs)if pretrained:_load_state_dict(model, model_urls[arch], progress)return model# 模型命名有问题,因此需要对key进行修改
def _load_state_dict(model, model_url, progress):# '.'s are no longer allowed in module names, but previous _DenseLayer# has keys 'norm.1', 'relu.1', 'conv.1', 'norm.2', 'relu.2', 'conv.2'.# They are also in the checkpoints in model_urls. This pattern is used# to find such keys.pattern = re.compile(r'^(.*denselayer\d+\.(?:norm|relu|conv))\.((?:[12])\.(?:weight|bias|running_mean|running_var))$')state_dict = load_state_dict_from_url(model_url, progress=progress)for key in list(state_dict.keys()):res = pattern.match(key)if res:new_key = res.group(1) + res.group(2)state_dict[new_key] = state_dict[key]del state_dict[key]model.load_state_dict(state_dict)# densenet121 设计
def densenet121(pretrained=False, progress=True, **kwargs):return _densenet('densenet121', 32, (6, 12, 24, 16), 64, pretrained, progress,**kwargs)
# growth_rate = 32
# block_config = (6, 12, 24, 16), 表示dense block中有多少个dense layer堆叠
# num_init_features = 64, 头部卷积层卷积核数量,2k = 2*32 = 64 def densenet161(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> DenseNet:return _densenet('densenet161', 48, (6, 12, 36, 24), 96, pretrained, progress,**kwargs)def densenet169(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> DenseNet:return _densenet('densenet169', 32, (6, 12, 32, 32), 64, pretrained, progress,**kwargs)def densenet201(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> DenseNet:return _densenet('densenet201', 32, (6, 12, 48, 32), 64, pretrained, progress,**kwargs)
实例化网络:
fake_data = torch.randn((2, 3, 224, 224))
densenet121_model = densenet121()
outputs = densenet121_model(fake_data)print(outputs.shape)
输出结果:
torch.Size([2, 1000])
8.4 直接使用pytorch官方提供的接口实例化模型
- 只实例化模型,不加载权重
model = models.densenet121(pretrained=False)
- 实例化模型的同时加载预训练权重
model = models.densenet121(pretrained=True)
9 代码实现2
本节来实现输出尺寸为32x32的DenseNet模型
# -*- coding: utf-8 -*-
'''DenseNet-BC in PyTorch for Cifar10.
See the paper "Densely Connected Convolutional Networks" for more details.
https://github.com/bamos/densenet.pytorch/blob/master/densenet.py
'''
import torch
import torch.nn as nn
import torch.nn.functional as F
import mathclass Bottleneck(nn.Module):def __init__(self, nChannels, growthRate):super(Bottleneck, self).__init__()interChannels = 4*growthRateself.bn1 = nn.BatchNorm2d(nChannels)self.conv1 = nn.Conv2d(nChannels, interChannels, kernel_size=1, bias=False)self.bn2 = nn.BatchNorm2d(interChannels)self.conv2 = nn.Conv2d(interChannels, growthRate, kernel_size=3, padding=1, bias=False)def forward(self, x):out = self.conv1(F.relu(self.bn1(x)))out = self.conv2(F.relu(self.bn2(out)))out = torch.cat((x, out), 1) # 在此体现dense connection,两个特征图拼接起来return out# 这个是不使用1x1卷积的的DenseBlock,一般很少使用
class SingleLayer(nn.Module):def __init__(self, nChannels, growthRate):super(SingleLayer, self).__init__()self.bn1 = nn.BatchNorm2d(nChannels)self.conv1 = nn.Conv2d(nChannels, growthRate, kernel_size=3, padding=1, bias=False)def forward(self, x):out = self.conv1(F.relu(self.bn1(x)))out = torch.cat((x, out), 1)return outclass Transition(nn.Module):def __init__(self, nChannels, nOutChannels):super(Transition, self).__init__()self.bn1 = nn.BatchNorm2d(nChannels)self.conv1 = nn.Conv2d(nChannels, nOutChannels, kernel_size=1,bias=False)def forward(self, x):out = self.conv1(F.relu(self.bn1(x)))out = F.avg_pool2d(out, 2)return outclass DenseNet(nn.Module):def __init__(self, growthRate, depth, reduction, nClasses, bottleneck):super(DenseNet, self).__init__()nDenseBlocks = (depth-4) // 3 # 4 表示第一个卷积层 + 2个transition + 1个FC层输出分类 ;;;3表示3个blockif bottleneck:nDenseBlocks //= 2 # 2表示一个基础操作模块中有2层nChannels = 2*growthRate # 第一个卷积的卷积核个数为 growthRate的两倍self.conv1 = nn.Conv2d(3, nChannels, kernel_size=3, padding=1, bias=False)# 第一个 denseblockself.dense1 = self._make_denseblock(nChannels, growthRate, nDenseBlocks, bottleneck)nChannels += nDenseBlocks*growthRate # 计算经过denseblock之后有多少个通道nOutChannels = int(math.floor(nChannels*reduction)) # 计算经过Compression后,还有几个通道reduction对应论文中的θself.trans1 = Transition(nChannels, nOutChannels)# 第二个 denseblocknChannels = nOutChannelsself.dense2 = self._make_denseblock(nChannels, growthRate, nDenseBlocks, bottleneck)nChannels += nDenseBlocks*growthRatenOutChannels = int(math.floor(nChannels*reduction))self.trans2 = Transition(nChannels, nOutChannels)# 第三个 denseblocknChannels = nOutChannelsself.dense3 = self._make_denseblock(nChannels, growthRate, nDenseBlocks, bottleneck)nChannels += nDenseBlocks*growthRate# 分类输出层self.bn1 = nn.BatchNorm2d(nChannels)self.fc = nn.Linear(nChannels, nClasses)# 权值初始化for m in self.modules():if isinstance(m, nn.Conv2d):n = m.kernel_size[0] * m.kernel_size[1] * m.out_channelsm.weight.data.normal_(0, math.sqrt(2. / n))elif isinstance(m, nn.BatchNorm2d):m.weight.data.fill_(1)m.bias.data.zero_()elif isinstance(m, nn.Linear):m.bias.data.zero_()def _make_denseblock(self, nChannels, growthRate, nDenseBlocks, bottleneck):"""创建denseblock:param nChannels: 进入block的特征图的通道数:param growthRate: int:param nDenseBlocks: blocks堆叠的数量:param bottleneck: boolean,是否需要bottleneck, densenet-b:return:"""layers = []for i in range(int(nDenseBlocks)):if bottleneck:layers.append(Bottleneck(nChannels, growthRate))else:layers.append(SingleLayer(nChannels, growthRate))nChannels += growthRate # 通道数逐渐增加,从此看出block中各层的输入均包含进入block的特征图return nn.Sequential(*layers)def forward(self, x):# 1/3 头部的卷积out = self.conv1(x)# 2/3 dense block 的堆叠out = self.trans1(self.dense1(out))out = self.trans2(self.dense2(out))out = self.dense3(out)# 3/3 池化+全连接,输出分类out = torch.squeeze(F.avg_pool2d(F.relu(self.bn1(out)), 8))# out = F.log_softmax(self.fc(out))out = self.fc(out)return out
实例化40层的网络
#这里的growthRate是增长率,depth是网络深度,reduction是Transition层中的压缩系数,bottleneck=True表示使用瓶颈模块,nClasses表示输出类别数densenet_model = DenseNet(growthRate=24, depth=40, reduction=0.5, bottleneck=True, nClasses=10)
实例化100层的网络
#这里的growthRate是增长率,depth是网络深度,reduction是Transition层中的压缩系数,bottleneck=True表示使用瓶颈模块,nClasses表示输出类别数densenet_model = DenseNet(growthRate=12, depth=100, reduction=0.5, bottleneck=True, nClasses=10)
10 小节
DenseNet的优势
- 更强的梯度流动,跳层连接更多,梯度更容易向前传播,使得网络更容易训练。由于每层可以直达最后的误差信号,实现了隐式的 “deep supervision”
- 参数更小且计算更高效,这有点违反直觉,由于DenseNet是通过concat特征来实现短路连接,实现了特征重用,并且采用较小的growth rate,每个层所独有的特征图是比较小的;
- 由于低级特征得以复用,使得特征更丰富。
DenseNet的缺点
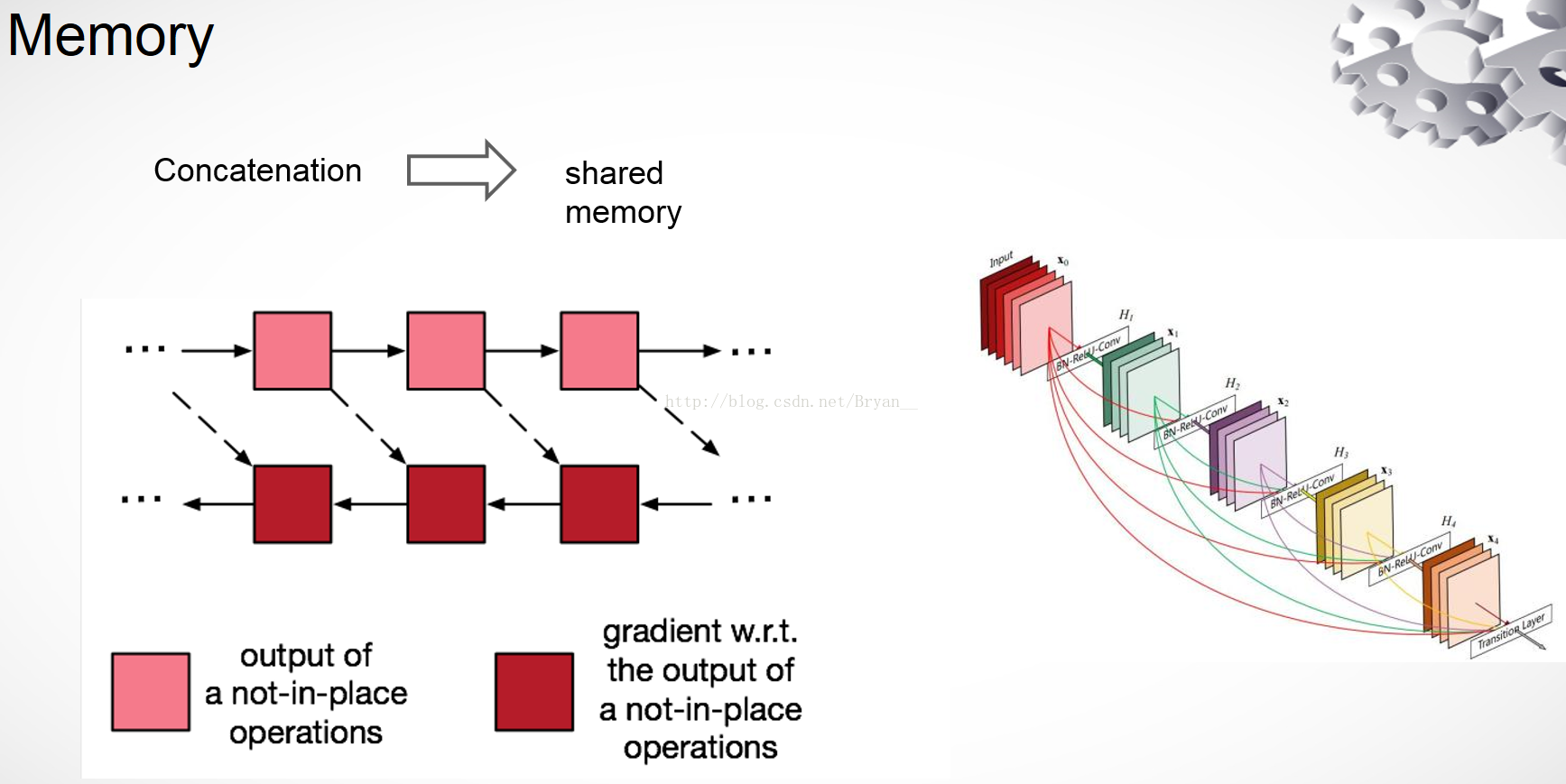
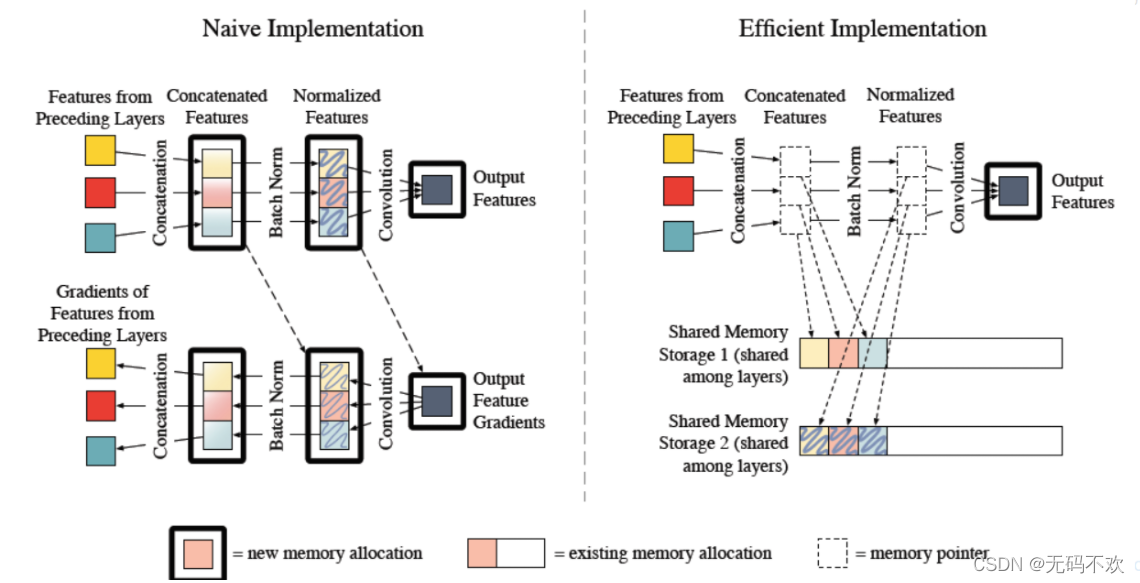
DenseNet的训练及其消耗内存,因为它需要保存大量的特征图用于反向传播。于是,针对该缺点的改进,作者进一步研究,发表了《Memory-Efficient Implementation of DenseNets》。另外可以参考这篇博客 https://zhuanlan.zhihu.com/p/31558973,它详细介绍了深度学习中显存的使用情况。
由于densenet在训练过程中十分消耗内存,所以pytorch官方实现了可以节省内存的方法可供选择,当然这是一个可选项,它可以通过一个参数memory_efficient来选择是否使用节省内存的方法,默认不使用。不过pytorch官方实现了可以节省内存的方法其实是是以时间换空间,如果想节省内存的必然导致训练时间的加长
读DenseNet论文得到的启发点:
- 信息流通不顺畅时,普遍采样捷径连接(或短连接)来处理
- 多采用捷径连接(或短连接),便于信息流通,以及梯度传递,可使模型便于训练
- 稠密连接在小数据集上起到正则化作用,也有一种说法是DenseNet比较适合小数据集
- 不同层处理得到的特征进行拼接,可丰富下一层网络输入特征的多样性,以及提高效率 (这里的提高效率指的是不需要额外的计算,就可以得到特征)
- ResNet的求和形式有缺点,会阻碍信息的流通,而DenseNet中的拼接方式要比求和效果更好
- 多级特征融合时,要在卷积层之前执行BN和ReLU,再进行conv。否则多个层级输出时就执行conv,会导致特征的尺度不一致
- 模型不能进一步提升性能,无法拉开与浅层模型的差异时,不一定是模型设计问题,有可能是数据集太小,不足以体现现在模型的能力
参考:
https://arxiv.org/abs/1608.06993
https://zhuanlan.zhihu.com/p/37189203
https://zhuanlan.zhihu.com/p/141178215