文章目录
- 一、引导
- 二、WaterMark
- 1、Watermark的原理
- 2、Watermark 的使用
- 2.1、顺序数据流中的watermark
- 示例
- 2.2、乱序数据流中的WaterMark
- 2.2.1、With Periodic(周期性的) Watermark
- 示例一:使用周期性的WaterMark
- 2.2.2、With Punctuated(间断性的)Watermark
- 示例二:使用间断性的WaterMark
- 2.3、多并行度数据流中的 Watermark
- 示例
- 2.4、迟到的数据处理机制
- 2.4.1、allowedLateness
- 2.4.2、sideOutputLateData
- 示例:使用allowedLateness和sideOutputLateData对迟到数据进行处理
一、引导
提问:你了解事件的乱序吗?乱序是怎么产生的呢?在flink流处理中是以什么事件类型判定乱序的呢?
当一条一条的数据从产生到经过消息队列传输,然后Flink接受后处理,这个流程中数据都是按照数据产生的先后顺序在flink中处理的,这时候就是有序的数据流。
温馨提示:理解下面的图时,可以把数字看作是事件产生的先后顺序
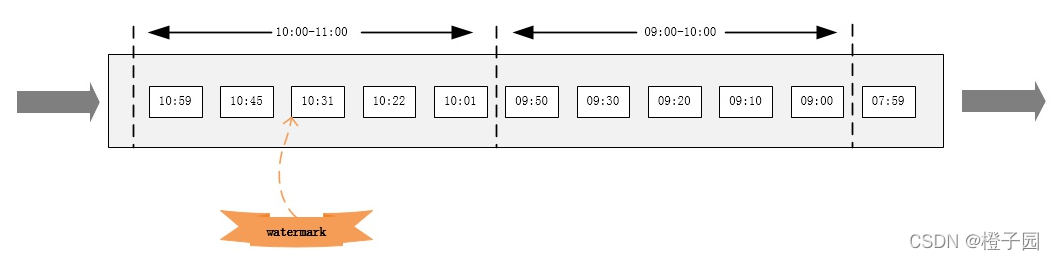
有序的数据流如下图:

如果过程中出现异常,有些数据延迟了,造成了后面产生的数据出现在了前面,这样就出现了乱序。
乱序的数据流如下图:

当然从上面的描述中我们也可以判断出flink流处理中是以evenTime事件类型判定乱序的。
二、WaterMark
从原始设备产生事件数据,到Flink程序读取数据,再到Flink多个算子处理数据,在这个过程中由于网络或者系统等外部因素影响下,导致数据是乱序的。
乱序会导致各种统计结果有问题。比如一个Time Window本应该计算1、2、3,结果3迟到了,那么这个窗口统计就丢失数据了,结果就不准确了。

这时我们如何保证计算结果的正确性?我们会想到等待数据,但等待数据势必会造成计算的延迟,我们该如何权衡呢?
对于延迟太久的数据,不能无限期的等下去,所以必须有一个机制,来保证特定的时间后一定会触发窗口进行计算。
flink 引入了WaterMark(水位线)机制,来对乱序事件进行处理,在我们的项目场景中通常会使用WaterMark机制结合窗口来实现对乱序数据计算的场景,这样我们就能最大程度的确保乱序数据能在正确的窗口内参与计算。
1、Watermark的原理
当 Event 进入到 Flink 系统时,会根据当前最大事件产生时间生成 Watermark 时间戳。
WaterMark 值的计算公式如下:
Watermark = 进入Flink的最大的事件产生时间(maxEventTime) - 指定的乱序时间(t)
引入Watermark 的 Window 触发窗口函数计算的条件:
(1)watermark >= window的结束时间
(2)该窗口必须有数据,注意:[window_start_time,window_end_time) 中有数据存在,前闭后开区间
2、Watermark 的使用
我们先分析一下:Watermark策略使用事件时间, Flink需要知道事件时间戳,所以每条流数据需要分配事件时间戳,一般我们会通过从记录字段访问或提取时间戳。还有就是生成watermark,根据WaterMark可以知道系统处理事件时间执行到哪了。
flink使用waterMark api时要求一个WatermarkStrategy实例包含TimestampAssigner 和WatermarkGenerator,WatermarkStrategy上的静态方法上有很多开箱即用的策略方法, 一般情况下我们使用它即可,当然也可以使用自定义WatermarkStrategy。


在Flink应用中有两个地方使用WatermarkStrategy :
- 直接在数据源上
- 数据源操作后
直接在数据源上使用最好,因为在watermarking逻辑中它允许数据源利用计算机系统存储关于shards/partitions/splits信息. 数据源通常在细粒度上跟踪watermark,并且所有被数据源生成的watermark更精准. 在数据源上直接指定WatermarkStrategy,通常意味站你不得不指定接口或指向Watermark Strategies and the Kafka Connector,在Kafka Connector上运行和更多关于watermark在每个分区的怎样运算。在操作后设置WatermarkStrategy,应该仅仅在你不能直接在source设置时使用,下面例子我们都是使用的在操作后使用示例。

下面我们通过WaterMark使用的三种情况来理解它的使用,分别是:顺序数据流中使用WaterMark、乱序数据流中使用WaterMark、多并行度下使用WaterMark。
2.1、顺序数据流中的watermark
在某些情况下,基于Event Time的数据流是有续的(相对event time)。在有序流中,watermark就是一个简单的周期性标记。
如果数据元素的事件时间是有序的,Watermark 时间戳会随着数据元素的事件时间按顺序生成,此时水位线的变化和事件时间保持一直(因为既然是有序的时间,就不需要设置延迟了,那么 t 就是 0。
所以 watermark = maxtime - 0 = maxtime,也就是理想状态下的水位线。当 Watermark 时间大于 Windows 结束时间就会触发对 Windows 的数据计算,以此类推, 下一个 Window 也是一样。
示例
需求:对socket中有序(按照时间递增)的数据流,进行每5s处理一次
提示:将数据中的timestamp根据指定的字段提取得到Eventtime,然后使用Eventtime作为最新的watermark, 这种适合于事件按顺序生成,没有乱序事件的情况,api中使用assignAscendingTimestamps指定WaterMark。
代码:
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows
//import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collectorobject StreamOrderedWaterMark {def main(args: Array[String]): Unit = {val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironmentimport org.apache.flink.api.scala._env.setParallelism(1)//设置为EventTime时间类型,在高版本中默认是eventime
// environment.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)//使用watermark+eventTime来解决乱序的问题,这里数据中必须要带有事件产生时间val sourceStream: DataStream[String] = env.socketTextStream("companynode01",19999)val mapStream: DataStream[(String, Long)] =sourceStream.map(x=>(x.split(",")(0), x.split(",")(1).toLong))//从源Event中抽取eventTime,有序的数据流,这里可以直接使用assignAscendingTimestamps 设置把事件生成时间看成是watermarkval watermarkStream: DataStream[(String, Long)] = mapStream.assignAscendingTimestamps(x=>x._2)//数据计算watermarkStream.keyBy(_._1).window(TumblingEventTimeWindows.of(Time.seconds(5))).process(new ProcessWindowFunction[(String, Long), (String,Long), String, TimeWindow] {override def process(key: String, context: Context,elements: Iterable[(String, Long)],out: Collector[(String, Long)]): Unit = {//窗口的开始时间val startTime: Long = context.window.getStart//窗口的结束时间val startEnd: Long = context.window.getEnd//获取当前的 watermarkval watermark: Long = context.currentWatermark//记录条数var sum:Long = 0val toList: List[(String, Long)] = elements.toListfor(eachElement <- toList){sum += 1}println("窗口的数据条数:"+sum+" |窗口的第一条数据:"+toList.head+" |窗口的最后一条数据:"+toList.last+" |窗口的开始时间: "+ startTime+" |窗口的结束时间: "+ startEnd+" |当前的watermark:"+ watermark)// 搜集key值和窗口内记录的条数out.collect((key, sum))}}).print()env.execute()}}
socket发送数据
000001,1650006862000
000001,1650006866000
000001,1650006872000
000001,1650006873000
000001,1650006874000
000001,1650006875000

结果图:

2.2、乱序数据流中的WaterMark
现实情况下数据元素往往并不是按照其产生顺序接入到 Flink 系统中进行处理,而频繁出现乱序或迟到的情况,这种情况就需要使用 Watermarks 来应对。
比如下图,假设窗口大小为1小时,延迟时间设为10分钟。明显,数据09:38已经迟到,但它依然会被正确计算,只有当有数据时间大于10:10的数据到达之后(即对应的watermark大于10:10-10min), 09:00~10:00的窗口才会执行计算。
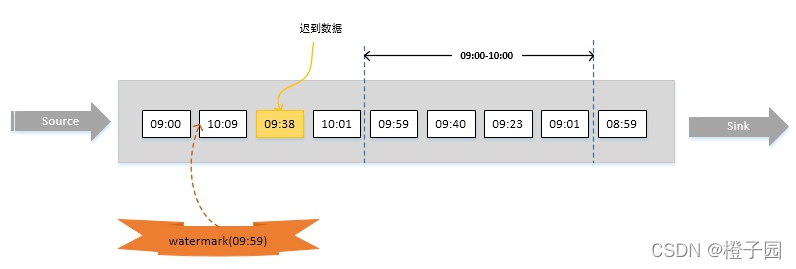
对于乱序数据流,有两种常见的WaterMark引入方法:周期性和间断性。
在这里要注意过时的AssignerWithPeriodicWatermarks 、AssignerWithPunctuatedWatermarks,在
WatermarkStrategy, TimestampAssigner, WatermarkGenerator之前,我们经常使用上面的两个api来写周期性和间断性的WaterMark,但在这边我们的示例使用的是flink1.3,所以使用的是新的方法。
2.2.1、With Periodic(周期性的) Watermark
周期性地生成 Watermark,默认是 100ms。每隔 N 毫秒自动向流里注入一个 Watermark,时间间隔由 streamEnv.getConfig.setAutoWatermarkInterval()决定。
示例一:使用周期性的WaterMark
需求:对socket中无序数据流,进行每5s处理一次,数据中会有延迟
代码:
import org.apache.flink.api.common.eventtime.{SerializableTimestampAssigner, Watermark, WatermarkGenerator, WatermarkGeneratorSupplier, WatermarkOutput, WatermarkStrategy}
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindowsimport scala.math.max
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector//对无序的数据流周期性的添加水印
object StreamOutOfOrderPeriodicWaterMark {def main(args: Array[String]): Unit = {val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironmentimport org.apache.flink.api.scala._environment.setParallelism(1)val sourceStream: DataStream[String] = environment.socketTextStream("companynode01",19999)val mapStream: DataStream[(String, Long)] = sourceStream.map(x => (x.split(",")(0), x.split(",")(1).toLong))//添加水位线mapStream.assignTimestampsAndWatermarks(//重写WatermarkStrategy的策略,使用BoundedOutOfOrdernessGeneratornew WatermarkStrategy[(String, Long)] {override def createWatermarkGenerator(context: WatermarkGeneratorSupplier.Context): WatermarkGenerator[(String, Long)] = {new BoundedOutOfOrdernessGenerator}//指定eventime}.withTimestampAssigner(new SerializableTimestampAssigner[(String, Long)] {override def extractTimestamp(t: (String, Long), l: Long): Long = {t._2}})).keyBy(_._1).window(TumblingEventTimeWindows.of(Time.seconds(5)))//窗口数据的处理.process(new ProcessWindowFunction[(String, Long), (String,Long), String, TimeWindow] {override def process(key: String, context: Context, elements: Iterable[(String, Long)], out: Collector[(String, Long)]): Unit = {//窗口的开始时间val startTime: Long = context.window.getStart//窗口的结束时间val startEnd: Long = context.window.getEnd//获取当前的 watermarkval watermark: Long = context.currentWatermarkvar sum:Long = 0val toList: List[(String, Long)] = elements.toListfor(eachElement <- toList){sum +=1}println("窗口的数据条数:"+sum+" |窗口的第一条数据:"+toList.head+" |窗口的最后一条数据:"+toList.last+" |窗口的开始时间: "+ startTime +" |窗口的结束时间: "+ startEnd+" |当前的watermark:"+watermark)out.collect((key, sum))}}).print()//启动任务environment.execute()}
}class BoundedOutOfOrdernessGenerator extends WatermarkGenerator[(String, Long)] {val maxOutOfOrderness = 5000L var currentMaxTimestamp: Long = _override def onEvent(element: (String, Long), eventTimestamp: Long, output: WatermarkOutput): Unit = {currentMaxTimestamp = max(eventTimestamp, currentMaxTimestamp)}override def onPeriodicEmit(output: WatermarkOutput): Unit = {// emit the watermark as current highest timestamp minus the out-of-orderness boundoutput.emitWatermark(new Watermark(currentMaxTimestamp - maxOutOfOrderness - 1));}
}输入:
000001,1650006862000
000001,1650006866000
000001,1650006872000
000002,1650006867000
000002,1650006868000
000002,1650006875000
000001,1650006875000
结果:

2.2.2、With Punctuated(间断性的)Watermark
间断性的生成 Watermark ,一般是基于某些事件触发 Watermark 的生成和发送。比如说只给用户id为000001的添加watermark,其他的用户就不添加。
示例二:使用间断性的WaterMark
需求:对socket中无序数据流,进行每5s处理一次,数据中会有延迟
代码:
import org.apache.flink.api.common.eventtime.{SerializableTimestampAssigner, Watermark, WatermarkGenerator, WatermarkGeneratorSupplier, WatermarkOutput, WatermarkStrategy}
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collectorimport scala.math.max//对无序的数据流间断性的添加水印
object StreamOutOfOrderPunctuatedWaterMark {def main(args: Array[String]): Unit = {val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironmentimport org.apache.flink.api.scala._environment.setParallelism(1)val sourceStream: DataStream[String] = environment.socketTextStream("companynode01",19999)val mapStream: DataStream[(String, Long)] = sourceStream.map(x=>(x.split(",")(0), x.split(",")(1).toLong))//添加水位线mapStream.assignTimestampsAndWatermarks(new WatermarkStrategy[(String, Long)] {override def createWatermarkGenerator(context: WatermarkGeneratorSupplier.Context): WatermarkGenerator[(String, Long)] = {new PunctuatedAssigner}}.withTimestampAssigner(new SerializableTimestampAssigner[(String, Long)] {override def extractTimestamp(t: (String, Long), l: Long): Long = {t._2}})).keyBy(_._1).window(TumblingEventTimeWindows.of(Time.seconds(5))).process(new ProcessWindowFunction[(String, Long), (String,Long), String, TimeWindow] {override def process(key: String, context: Context, elements: Iterable[(String, Long)], out: Collector[(String, Long)]): Unit = {//窗口的开始时间val startTime: Long = context.window.getStart//窗口的结束时间val startEnd: Long = context.window.getEnd//获取当前的 watermarkval watermark: Long = context.currentWatermarkvar sum:Long = 0val toList: List[(String, Long)] = elements.toListfor(eachElement <- toList){sum +=1}println("窗口的数据条数:"+sum+" |窗口的第一条数据:"+toList.head+" |窗口的最后一条数据:"+toList.last+" |窗口的开始时间: "+startTime +" |窗口的结束时间: "+startEnd+" |当前的watermark:"+watermark)out.collect((key, sum))}}).print()environment.execute()}}//使用间断性wartmark
class PunctuatedAssigner extends WatermarkGenerator[(String, Long)] {//定义数据乱序的最大时间val maxOutOfOrderness=5000L//最大事件发生时间var currentMaxTimestamp:Long=_override def onEvent(lastElement: (String, Long), extractedTimestamp: Long, output: WatermarkOutput): Unit = {currentMaxTimestamp = max(extractedTimestamp, currentMaxTimestamp)//当用户id为000001生成watermarkif (lastElement._1.equals("000001")) {val watermark = new Watermark(currentMaxTimestamp - maxOutOfOrderness)output.emitWatermark(watermark)}}override def onPeriodicEmit(watermarkOutput: WatermarkOutput): Unit = {}
}
socket发送数据
000001,1650006862000
000001,1650006866000
000001,1650006872000
000002,1650006867000
000002,1650006868000
000002,1650006875000
000001,1650006875000
结果图:

2.3、多并行度数据流中的 Watermark
对应并行度大于1的source task,它每个独立的subtask都会生成各自的watermark。这些watermark会随着流数据一起分发到下游算子,并覆盖掉之前的watermark。当有多个watermark同时到达下游算子的时候,flink会选择较小的watermark进行更新。当一个task的watermark大于窗口结束时间时,就会立马触发窗口操作。
在多并行度的情况下,Watermark 会有一个对齐机制,这个对齐机制会取所有 Channel 中最小的 Watermark。
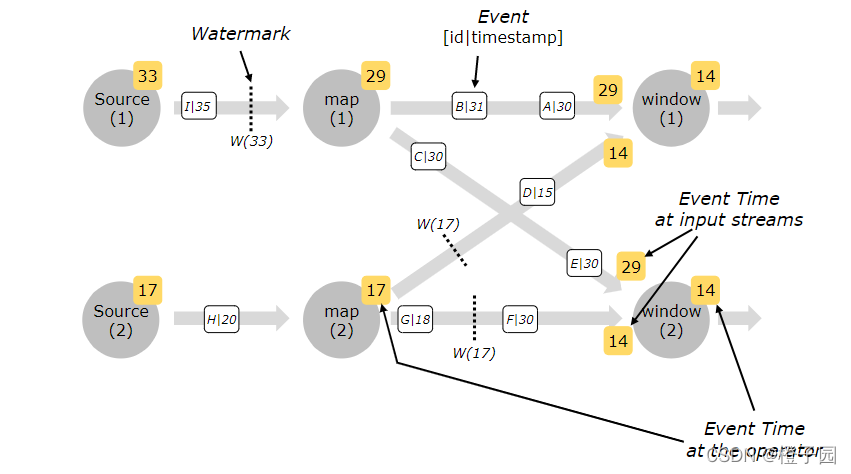
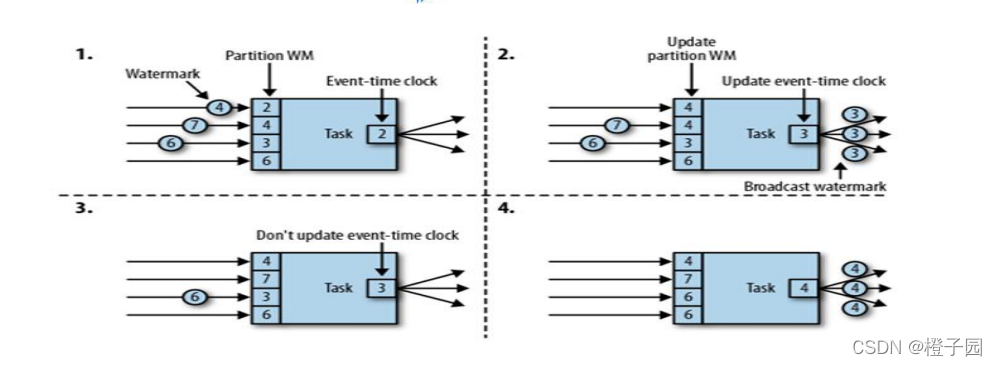
本地测试的过程中,如果不设置并行度的话,默认读取本机CPU数量设置并行度,可以手动设置并行度environment.setParallelism(1),每一个线程都会有一个watermark.
多并行度的情况下,一个window可能会接受到多个不同线程waterMark。
watermark对齐会取所有channel最小的watermark,以最小的watermark为准。
示例
需求:对socket中无序数据流,使用多并行度,进行每5s处理一次,数据中会有延迟
代码:
import org.apache.flink.api.common.eventtime.{SerializableTimestampAssigner, Watermark, WatermarkGenerator, WatermarkGeneratorSupplier, WatermarkOutput, WatermarkStrategy}
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collectorimport scala.math._/*** 测试多并行度下的watermark*/
object WaterMarkWindowWithMultipart {def main(args: Array[String]): Unit = {val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironmentimport org.apache.flink.api.scala._environment.setParallelism(2)val sourceStream: DataStream[String] = environment.socketTextStream("companynode01",19999)val mapStream: DataStream[(String, Long)] = sourceStream.map(x=>(x.split(",")(0), x.split(",")(1).toLong))//周期性生成水位线mapStream.assignTimestampsAndWatermarks(new WatermarkStrategy[(String, Long)] {override def createWatermarkGenerator(context: WatermarkGeneratorSupplier.Context): WatermarkGenerator[(String, Long)] = {new MultiBoundedOutOfOrdernessGenerator}}.withTimestampAssigner(new SerializableTimestampAssigner[(String, Long)] {override def extractTimestamp(t: (String, Long), l: Long): Long = {t._2}})).keyBy(_._1).window(TumblingEventTimeWindows.of(Time.seconds(5))).process(new ProcessWindowFunction[(String, Long), (String,Long), String, TimeWindow] {override def process(key: String, context: Context, elements: Iterable[(String, Long)], out: Collector[(String, Long)]): Unit = {//窗口的开始时间val startTime: Long = context.window.getStart//窗口的结束时间val startEnd: Long = context.window.getEnd//获取当前的 watermarkval watermark: Long = context.currentWatermarkvar sum: Long = 0val toList: List[(String, Long)] = elements.toListfor (eachElement <- toList) {sum += 1}println("窗口的数据条数:" + sum +" |窗口的第一条数据:" + toList.head +" |窗口的最后一条数据:" + toList.last +" |窗口的开始时间: " + startTime +" |窗口的结束时间: " + startEnd +" |当前的watermark:" + watermark)out.collect((key, sum))}}).print()environment.execute()}
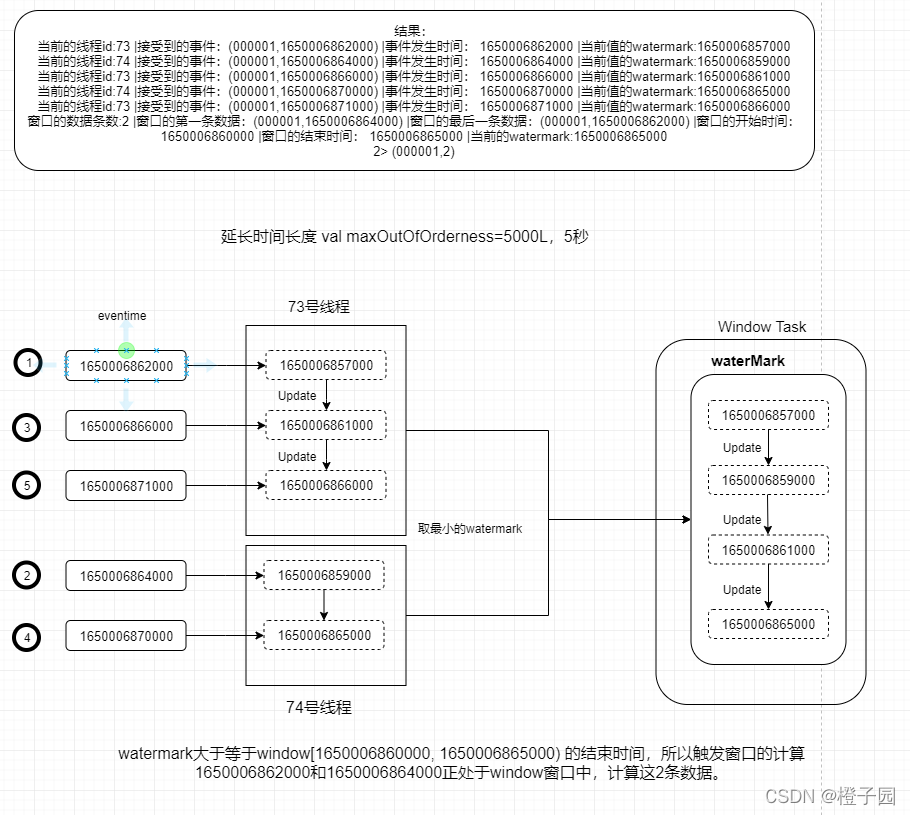
}class MultiBoundedOutOfOrdernessGenerator extends WatermarkGenerator[(String, Long)] {val maxOutOfOrderness = 5000Lvar currentMaxTimestamp: Long = _override def onEvent(element: (String, Long), eventTimestamp: Long, output: WatermarkOutput): Unit = {currentMaxTimestamp = max(eventTimestamp, currentMaxTimestamp)val id: Long = Thread.currentThread.getIdprintln("当前的线程id:" + id + " |接受到的事件:" + element + " |事件发生时间: " + currentMaxTimestamp+ " |当前值的watermark:" + new Watermark(currentMaxTimestamp - maxOutOfOrderness).getTimestamp)}override def onPeriodicEmit(output: WatermarkOutput): Unit = {// emit the watermark as current highest timestamp minus the out-of-orderness boundval waterMark = new Watermark(currentMaxTimestamp - maxOutOfOrderness)output.emitWatermark(waterMark)}
}
输入数据
000001,1650006862000
000001,1650006864000
000001,1650006866000
000001,1650006870000
000001,1650006871000
输出结果
当前的线程id:73 |接受到的事件:(000001,1650006862000) |事件发生时间: 1650006862000 |当前值的watermark:1650006857000
当前的线程id:74 |接受到的事件:(000001,1650006864000) |事件发生时间: 1650006864000 |当前值的watermark:1650006859000
当前的线程id:73 |接受到的事件:(000001,1650006866000) |事件发生时间: 1650006866000 |当前值的watermark:1650006861000
当前的线程id:74 |接受到的事件:(000001,1650006870000) |事件发生时间: 1650006870000 |当前值的watermark:1650006865000
当前的线程id:73 |接受到的事件:(000001,1650006871000) |事件发生时间: 1650006871000 |当前值的watermark:1650006866000
窗口的数据条数:2 |窗口的第一条数据:(000001,1650006864000) |窗口的最后一条数据:(000001,1650006862000) |窗口的开始时间: 1650006860000 |窗口的结束时间: 1650006865000 |当前的watermark:1650006865000
2> (000001,2)
结果分析
2.4、迟到的数据处理机制
程序中即使使用了WaterMark,还是依然会存在迟到的数据。Flink中设了三种应对方式,allowedLateness、sideOutputLateData、不做任何处理,暴力舍弃,Flink默认自动丢弃。
我们来分析一下这两个是干嘛的,当allowedLateness设置了allowedLateness(延迟time)后,此时该窗口触发计算的条件如下:
-
第一次触发条件
watermark >= window_end_time 并且该窗口需要有数据 -
其他时候触发条件
watermark < window_end_time + 延迟time 并且该窗口需要有新数据进入
结合下面的sideOutputLateData(侧输出流)可以理解为:在watermark机制下,窗口虽然到了关闭时间,但是假设你设置了 allowedLateness=5秒,那这个窗口还会在等5秒,看看是否还有其他小延迟的数据到来,有新数据进来就触发计算。当等了5秒还没等到,那么后面来的数据就是延迟太久的数据,会通过sideOutputLateData把延迟太久的数据单独收集起来,放到侧输出流中,等待后续再处理,不会放在当前窗口中计算了。
下面我们讲前两种机制,并通过一个示例讲解它们的使用。
2.4.1、allowedLateness
对于延迟一会儿的数据,设置一个允许迟到时间
//例如
assignTimestampsAndWatermarks(new EventTimeExtractor() ).keyBy(_._1).timeWindow(Time.seconds(3)).allowedLateness(Time.seconds(2)) // 允许事件迟到2秒.process(new ProcessWindowFunction()).print().setParallelism(1);
2.4.2、sideOutputLateData
对于超过允许迟到时间的数据,通过单独的数据流全部收集起来,后续再处理
//例如
assignTimestampsAndWatermarks(new EventTimeExtractor() ).keyBy(_._1).timeWindow(Time.seconds(3)).allowedLateness(Time.seconds(2)) //允许事件迟到2秒.sideOutputLateData(outputTag) //收集迟到太多的数据.process(new ProcessWindowFunction()).print().setParallelism(1);
示例:使用allowedLateness和sideOutputLateData对迟到数据进行处理
需求:对socket中无序数据流,进行每5s处理一次,数据中会有延迟,对迟到的数据延迟2s,然后使用侧输出流将还是迟到的数据全部收集起来。
代码:
import java.time.Duration
import org.apache.flink.api.common.eventtime.{SerializableTimestampAssigner, WatermarkStrategy}
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.streaming.api.scala.{DataStream, OutputTag, StreamExecutionEnvironment}
import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector//允许延迟一段时间,并且对延迟太久的数据单独进行收集
object AllowedLatenessTest {def main(args: Array[String]): Unit = {val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironmentimport org.apache.flink.api.scala._environment.setParallelism(1)val sourceStream: DataStream[String] = environment.socketTextStream("companynode01",19999)val mapStream: DataStream[(String, Long)] = sourceStream.map(x=>(x.split(",")(0), x.split(",")(1).toLong))//定义一个侧输出流的标签,用于收集迟到太多的数据val lateTag=new OutputTag[(String, Long)]("late")//添加周期水位线val result: DataStream[(String, Long)] = mapStream.assignTimestampsAndWatermarks(//使用内置的静态WatermarkStrategy来快速指定一个waterMarkWatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(5)).withTimestampAssigner(new SerializableTimestampAssigner[(String, Long)] {override def extractTimestamp(element: (String, Long), recordTimestamp: Long): Long = {element._2}})).keyBy(_._1).window(TumblingEventTimeWindows.of(Time.seconds(5))).allowedLateness(Time.seconds(2)) //允许数据延迟2s.sideOutputLateData(lateTag) //收集延迟大多的数据.process(new ProcessWindowFunction[(String, Long), (String, Long), String, TimeWindow] {override def process(key: String, context: Context, elements: Iterable[(String, Long)], out: Collector[(String, Long)]): Unit = {//窗口的开始时间val startTime: Long = context.window.getStart//窗口的结束时间val startEnd: Long = context.window.getEnd//获取当前的 watermarkval watermark: Long = context.currentWatermarkvar sum: Long = 0val toList: List[(String, Long)] = elements.toListfor (eachElement <- toList) {sum += 1}println("窗口的数据条数:" + sum +" |窗口的第一条数据:" + toList.head +" |窗口的最后一条数据:" + toList.last +" |窗口的开始时间: " + startTime +" |窗口的结束时间: " + startEnd +" |当前的watermark:" + watermark)out.collect((key, sum))}})//打印延迟太多的数据 侧输出流:主要的作用用于保存延迟太久的数据result.getSideOutput(lateTag).print("late")//打印正常的数据result.print("ok")environment.execute()}}
发送数据
000001,1650006862000
000001,1650006866000
000001,1650006868000
000001,1650006869000
000001,1650006870000
000001,1650006862000
000001,1650006871000
000001,1650006872000
000001,1650006862000
000001,1650006863000
结果: