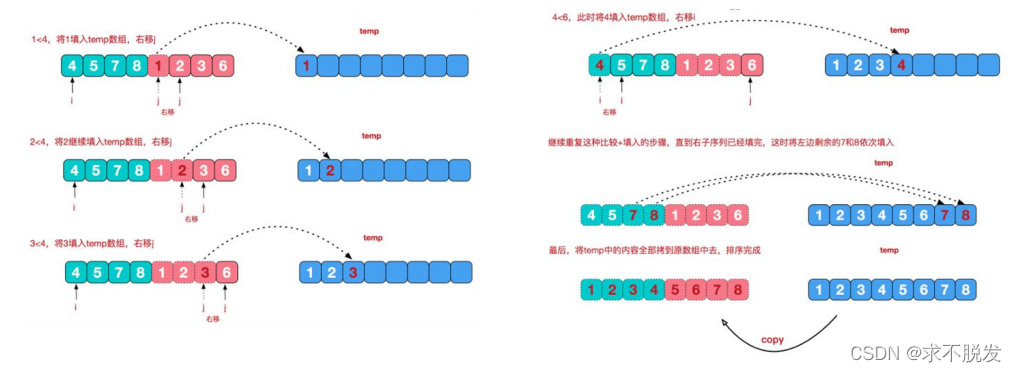
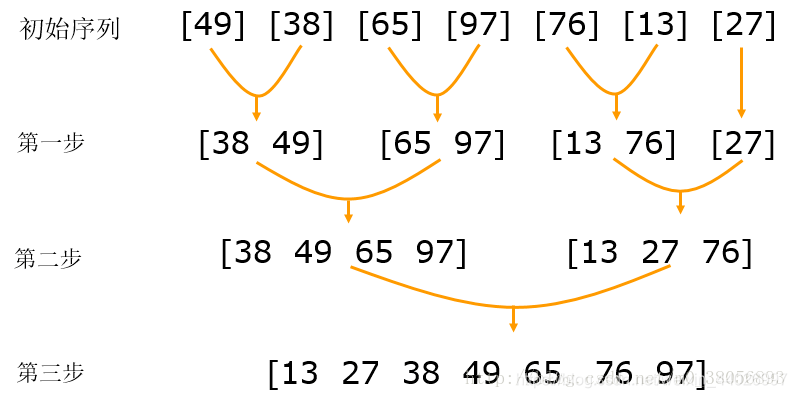
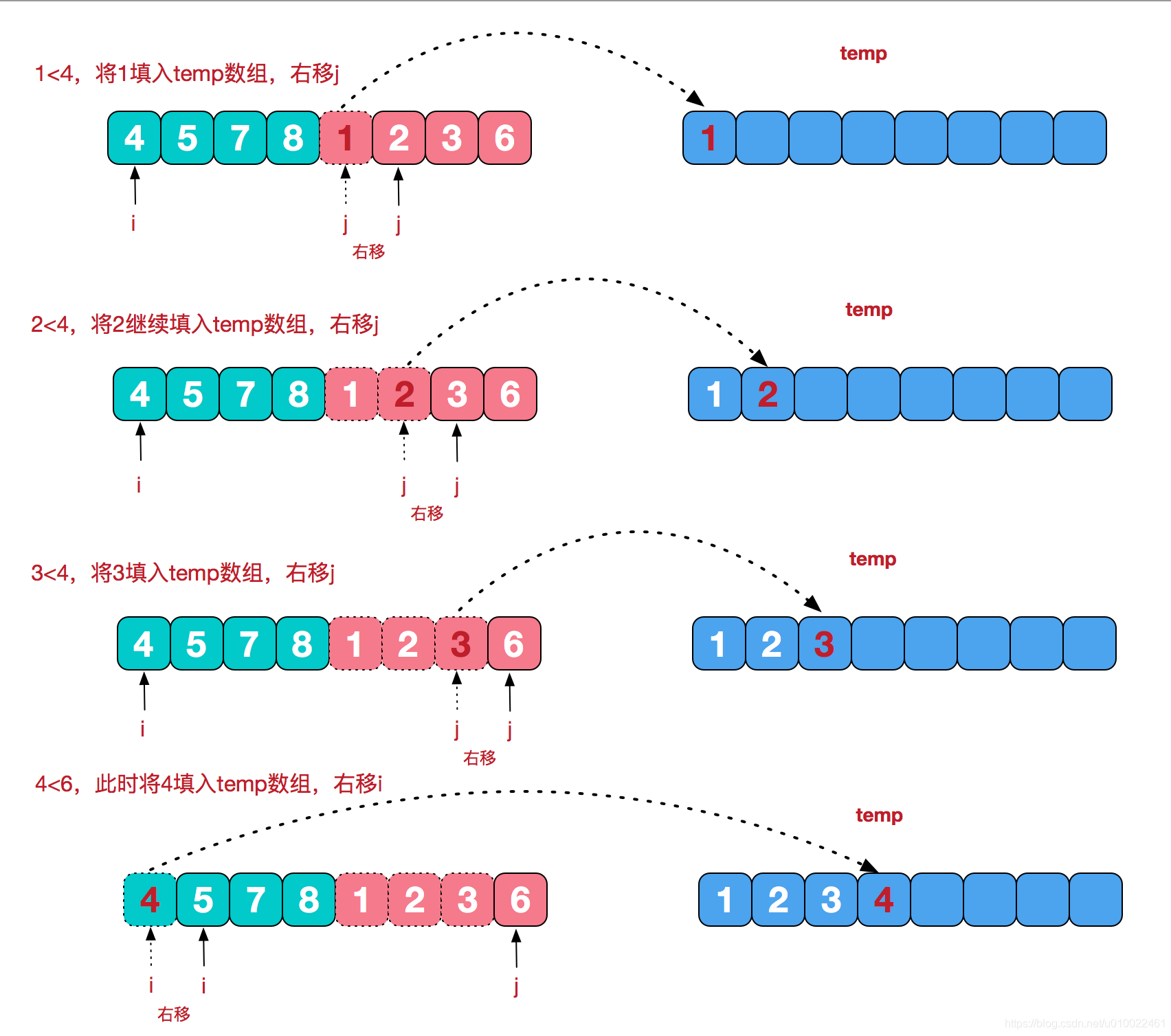
归并排序,是一种分治算法。利用递归,将一个大的数据集合分解成小的子集合。将子集合排好序后,再合并起来。归并排序不是原地排序算法,因为它使用到了临时空间,这也是归并排序没有快速排序应用广泛的主要原因,虽然归并排序的时间复杂度,最好、最坏都是O(logn)。但是,这个也看使用场景,如果在空间换时间的场合,个人认为这种算法也有一定的用武之处。
我在网上找了一个动图,很直观。大家可以看一下。来源:https://www.cnblogs.com/fivestudy/p/10064969.html

下面看一下java的代码实现
public static void main(String[] args) {int[] arr = new int[]{10, 7, 8, 9, 1, 5};mergeSort(arr, arr.length);System.out.println(Arrays.toString(arr));}private static void mergeSort(int[] arr, int n) {mergeSortInternally(arr, 0, n - 1);}private static void mergeSortInternally(int[] arr, int p, int r) {if (p >= r) {return;}//find middle pointint q = p + (r - p) / 2;//递归分解数组元素下标,处理前半部分mergeSortInternally(arr, p, q);//处理后半部分mergeSortInternally(arr, q + 1, r);mergeBySentry(arr, p, q, r);}/*** 普通的合并算法*/private static void merge(int[] arr, int p, int q, int r) {//左半个数组的开始下标int i = p;//右半个数组的开始下标int j = q + 1;//临时数组的起始下标int k = 0;//初始化一个和当前分裂好的数组相同大小的临时数组int[] temp = new int[r - p + 1];while (i <= q && j <= r) {//比较左右两个数组的起始值,较小的元素放在临时数组的第一个位置if (arr[i] <= arr[j]) {temp[k++] = arr[i++];} else {temp[k++] = arr[j++];}}//分裂好的两个数组,很可能不是平均分配,所以可能会有一个数组先遍历完成,//另外一个数组还有未进行比较数据,此时直接将未进行比较的数组的数据添加到临时数组即可//初始化下标,先将下标初始化为左半部分的数组int start = i;int end = q;//说明右半部分未比较完,此时将下标再重置为右半部分的数组if (j <= r) {start = j;end = r;}//将未比较完的有序数组直接添加到临时数组中while (start <= end) {temp[k++] = arr[start++];}//将临时数组的数据拷贝到原数组中for (i = 0; i <= r - p; i++) {arr[p + i] = temp[i];}}/*** 添加了哨兵节点的合并算法** @param arr* @param p* @param q* @param r*/private static void mergeBySentry(int[] arr, int p, int q, int r) {//初始化左边数组对应的临时空间,增加一个哨兵节点的位置int[] leftArr = new int[q - p + 2];//初始化右边数组对应的临时空间,增加一个哨兵节点的位置int[] rightArr = new int[r - q + 1];//将原数组中,左边的数据拷贝到临时数组中for (int i = 0; i <= q - p; i++) {leftArr[i] = arr[p + i];}//左边数组增加哨兵节点leftArr[q - p + 1] = Integer.MAX_VALUE;//将原数组中,右边的数据拷贝到临时数组中for (int i = 0; i < r - q; i++) {rightArr[i] = arr[q + 1 + i];}//右边数组增加哨兵节点rightArr[r - q] = Integer.MAX_VALUE;int i = 0;int j = 0;int k = p;while (k <= r) {//左节点小于右节点时,将排好序的临时空间数据加入到原数组中,当i到达哨兵节点时,i不再增加,只增加j即可.if (leftArr[i] <= rightArr[j]) {arr[k++] = leftArr[i++];} else {arr[k++] = rightArr[j++];}}}
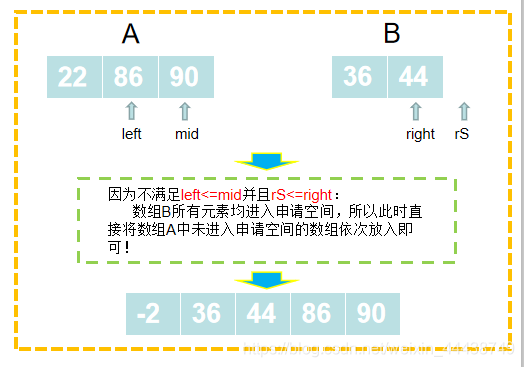
这里面的关键点是合并函数的实现逻辑,我贴出了2种合并函数的实现。
一种是:原始的合并实现,方法名是:merge
另一种是改良版本,增加了哨兵节点,方法名是:mergeBySentry。
改良版本,明显更容易理解一点。在临界值的情况,大家注意使用哨兵节点,可以让代码逻辑更清晰。
上一篇快速排序java实现,我们聊了一下快速排序的实逻辑,这2种排序经常会在一起进行比较,大家觉着这2种实现逻辑有什么区别吗?最主要的区别是:
归并排序是先将大问题拆解成小问题,然后处理小问题,最后将小问题合并。
快速排序是先处理小的排序区间,然后慢慢处理大问题。
两种排序原理截然不同
(归并排序的代码主要来自于极客时间<数据结构与算法之美>的专栏,大家对算法感兴趣的,可以订阅一下这个专栏,专栏质量很高)
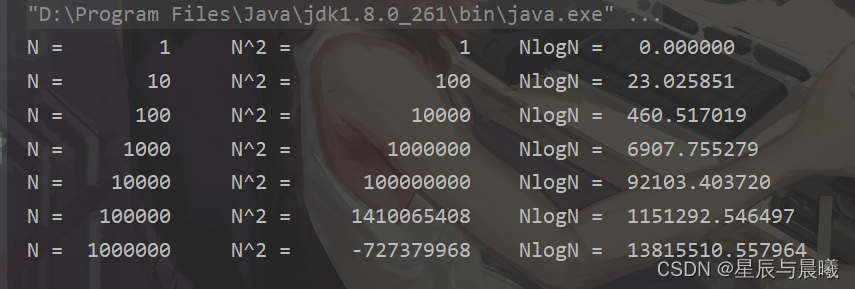
时间复杂度分析
极客的专栏里分析了这个过程,我直接抄过来,给大家看一下如何进行分析。想看全文的,可以移步专栏。
我们假设对 n 个元素进行归并排序需要的时间是 T(n),那分解成两个子数组排序的时间都是 T(n/2)。我们知道,merge() 函数合并两个有序子数组的时间复杂度是 O(n)。所以,套用前面的公式,归并排序的时间复杂度的计算公式就是:
T(1) = C; n=1时,只需要常量级的执行时间,所以表示为C。
T(n) = 2*T(n/2) + n; n>1
通过这个公式,如何来求解 T(n) 呢?还不够直观?那我们再进一步分解一下计算过程:
T(n) = 2*T(n/2) + n= 2*(2*T(n/4) + n/2) + n = 4*T(n/4) + 2*n= 4*(2*T(n/8) + n/4) + 2*n = 8*T(n/8) + 3*n= 8*(2*T(n/16) + n/8) + 3*n = 16*T(n/16) + 4*n......= 2^k * T(n/2^k) + k * n......
通过这样一步一步分解推导,我们可以得到 T(n) = 2kT(n/2k)+kn。当 T(n/2^k)=T(1) 时,也就是 n/2^k=1,我们得到 k=log2n 。我们将 k 值代入上面的公式,得到 T(n)=Cn+nlog2n 。如果我们用大 O 标记法来表示的话,T(n) 就等于 O(nlogn)。所以归并排序的时间复杂度是 O(nlogn)
空间复杂度分析
递归代码的空间复杂度并不能像时间复杂度那样累加。原因是,尽管每次合并操作都需要申请额外的内存空间,但在合并完成之后,临时开辟的内存空间就被释放掉了。在任意时刻,CPU 只会有一个函数在执行,也就只会有一个临时的内存空间在使用。临时内存空间最大也不会超过 n 个数据的大小,所以空间复杂度是 O(n)。
原地排序算法分析
很明显,归并排序的空间复杂度不是O(1),所以不是原地排序算法。
稳定排序算法分析
归并排序稳不稳定,关键要看merge函数。我们每次都让a[p,q]的元素都先进入临时数组,a[q+1,r]的元素后进入临时数组,最后的结果就是稳定的。所以,归并排序就是稳定排序算法。