前言
一、IO流与系统
IO技术在JDK中算是极其复杂的模块,其复杂的一个关键原因就是IO操作和系统内核的关联性,另外网络编程,文件管理都依赖IO技术,而且都是编程的难点,想要整体理解IO流,先从Linux操作系统开始。
Linux空间隔离
Linux使用是区分用户的,这个是基础常识,其底层也区分用户和内核两个模块:
- User space:用户空间
- Kernel space:内核空间
常识用户空间的权限相对内核空间操作权限弱很多,这就涉及到用户与内核两个模块间的交互,此时部署在服务上的应用如果需要请求系统资源,则在交互上更为复杂:

用户空间本身无法直接向系统发布调度指令,必须通过内核,对于内核中数据的操作,也是需要先拷贝到用户空间,这种隔离机制可以有效的保护系统的安全性和稳定性。
参数查看
可以通过Top命令动态查看各项数据分析,进程占用资源的状况:

us:用户空间占用CPU的百分比;sy:内核空间占用CPU的百分比;id:空闲进程占用CPU的百分比;wa:IO等待占用CPU的百分比;
对wa指标,在大规模文件任务流程里是监控的核心项之一。
IO协作流程
此时再看上面图【1】的流程,当应用端发起IO操作的请求时,请求沿着链路上的各个节点流转,有两个核心概念:
- 节点交互模式:同步与异步;
- IO数据操作:阻塞与非阻塞;
这里就是文件流中常说的:【同步/异步】IO,【阻塞/非阻塞】IO,下面看细节。
二、IO模型分析
1、同步阻塞
用户线程与内核的交互方式,应用端请求对应一个线程处理,整个过程中accept(接收)和read(读取)方法都会阻塞直至整个动作完成:

在常规CS架构模式中,这是一次IO操作的基本过程,该方式如果在高并发的场景下,客户端的请求响应会存在严重的性能问题,并且占用过多资源。
2、同步非阻塞
在同步阻塞IO的基础上进行优化,当前线程不会一直等待数据就绪直到完成复制:
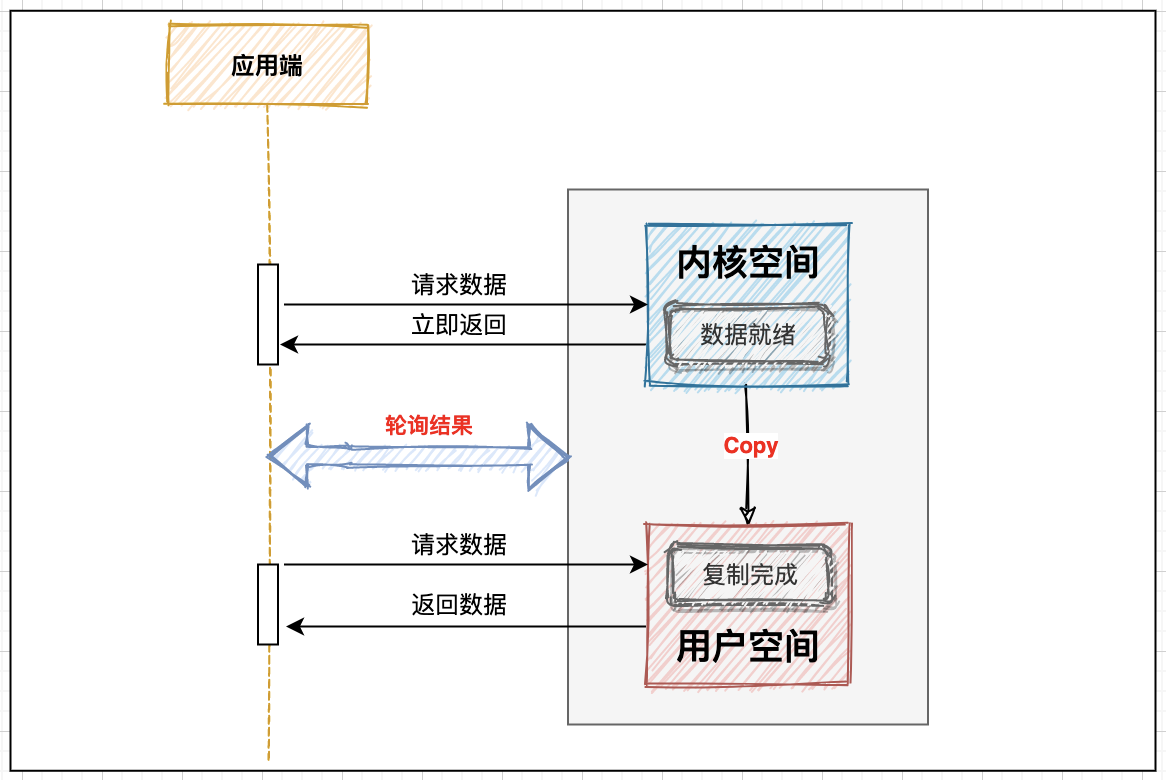
在线程请求后会立即返回,并不断轮询直至拿到数据,才会停止轮询,这种模式的缺陷也是显而易见的,如果数据准备好,在通知线程完成后续动作,这样就可以省掉很多中间交互。
3、异步通知模式
在异步模式下,彻底摒弃阻塞机制,过程分段进行交互,这与常规的第三方对接模式很相似,本地服务在请求第三方服务时,如果请求过程耗时很大,会异步执行,第三方第一次回调,确认请求可以被执行;第二次回调则是推送处理结果,这种思想在处理复杂问题时,可以很大程度的提高性能,节省资源:

异步模式对于性能的提升是巨大的,当然其相应的处理机制也更复杂,程序的迭代和优化是无止境的,在NIO模式中再次对IO流模式进行优化。
三、File文件类
1、基础描述
File类作为文件和目录路径名的抽象表示,用来获取磁盘文件的相关元数据信息,例如:文件名称、大小、修改时间、权限判断等。
注意:File并不操作文件承载的数据内容,文件内容称为数据,文件自身信息称为元数据。
public class File01 {public static void main(String[] args) throws Exception {// 1、读取指定文件File speFile = new File(IoParam.BASE_PATH+"fileio-03.text") ;if (!speFile.exists()){boolean creFlag = speFile.createNewFile() ;System.out.println("创建:"+speFile.getName()+"; 结果:"+creFlag);}// 2、读取指定位置File dirFile = new File(IoParam.BASE_PATH) ;// 判断是否目录boolean dirFlag = dirFile.isDirectory() ;if (dirFlag){File[] dirFiles = dirFile.listFiles() ;printFileArr(dirFiles);}// 3、删除指定文件if (speFile.exists()){boolean delFlag = speFile.delete() ;System.out.println("删除:"+speFile.getName()+"; 结果:"+delFlag);}}private static void printFileArr (File[] fileArr){if (fileArr != null && fileArr.length>0){for (File file : fileArr) {printFileInfo(file) ;}}}private static void printFileInfo (File file) {System.out.println("名称:"+file.getName());System.out.println("长度:"+file.length());System.out.println("路径:"+file.getPath());System.out.println("文件判断:"+file.isFile());System.out.println("目录判断:"+file.isDirectory());System.out.println("最后修改:"+new Date(file.lastModified()));System.out.println();}
}
1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.
上述案例使用了File类中的基本构造和常用方法(读取、判断、创建、删除)等,JDK源码在不断的更新迭代,通过类的构造器、方法、注释等去判断类具有的基本功能,是作为开发人员的必备能力。

在File文件类中缺乏两个关键信息描述:类型和编码,如果经常开发文件模块的需求,就知道这是两个极其复杂的点,很容易出现问题,下面站在实际开发的角度看看如何处理。
2、文件业务场景
如图所示,在常规的文件流任务中,会涉及【文件、流、数据】三种基本形式的转换:

基本过程描述:
- 源文件生成,推送文件中心;
- 通知业务使用节点获取文件;
- 业务节点进行逻辑处理;
很显然的一个问题,任何节点都无法适配所有文件处理策略,比如类型与编码,面对复杂场景下的问题,规则约束是常用的解决策略,即在约定规则之内的事情才处理。
上面流程中,源文件节点通知业务节点时的数据主体描述:
public class BizFile {/*** 文件任务批次号*/private String taskId ;/*** 是否压缩*/private Boolean zipFlag ;/*** 文件地址*/private String fileUrl ;/*** 文件类型*/private String fileType ;/*** 文件编码*/private String fileCode ;/*** 业务关联:数据库*/private String bizDataBase ;/*** 业务关联:数据表*/private String bizTableName ;
}
1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.
把整个过程当做一个任务进行封装,即:任务批次、文件信息、业务库表路由等,当然这些信息也可以直接标记在文件命名的策略上,处理的手段类似:
/*** 基于约定策略读取信息*/
public class File02 {public static void main(String[] args) {BizFile bizFile = new BizFile("IN001",Boolean.FALSE, IoParam.BASE_PATH,"csv","utf8","model","score");bizFileInfo(bizFile) ;/** 业务性校验*/File file = new File(bizFile.getFileUrl());if (!file.getName().endsWith(bizFile.getFileType())){System.out.println(file.getName()+":描述错误...");}}private static void bizFileInfo (BizFile bizFile){logInfo("任务ID",bizFile.getTaskId());logInfo("是否解压",bizFile.getZipFlag());logInfo("文件地址",bizFile.getFileUrl());logInfo("文件类型",bizFile.getFileType());logInfo("文件编码",bizFile.getFileCode());logInfo("业务库",bizFile.getBizDataBase());logInfo("业务表",bizFile.getBizTableName());}
}
1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.
基于主体描述的信息,也可以转化到命名规则上:命名策略:编号_压缩_Excel_编码_库_表,这样一来在业务处理时,不符合约定的文件直接排除掉,降低文件异常导致的数据问题。
四、基础流模式
1、整体概述
IO流向
基本编码逻辑:源文件->输入流->逻辑处理->输出流->目标文件;
基于不同的角度看,流可以被划分很多模式:
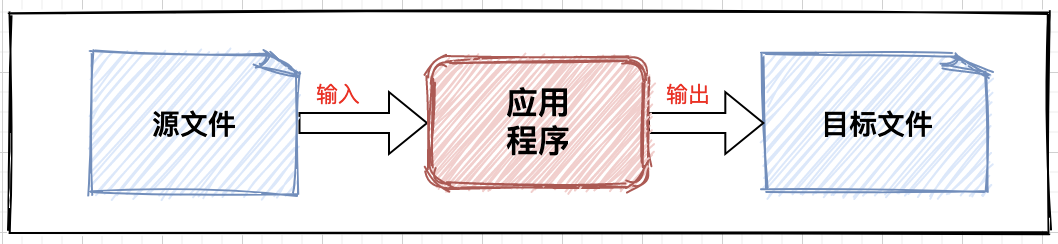
- 流动方向:输入流、输出流;
- 流数据类型:字节流、字符流;
IO流的模式有很多种,相应的API设计也很复杂,通常复杂的API要把握住核心接口与常用的实现类和原理。
基础API
-
字节流:InputStream输入、OutputStream输出;数据传输的基本单位是字节;
- read():输入流中读取数据的下一个字节;
- read(byte b[]):读数据缓存到字节数组;
- write(int b):指定字节写入输出流;
- write(byte b[]):数组字节写入输出流;
-
字符流:Reader读取、Writer写出;数据传输的基本单位是字符;
- read():读取一个单字符;
- read(char cbuf[]):读取到字符数组;
- write(int c):写一个指定字符;
- write(char cbuf[]):写一个字符数组;
缓冲模式
IO流常规读写模式,即读取到数据然后写出,还有一种缓冲模式,即数据先加载到缓冲数组,在读取的时候判断是否要再次填充缓冲区:

缓冲模式的优点十分明显,保证读写过程的高效率,并且与数据填充过程隔离执行,在BufferedInputStream、BufferedReader类中是对缓冲逻辑的具体实现。
2、字节流
API关系图:

字节流基础API:
public class IoByte01 {public static void main(String[] args) throws Exception {// 源文件 目标文件File source = new File(IoParam.BASE_PATH+"fileio-01.png") ;File target = new File(IoParam.BASE_PATH+"copy-"+source.getName()) ;// 输入流 输出流InputStream inStream = new FileInputStream(source) ;OutputStream outStream = new FileOutputStream(target) ;// 读入 写出byte[] byteArr = new byte[1024];int readSign ;while ((readSign=inStream.read(byteArr)) != -1){outStream.write(byteArr);}// 关闭输入、输出流outStream.close();inStream.close();}
}
1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.
字节流缓冲API:
public class IoByte02 {public static void main(String[] args) throws Exception {// 源文件 目标文件File source = new File(IoParam.BASE_PATH+"fileio-02.png") ;File target = new File(IoParam.BASE_PATH+"backup-"+source.getName()) ;// 缓冲:输入流 输出流InputStream bufInStream = new BufferedInputStream(new FileInputStream(source));OutputStream bufOutStream = new BufferedOutputStream(new FileOutputStream(target));// 读入 写出int readSign ;while ((readSign=bufInStream.read()) != -1){bufOutStream.write(readSign);}// 关闭输入、输出流bufOutStream.close();bufInStream.close();}
}
1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.
字节流应用场景:数据是文件本身,例如图片,视频,音频等。
3、字符流
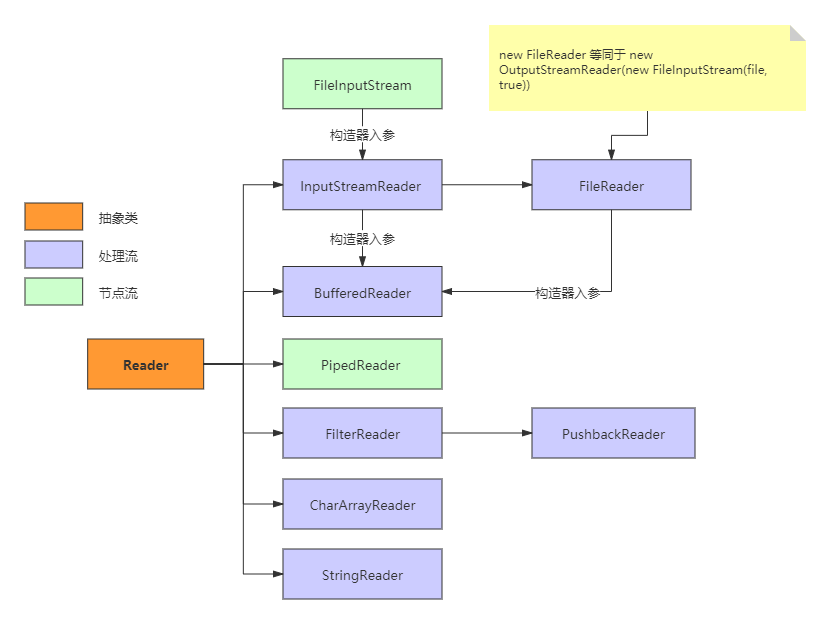
API关系图:
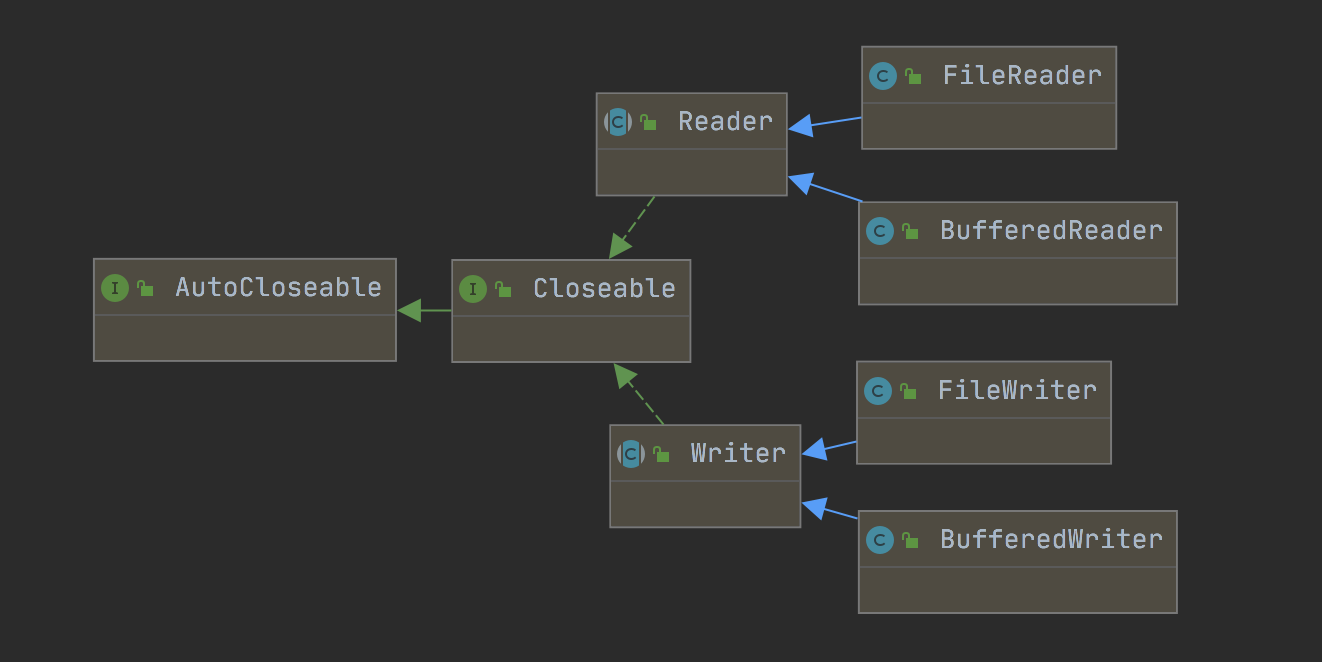
字符流基础API:
public class IoChar01 {public static void main(String[] args) throws Exception {// 读文本 写文本File readerFile = new File(IoParam.BASE_PATH+"io-text.txt") ;File writerFile = new File(IoParam.BASE_PATH+"copy-"+readerFile.getName()) ;// 字符输入输出流Reader reader = new FileReader(readerFile) ;Writer writer = new FileWriter(writerFile) ;// 字符读入和写出int readSign ;while ((readSign = reader.read()) != -1){writer.write(readSign);}writer.flush();// 关闭流writer.close();reader.close();}
}
1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.
字符流缓冲API:
public class IoChar02 {public static void main(String[] args) throws Exception {// 读文本 写文本File readerFile = new File(IoParam.BASE_PATH+"io-text.txt") ;File writerFile = new File(IoParam.BASE_PATH+"line-"+readerFile.getName()) ;// 缓冲字符输入输出流BufferedReader bufReader = new BufferedReader(new FileReader(readerFile)) ;BufferedWriter bufWriter = new BufferedWriter(new FileWriter(writerFile)) ;// 字符读入和写出String line;while ((line = bufReader.readLine()) != null){bufWriter.write(line);bufWriter.newLine();}bufWriter.flush();// 关闭流bufWriter.close();bufReader.close();}
}
1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.
字符流应用场景:文件作为数据的载体,例如Excel、CSV、TXT等。
4、编码解码
- 编码:字符转换为字节;
- 解码:字节转换为字符;
public class EnDeCode {public static void main(String[] args) throws Exception {String var = "IO流" ;// 编码byte[] enVar = var.getBytes(StandardCharsets.UTF_8) ;for (byte encode:enVar){System.out.println(encode);}// 解码String deVar = new String(enVar,StandardCharsets.UTF_8) ;System.out.println(deVar);// 乱码String messyVar = new String(enVar,StandardCharsets.ISO_8859_1) ;System.out.println(messyVar);}
}
1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.

乱码出现的根本原因,就是在编码与解码的两个阶段使用的编码类型不同。
5、序列化
- 序列化:对象转换为流的过程;
- 反序列化:流转换为对象的过程;
public class SerEntity implements Serializable {private Integer id ;private String name ;
}
public class Seriali01 {public static void main(String[] args) throws Exception {// 序列化对象OutputStream outStream = new FileOutputStream("SerEntity.txt") ;ObjectOutputStream objOutStream = new ObjectOutputStream(outStream);objOutStream.writeObject(new SerEntity(1,"Cicada"));objOutStream.close();// 反序列化对象InputStream inStream = new FileInputStream("SerEntity.txt");ObjectInputStream objInStream = new ObjectInputStream(inStream) ;SerEntity serEntity = (SerEntity) objInStream.readObject();System.out.println(serEntity);inStream.close();}
}
1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.
注意:引用类型的成员对象也必须是可被序列化的,否则会抛出NotSerializableException异常。
五、NIO模式
1、基础概念
NIO即(NonBlockingIO),面向数据块的处理机制,同步非阻塞模型,服务端的单个线程可以处理多个客户端请求,对IO流的处理速度有极高的提升,三大核心组件:
- Buffer(缓冲区):底层维护数组存储数据;
- Channel(通道):支持读写双向操作;
- Selector(选择器):提供Channel多注册和轮询能力;
API使用案例
public class IoNew01 {public static void main(String[] args) throws Exception {// 源文件 目标文件File source = new File(IoParam.BASE_PATH+"fileio-02.png") ;File target = new File(IoParam.BASE_PATH+"channel-"+source.getName()) ;// 输入字节流通道FileInputStream inStream = new FileInputStream(source);FileChannel inChannel = inStream.getChannel();// 输出字节流通道FileOutputStream outStream = new FileOutputStream(target);FileChannel outChannel = outStream.getChannel();// 直接通道复制// outChannel.transferFrom(inChannel, 0, inChannel.size());// 缓冲区读写机制ByteBuffer buffer = ByteBuffer.allocateDirect(1024);while (true) {// 读取通道中数据到缓冲区int in = inChannel.read(buffer);if (in == -1) {break;}// 读写切换buffer.flip();// 写出缓冲区数据outChannel.write(buffer);// 清空缓冲区buffer.clear();}outChannel.close();inChannel.close();}
}
1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.
上述案例只是NIO最基础的文件复制能力,在网络通信中,NIO模式的发挥空间十分宽广。
2、网络通信
服务端的单线程可以处理多个客户端请求,通过轮询多路复用器查看是否有IO请求,这样一来,服务端的并发能力得到极大的提升,并且显著降低了资源的消耗。

API案例:服务端模拟
public class SecServer {public static void main(String[] args) {try {//启动服务开启监听ServerSocketChannel socketChannel = ServerSocketChannel.open();socketChannel.socket().bind(new InetSocketAddress("127.0.0.1", 8089));// 设置非阻塞,接受客户端socketChannel.configureBlocking(false);// 打开多路复用器Selector selector = Selector.open();// 服务端Socket注册到多路复用器,指定兴趣事件socketChannel.register(selector, SelectionKey.OP_ACCEPT);// 多路复用器轮询ByteBuffer buffer = ByteBuffer.allocateDirect(1024);while (selector.select() > 0){Set<SelectionKey> selectionKeys = selector.selectedKeys();Iterator<SelectionKey> selectionKeyIter = selectionKeys.iterator();while (selectionKeyIter.hasNext()){SelectionKey selectionKey = selectionKeyIter.next() ;selectionKeyIter.remove();if(selectionKey.isAcceptable()) {// 接受新的连接SocketChannel client = socketChannel.accept();// 设置读非阻塞client.configureBlocking(false);// 注册到多路复用器client.register(selector, SelectionKey.OP_READ);} else if (selectionKey.isReadable()) {// 通道可读SocketChannel client = (SocketChannel) selectionKey.channel();int len = client.read(buffer);if (len > 0){buffer.flip();byte[] readArr = new byte[buffer.limit()];buffer.get(readArr);System.out.println(client.socket().getPort() + "端口数据:" + new String(readArr));buffer.clear();}}}}} catch (Exception e) {e.printStackTrace();}}
}
1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.
API案例:客户端模拟
public class SecClient {public static void main(String[] args) {try {// 连接服务端SocketChannel socketChannel = SocketChannel.open();socketChannel.connect(new InetSocketAddress("127.0.0.1", 8089));ByteBuffer writeBuffer = ByteBuffer.allocate(1024);String conVar = "[hello-8089]";writeBuffer.put(conVar.getBytes());writeBuffer.flip();// 每隔5S发送一次数据while (true) {Thread.sleep(5000);writeBuffer.rewind();socketChannel.write(writeBuffer);writeBuffer.clear();}} catch (Exception e) {e.printStackTrace();}}
}
1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.
SelectionKey绑定Selector和Chanel之间的关联,并且可以获取就绪状态下的Channel集合。
六、源代码地址
登录后复制
GitHub·地址
https://github.com/cicadasmile/java-base-parent
GitEE·地址
https://gitee.com/cicadasmile/java-base-parent
最后
全套的Java面试宝典手册:性能调优+微服务架构+并发编程+开源框架+分布式”等七大面试专栏,包含Tomcat、JVM、IO相关资料分享、SpringCloud、SpringBoot、Dubbo、并发、Spring、SpringMVC、MyBatis、Zookeeper、Ngnix、Kafka、MQ、Redis、MongoDB、memcached等等。
有需要的朋友可以关注公众号【程序媛小琬】即可获取。