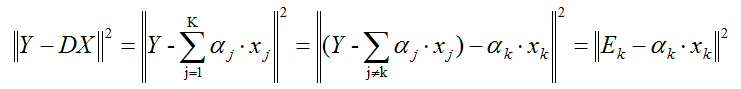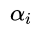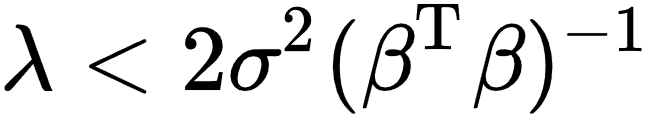文章目录
- 一、字典学习数学模型
- 1.1、数学描述
- 1.2、求解问题
- 1.3、字典学习算法实现
- 字典学习也是一种数据降维的方法,这里我用到SVD的知识,对SVD不太理解的地方,可以看看这篇博客: 奇异值分解SVD
一、字典学习数学模型
字典学习的思想应该源来实际生活中的字典的概念。字典是前辈们学习总结的精华,当我们需要学习新的知识的时候,不必与先辈们一样去学习先辈们所有学习过的知识,我们可以参考先辈们给我们总结的字典,通过查阅这些字典,我们可以大致学会到这些知识。为了将上述过程用准确的数学语言描述出来,我们需要将“总结字典”、“查阅字典”做出一个更为准确的描述。就从我们的常识出发:
- 1.我们通常会要求的我们的字典尽可能全面,也就是说总结出的字典不能漏下关键的知识点。
- 2.查字典的时候,我们想要我们查字典的过程尽可能简洁,迅速,准确。即,查字典要快、准、狠。
- 3.查到的结果,要尽可能地还原出原来知识。当然,如果要完全还原出来,那么这个字典和查字典的方法会变得非常复杂,所以我们只需要尽可能地还原出原知识点即可。
下面,我们要讨论的就是如何将上述问题抽象成一个数学问题,并解决这个问题。
1.1、数学描述
我们将上面的所提到的关键点用几个数学符号表示一下:
- “以前的知识”,更专业一点,我们称之为原始样本,用矩阵 Y \mathbf{Y} Y表示;
- “字典”,我们称之为字典矩阵,用 D \mathbf{D} D表示,“字典”中的词条,我们称之为原子(atom),用列向量 d k \mathbf{d_{k}} dk 表示;
- “查字典的方法”,我们称为稀疏矩阵,用 X \mathbf{X} X;
- “查字典的过程”,我们可以用矩阵的乘法来表示,即 D X \mathbf{DX} DX。
- 用数学语言描述,字典学习的主要思想是,利用包含 K K K 个原子 d k \mathbf{d_{k}} dk的字典矩阵 D ∈ R m × K \mathbf{D} \in \mathbf{R}^{m \times K} D∈Rm×K,稀疏线性表示原始样本 Y ∈ R m × n \mathbf{Y} \in \mathbf{R}^{m \times n} Y∈Rm×n(其中 n n n 表示样本数, m m m 表示样本的属性),即有 Y = D X \mathbf{Y=DX} Y=DX(这只是我们理想的情况),其中 X ∈ R K × n \mathbf{X} \in \mathbf{R}^{K \times n} X∈RK×n为稀疏矩阵,可以将上述问题用数学语言描述为如下优化问题:
min D , X ∥ Y − D X ∥ F 2 , s.t. ∀ i , ∥ x i ∥ 0 ≤ T 0 (1-1) \min_{\mathbf{D,\ X}}{\|\mathbf{Y}-\mathbf{DX}\|^2_F},\quad \text{s.t.}\ \forall i,\ \|\mathbf{x}_i\|_0 \le T_0 \tag{1-1} D, Xmin∥Y−DX∥F2,s.t. ∀i, ∥xi∥0≤T0(1-1)- 或者
min D , X ∑ i ∥ x i ∥ 0 , s.t. min D , X ∥ Y − D X ∥ F 2 ≤ ϵ , (1-2) \min_{\mathbf{D,\ X}}\sum_i\|\mathbf{x}_i\|_0, \quad \text{s.t.}\ \min_{\mathbf{D,\ X}}{\|\mathbf{Y}-\mathbf{DX}\|^2_F} \le \epsilon, \tag{1-2} D, Xmini∑∥xi∥0,s.t. D, Xmin∥Y−DX∥F2≤ϵ,(1-2)- 上式中 X \mathbf{X} X 为稀疏编码的矩阵, x i ( i = 1 , 2 , ⋯ , K ) \mathbf{x}_i\,\ (i=1,2,\cdots,K) xi (i=1,2,⋯,K),为该矩阵中的行向量,代表字典矩阵的系数。
- 注意: ∥ x i ∥ 0 ∥\mathbf{x_{i}}∥_{0} ∥xi∥0表示零阶范数,它表示向量中不为0的数的个数。即是想让其尽可能的稀疏,非0的元素尽可能的少。
1.2、求解问题
- 式(1-1)的目标函数表示,我们要最小化查完的字典与原始样本的误差,即要尽可能还原出原始样本;它的限的制条件 ∥ x i ∥ 0 ≤ T 0 \|\mathbf{x}_i\|_0 \le T_0 ∥xi∥0≤T0,,表示查字典的方式要尽可能简单,即 X X X要尽可能稀疏。式(1-2)同理。式(1-1)或式(1-2)是一个带有约束的优化问题,可以利用拉格朗日乘子法将其转化为无约束优化问题
min D , X ∥ Y − D X ∥ F 2 + λ ∥ x i ∥ 1 (1-3) \min_{\mathbf{D,\ X}}{\|\mathbf{Y}-\mathbf{DX}\|^2_F}+\lambda\|\mathbf{x}_i\|_1 \tag{1-3} D, Xmin∥Y−DX∥F2+λ∥xi∥1(1-3)- 注意: ∥ x i ∥ 0 ∥\mathbf{x_{i}}∥_{0} ∥xi∥0表示零阶范数 我们将 ∥ x i ∥ 0 ∥\mathbf{x_{i}}∥_{0} ∥xi∥0用 ∥ x i ∥ 1 ∥\mathbf{x_{i}}∥_{1} ∥xi∥1代替,主要是 ∥ x i ∥ 1 ∥\mathbf{x_{i}}∥_{1} ∥xi∥1更加便于求解。
- 这里有两个优化变量 D , X \mathbf{D,\ X} D, X,为解决这个优化问题,一般是固定其中一个优化变量,优化另一个变量,如此交替进行。式(1-3)中的稀疏矩阵 X \mathbf{X} X可以利用已有经典算法求解,如Lasso(Least Absolute Shrinkage and Selection Operator)、OMP(Orthogonal Matching Pursuit),这里我重点讲述如何更新字典 D \mathbf{D} D,对更新 X \mathbf{ X} X不多做讨论。
- 假设 X \mathbf{ X} X是已知的,我们逐列更新字典。下面我们仅更新字典的第 k k k列,记 d k \mathbf{d_{k}} dk 为字典 D \mathbf{D} D的第 k k k列向量,记 x T k \mathbf{x}^k_T xTk 为稀疏矩阵 X \mathbf{X} X的第 k k k 行向量,那么对式(1-1),我们有:
∥ Y − D X ∥ F 2 = ∥ Y − ∑ j = 1 K d j x T j ∥ F 2 = ∥ ( Y − ∑ j ≠ k d j x T j ) − d k x T k ∥ F 2 = ∥ E k − d k x T k ∥ F 2 (1-4) \begin{aligned} {\|\mathbf{Y}-\mathbf{DX}\|^2_F} =&\left\|\mathbf{Y}-\sum^K_{j=1}\mathbf{d}_j\mathbf{x}^j_T\right\|^2_F \\ =&\left\|\left(\mathbf{Y}-\sum_{j\ne k}\mathbf{d}_j\mathbf{x}^j_T\right)-\mathbf{d}_k\mathbf{x}^k_T\right\|^2_F\\ =&\left\|\mathbf{E}_k - \mathbf{d}_k\mathbf{x}_T^k \right\|^2_F \end{aligned} \tag{1-4} ∥Y−DX∥F2===∥∥∥∥∥Y−j=1∑KdjxTj∥∥∥∥∥F2∥∥∥∥∥∥⎝⎛Y−j=k∑djxTj⎠⎞−dkxTk∥∥∥∥∥∥F2∥∥Ek−dkxTk∥∥F2(1-4)- 上式中残差: E k = Y − ∑ j ≠ k d j x T j (1-5) \mathbf{E}_k=\mathbf{Y}-\sum_{j\ne k}\mathbf{d}_j\mathbf{x}^j_T\tag{1-5} Ek=Y−j=k∑djxTj(1-5)
- 此时优化问题可描述为: min d k , x T k ∥ E k − d k x T k ∥ F 2 (1-6) \min_{\mathbf{d}_k,\ \mathbf{x}^k_T}\left\|\mathbf{E}_k - \mathbf{d}_k\mathbf{x}_T^k \right\|^2_F\tag{1-6} dk, xTkmin∥∥Ek−dkxTk∥∥F2(1-6)
- 因此我们需要求出最优的 d k , x T k \mathbf{d}_k,\ \mathbf{x}_T^k dk, xTk,这是一个最小二乘问题,可以利用最小二乘的方法求解,或者可以利用SVD进行求解,这里利用SVD的方式求解出两个优化变量。
- 但是,在这里我人需要注意的是,不能直接利用 E k \mathbf{E}_k Ek 进行求解,否则求得的新的 x T k \mathbf{x}^k_T xTk 不稀疏。因此我们需要将 E k \mathbf{E}_k Ek中对应的 x T k \mathbf{x}^k_T xTk不为0的位置提取出来,得到新的 E k ′ \mathbf{E}_k^{'} Ek′,这个过程如图2-1所示,这样描述更加清晰。
- 如上图,假设我们要更新第0列原子,我们将 x T k \mathbf{x}_T^k xTk中为零的位置找出来,然后把 E k \mathbf{E}_k Ek对应的位置删除,得到 E k ′ \mathbf{E}_k^{'} Ek′,此时优化问题可描述为:
min d k , x T k ∥ E k ′ − d k x ′ T k ∥ F 2 (1-7) \min_{\mathbf{d}_k,\ \mathbf{x}^k_T}\left\|\mathbf{E}_k^{'} - \mathbf{d}_k\mathbf{x{'}}_T^{k} \right\|^2_F \tag{1-7} dk, xTkmin∥∥∥Ek′−dkx′Tk∥∥∥F2(1-7)- 因此我们需要求出最优的 d k , x ′ T k \mathbf{d}_k,\ \mathbf{x^{'}}_T^k dk, x′Tk:
E k ′ = U Σ V T (1-8) \mathbf{E}_k^{'}=\mathbf U\mathbf \Sigma \mathbf V^T \tag{1-8} Ek′=UΣVT(1-8)- 取左奇异矩阵 U \mathbf U U 的第1个列向量 u 1 = U ( ⋅ , 1 ) \mathbf{u}_1=U(\cdot,1) u1=U(⋅,1)作为 d k = u 1 \mathbf{d}_k=\mathbf{u}_1 dk=u1,即 d k \mathbf{d}_k dk,取右奇异矩阵的第1个行向量与第1个奇异值的乘积作为 x ′ T k \mathbf{x{'}}_T^k x′Tk,即 x ′ T k = Σ ( 1 , 1 ) V T ( 1 , ⋅ ) \mathbf{x{'}}^k_T=\mathbf \Sigma(1,1)\mathbf V^T(1,\cdot) x′Tk=Σ(1,1)VT(1,⋅)。得到 x ′ T k \mathbf{x{'}}^k_T x′Tk后,将其对应地更新到原 x T k \mathbf{x}_T^k xTk。
- 注意:式(1-8)所求得的奇异值矩阵 Σ \bf Σ Σ 中的奇异值应从大到小排列;同样也有 x ′ T k = Σ ( 1 , 1 ) V ( ⋅ , 1 ) T \mathbf{x{'}}^k_T=\mathbf \Sigma(1,1)\mathbf V(\cdot,1)^T x′Tk=Σ(1,1)V(⋅,1)T,这与上面x′kT的求法是相等的。

1.3、字典学习算法实现
利用1.2小节稀疏算法求解得到稀疏矩阵 X \mathbf{X} X后,逐列更新字典,有如下算法1.1。
| 算法 | 字典学习(K-SVD) |
|---|---|
| 输入 | 原始样本,字典,稀疏矩阵 |
| 输出 | 字典,稀疏矩阵 |
| 1 初始化 | 从原始样本 Y ∈ R m × n Y \in \mathbf{R}^{m \times n} Y∈Rm×n随机取 K K K个列向量或者取它的左奇异矩阵的前 K K K个列向量 { d 1 , d 2 , ⋯ , d K } \{\mathbf{d}_1,\mathbf{d}_2,\cdots,\mathbf{d}_K\} {d1,d2,⋯,dK}作为初始字典的原子,得到字典 D ( 0 ) ∈ R m × K \mathbf{D}^{(0)} \in \mathbf{R}^{m \times K} D(0)∈Rm×K。令 j = 0 j=0 j=0, 重复下面步骤1-3,直到达到指定的迭代步数,或收敛到指定的误差: |
| 2 稀疏编码 | 利用字典上一步得到的字典 D ( j ) \mathbf{D}^{(j)} D(j),稀疏编码,得到 X ( j ) ∈ R K × n \mathbf{X}^{(j)}\in\mathbf{R}^{K \times n} X(j)∈RK×n。 |
| 3 字典更新 | 逐列更新字典 D ( j ) \mathbf{D}^{(j)} D(j),字典的列 d k ∈ { d 1 , d 2 , ⋯ , d K } \mathbf{d}_k \in \{\mathbf{d}_1,\mathbf{d}_2,\cdots,\mathbf{d}_K\} dk∈{d1,d2,⋯,dK} |
| 3.1 | 当更新 d k \mathbf{d}_k dk时,计算误差矩阵 E k \mathbf{E}_k Ek: E k = Y − ∑ j ≠ k d j x T j . \mathbf{E}_k=\mathbf{Y}-\sum_{j\ne k}\mathbf{d}_j\mathbf{x}^j_T. Ek=Y−∑j=kdjxTj. |
| 3.2 | 取出稀疏矩阵第 k k k个行向量 x T k \mathbf{x}^k_T xTk不为0的索引的集合 ω k = { i 1 ≤ i ≤ n , x T k ( i ) ≠ 0 } \omega_{k}=\left\{i 1 \leq i \leq n, \mathbf{x}_{T}^{k}(i) \neq 0\right\} ωk={i1≤i≤n,xTk(i)=0} 还有以下的这个: x ′ T k = { x T k ( i ) 1 ≤ i ≤ n , x T k ( i ) ≠ 0 } \mathbf{x'}_T^{k} = \{\mathbf{x}_T^k(i)1\le i\le n,\ \mathbf{x}_T^k(i) \ne 0\} x′Tk={xTk(i)1≤i≤n, xTk(i)=0} |
| 3.3 | 从 E k \mathbf{E}_k Ek取出对应 ω k \omega_k ωk不为0的列,得到 E k ′ \mathbf{E}_k^{'} Ek′, |
| 3.4 | 对 E k ′ \mathbf{E}_k^{'} Ek′作奇异值分解 E k = U Σ V T ; \mathbf{E}_k=\mathbf U\mathbf \Sigma \mathbf V^T; Ek=UΣVT;取 U U U的第1列更新字典的第 k k k列,即 d k = U ( ⋅ , 1 ) \mathbf{d}_k=\mathbf U(\cdot,1) dk=U(⋅,1), 令: x ′ T k = Σ ( 1 , 1 ) V ( ⋅ , 1 ) T \mathbf{x'}^k_T=\mathbf \Sigma(1,1)\mathbf V(\cdot,1)^T x′Tk=Σ(1,1)V(⋅,1)T;得到 x ′ T k \mathbf{x'}^k_T x′Tk后,将其对应地更新到原 x T k \mathbf{x}_T^k xTk。 |
| 3.5 | j = j + 1 j=j+1 j=j+1 |
最后感谢作者:
- https://www.cnblogs.com/endlesscoding/p/10090866.html