缓存设计
- 前言
- 正文
- 缓存对象
- 缓存服务
- 缓存策略
- 本地缓存
- Guava的使用
- 分布式缓存
- Redis缓存
- 分布式缓存的生命周期
- 分布式缓存的一致性问题
- 源码解读
- 从缓存中获取秒杀品
- 分布式锁
- 总结
- 参考链接
前言
大家好,我是练习两年半的Java练习生,本篇文章会分析秒杀系统里面关于缓存部分的内容,先介绍缓存的对象和涉及的服务类,再从缓存策略入手,分析本地缓存 + 分布式缓存在代码中的具体体现和应用,最后再整体分析一下缓存这部分的源码和分布式锁的应用。其中分布式缓存的实现和分布式锁是关键,面试也被问过,希望大家可以仔细看看,有什么问题欢迎在评论区提出。
正文
秒杀品缓存涉及主要类有两个
- FlashItemCache:为缓存的对象
- FlashItemCacheService:缓存服务的主要承担者
缓存对象
package com.actionworks.flashsale.app.service.item.cache.model;import com.actionworks.flashsale.domain.model.entity.FlashItem;
import lombok.Data;
import lombok.experimental.Accessors;@Data@Accessors(chain = true)public class FlashItemCache {protected boolean exist; // 商品是否存在的标志private FlashItem flashItem; // 商品信息private Long version; // 版本号private boolean later; // 是否稍后尝试public FlashItemCache with(FlashItem flashActivity) {this.exist = true;this.flashItem = flashActivity;return this;}public FlashItemCache withVersion(Long version) {this.version = version;return this;}public FlashItemCache tryLater() {this.later = true;return this;}public FlashItemCache notExist() {this.exist = false;return this;}}
缓存服务
商品缓存服务类 FlashItemCacheService,它实现了缓存的读取和更新逻辑。
主要功能点包括:
- 使用 Guava 的 CacheBuilder 创建了一个本地缓存 flashItemLocalCache,用于缓存商品信息。
- 使用 distributedCacheService 接口进行分布式缓存操作,该接口使用 Redis 作为分布式服务。
- 使用 distributedLockFactoryService 接口获取分布式锁对象,该接口使用 Redisson 实现。
- getCachedItem 方法根据商品ID和版本号从缓存中获取商品信息,如果缓存中存在且版本号匹配,则直接返回缓存中的商品信息;如果版本号不匹配或缓存中不存在,则从分布式缓存中获取商品信息。
- getLatestDistributedCache 方法从分布式缓存中获取商品信息,如果分布式缓存中不存在该商品信息,则通过获取分布式锁来更新缓存,并将最新的商品信息存入分布式缓存和本地缓存中。
- tryToUpdateItemCacheByLock 方法尝试通过获取分布式锁来更新缓存,首先尝试获取锁,如果获取失败则返回一个带有 later 标志的空缓存对象;如果成功获取锁,则检查分布式缓存中是否已存在该商品信息,如果存在则直接返回,如果不存在则从领域服务中获取商品信息,并创建一个带有版本号的商品缓存对象,然后将其存入分布式缓存中。
- buildItemCacheKey 方法用于构建缓存键,将商品ID与固定前缀拼接起来作为键值。
需要注意的是,该类使用了本地缓存和分布式缓存两种方式来存储和获取商品信息,并且在更新缓存时使用了分布式锁来保证数据一致性和并发安全性。
缓存策略
本地缓存(Guava) + 分布式缓存(Redis)
本地缓存
本地缓存使用的是Guava,Guava是Google开发的一个Java库,其中包含了许多实用的工具和类。
其实,spring框架也有自己的本地缓存支持。
这两者的主要区别有
- 库和依赖:Guava的缓存功能是Guava库的一部分,而Spring的缓存功能是Spring框架的一部分。因此,如果您选择使用Guava缓存,您需要添加Guava库的依赖;而如果您选择使用Spring缓存,您需要添加Spring框架的依赖。
- 功能和灵活性:Guava的缓存功能提供了一组简单而强大的API,可以轻松创建和管理缓存。它具有可配置的缓存过期时间、缓存大小限制、淘汰策略等功能,并且可以使用自定义的缓存加载器和回收器。相比之下,Spring的缓存功能更加强大和灵活,它提供了更多的注解和配置选项,可以与Spring的事务、AOP等其他特性集成。
- 项目依赖:Guava是一个独立的Java库,可以在任何Java项目中使用,而Spring是一个全功能的应用程序开发框架,需要整合到Spring项目中使用。如果您已经使用Spring框架进行应用程序开发,那么使用Spring的缓存功能可以更加方便,因为它可以与其他Spring特性无缝集成。
- 社区支持和生态系统:Spring是一个广泛使用的框架,具有庞大的社区和生态系统。Spring的缓存功能得到了广泛的支持和使用,您可以从社区中获得丰富的文档、教程和示例。相比之下,Guava虽然也有一个活跃的社区,但它的使用范围相对较小。
如果想要深入学习spring缓存和Guava,可以去看网站:https://www.baeldung.com/spring-cache-tutorial和https://www.baeldung.com/guava
这里主要讲Guava在秒杀项目中是如何使用的。
Guava的使用
- 初始化缓存的大小
下面代码的含义:
- **initialCapacity(10)**设置了设置缓存的初始容量为10,表示缓存对象的初始大小。
- concurrencyLevel(5):设置缓存的并发级别为5,表示可以同时进行的写操作的线程数。
- expireAfterWrite(10, TimeUnit.SECONDS):设置缓存项的写入后过期时间为10秒。
@Service
public class FlashItemCacheService {private final static Logger logger = LoggerFactory.getLogger(FlashItemCacheService.class);// 本地缓存,使用Guava CacheBuilderprivate final static Cache<Long, FlashItemCache> flashItemLocalCache = CacheBuilder.newBuilder().initialCapacity(10).concurrencyLevel(5).expireAfterWrite(10, TimeUnit.SECONDS).build();...}
那么这些指标的依据是什么呢?
简单来说,这些指标设置标准是根据实际需求和性能优化来决定的。您可以根据自己的应用场景和数据特点进行调整。需要注意的是,这些指标设置的目的是在性能和资源消耗之间找到一个平衡,以提供最佳的缓存效果。
那么问题又来了,如何在性能和资源消耗之间找到一个平衡,以提供最佳的缓存效果呢?
可以从以下几个方面考虑:
- 缓存大小和容量:适当设置缓存的大小和容量是关键。如果缓存容量过小,可能导致频繁的缓存失效和重新加载,降低性能。如果缓存容量过大,可能会占用过多的内存资源。通过观察应用程序的数据访问模式和缓存使用情况,选择合适的缓存容量,以充分利用缓存的好处并避免过度消耗资源。
- 缓存过期策略:缓存过期时间的设置也是性能和资源消耗之间的权衡。较短的过期时间可以确保缓存数据的新鲜性,但可能增加缓存更新的频率和资源消耗。较长的过期时间可以减少缓存更新的次数和资源消耗,但可能导致数据过时。根据应用程序的特点和需求,选择适当的过期时间来平衡性能和数据实时性。
- 缓存并发性:并发级别是指可以同时进行的写操作的线程数。过高的并发级别可能导致竞争和锁争用,影响性能。过低的并发级别可能无法充分利用系统资源,降低并发性能。通过观察并发访问模式和系统负载情况,选择适当的并发级别,以提供良好的并发性能。
- 冷热数据分离:根据数据的访问频率,将数据分为冷数据(很少访问)和热数据(经常访问)。可以采用不同的缓存策略和配置来处理冷热数据。对于热数据,可以采用较大的缓存容量和较短的过期时间,以提供更高的性能。对于冷数据,可以采用较小的缓存容量和较长的过期时间,以节省资源并保持适度的性能。
- 监控和优化:定期监控缓存的命中率、失效率和资源使用情况,以及应用程序的性能指标。根据监控数据进行优化,可以根据实际情况进行调整,例如调整缓存容量、过期时间、并发级别等,以持续优化缓存效果。
其实,有很多手段可以来找到这个平衡点。
比如说容量压测,通过进行容量压测,您可以模拟并观察在不同负载和并发情况下缓存的性能表现。在进行压测时,可以收集和分析关键指标,如响应时间、吞吐量、命中率、缓存失效率和资源使用情况等。这些指标可以帮助您了解缓存在不同负载下的性能表现和资源消耗情况。
压测是一个迭代过程,通过多次测试和调整,逐步优化缓存配置,以达到性能和资源消耗的平衡。同时,还需要关注系统其他方面的指标,如内存使用、CPU利用率和磁盘IO等,以确保整体系统的稳定性和可扩展性。
这个性能和资源消耗之间的平衡点是一个相对主观的判断,它可以从下面几个方面考虑:
-
业务需求:首先要明确应用程序的业务需求和性能目标。不同的应用程序对性能和资源消耗的要求可能不同。例如,某些应用程序对性能要求非常高,可能需要更大的缓存容量和更低的响应时间,而其他应用程序可能更注重资源消耗的控制。
-
用户体验:用户体验是评估应用程序性能的重要指标之一。平衡点应该能够提供足够的性能,以满足用户对应用程序的响应和加载时间的期望。
-
资源可用性:考虑应用程序运行环境的资源限制,如内存、CPU和磁盘等。平衡点应该在可用资源的范围内,避免过度消耗系统资源,以确保应用程序整体的稳定性和可靠性。
-
监控和优化:通过定期监控和分析应用程序的性能指标、缓存命中率和资源使用情况,可以根据实际数据进行优化调整。观察指标的变化趋势和性能瓶颈,有助于找到更接近平衡点的配置和参数。
-
实验和迭代:在寻找平衡点的过程中,可以进行实验和迭代。通过尝试不同的配置和参数组合,进行容量压测和实际场景测试,从中收集数据和反馈,逐步调整和优化,以找到最佳的性能和资源消耗平衡点。
-
缓存的生命周期
结合业务规则,目前本地缓存的刷新机制有2种:
- 被动更新:本地缓存过期后被驱逐;
- 主动更新:请求传入的版本号大于本地缓存的版本号,意味着本地缓存的数据滞后,需要从分布式缓存中重新获取。
分布式缓存
Redis缓存
分布式缓存在使用的时候,是依赖DistributedCacheService这个接口的,这个接口下可以扩展不同的分布式缓存中间件,这个项目里使用的是redis,RedisCacheService类实现了上面这个接口。
下面是RedisCacheService类的代码:
package com.actionworks.flashsale.cache.redis;import com.actionworks.flashsale.cache.DistributedCacheService;
import com.actionworks.flashsale.cache.redis.util.ProtoStuffSerializerUtil;
import com.alibaba.fastjson.JSON;
import org.apache.commons.lang3.StringUtils;
import org.springframework.data.redis.core.RedisCallback;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;import javax.annotation.Resource;
import java.util.List;
import java.util.concurrent.TimeUnit;@Component
public class RedisCacheService implements DistributedCacheService {@Resourceprivate RedisTemplate<String, Object> redisTemplate;@Overridepublic void put(String key, String value) {if (StringUtils.isEmpty(key) || value == null) {return;}redisTemplate.opsForValue().set(key, value);}@Overridepublic void put(String key, Object value) {if (StringUtils.isEmpty(key) || value == null) {return;}redisTemplate.opsForValue().set(key, value);}@Overridepublic void put(String key, Object value, long timeout, TimeUnit unit) {if (StringUtils.isEmpty(key) || value == null) {return;}redisTemplate.opsForValue().set(key, value, timeout, unit);}@Overridepublic void put(String key, Object value, long expireTime) {if (StringUtils.isEmpty(key) || value == null) {return;}redisTemplate.opsForValue().set(key, value, expireTime, TimeUnit.SECONDS);}@Overridepublic <T> T getObject(String key, Class<T> targetClass) {Object result = redisTemplate.opsForValue().get(key);if (result == null) {return null;}try {return JSON.parseObject((String) result, targetClass);} catch (Exception e) {return null;}}@Overridepublic String getString(String key) {Object result = redisTemplate.opsForValue().get(key);if (result == null) {return null;}return String.valueOf(result);}@Overridepublic <T> List<T> getList(String key, Class<T> targetClass) {Object result = redisTemplate.execute((RedisCallback<Object>) connection ->connection.get(key.getBytes()));if (result == null) {return null;}return ProtoStuffSerializerUtil.deserializeList(String.valueOf(result).getBytes(), targetClass);}@Overridepublic Boolean delete(String key) {if (StringUtils.isEmpty(key)) {return false;}return redisTemplate.delete(key);}@Overridepublic Boolean hasKey(String key) {return redisTemplate.hasKey(key);}public RedisTemplate<String, Object> getRedisTemplate() {return redisTemplate;}
}这里put方法和getObject方法都使用重载的方式提供了多个,目的是为了应对不同数据的存储。
这里调用的是redisTemplate用于访问redis,需要在配置文件中配置redis的地址密码等。如果想要了解redis的使用可以参考:https://redis.com.cn/documentation.html
这里,我比较关注这个getList方法,里面使用到redisTemplate.execute()这个方法,它允许在 RedisTemplate 实例上执行自定义的 Redis 命令,并且可以与 Redis 的回调函数一起使用。
具体而言,execute() 方法接受一个 RedisCallback 对象作为参数,该对象包含了要执行的具体 Redis 命令逻辑。通过 execute() 方法,可以直接调用 Redis 的原生命令,并处理返回的结果。
通过使用 redisTemplate.execute() 方法和传递一个 RedisCallback 对象,我们可以执行更底层、更灵活的 Redis 命令,以满足特定的需求。
这里通过redisTemplate.execute() 获得一个object的对象,因为在网络传输中对象会被序列化,所以这里需要反序列化这个对象。
可以想想为什么需要序列化?
反序列化调用的是ProtoStuffSerializerUtil.deserializeList()方法,这个方法里面是调用 Protostuff 序列化库中的一个工具类io.protostuff.ProtostuffIOUtil。 Protostuff 是一个高性能的 Java 序列化库,主要用于将 Java 对象序列化为字节流,并将字节流反序列化为 Java 对象。
分布式缓存的生命周期
相比于本地缓存,分布式缓存的过期时间要稍微长一些,并且在更新机制上与本地缓存略有不同:
- 被动刷新:基于Redis的数据驱逐策略,包括LRU和TTL等;
- 主动刷新:业务数据驱动的数据更新。当业务侧有数据变更时,将会主动刷新分布式缓存。比如当秒杀品下线时,会发出相应的领域事件,而在领域事件的处理中就会刷新缓存。
注意一个问题:
分布式缓存在刷新的过程中,并不会主动刷新所有服务器上的本地缓存,本地缓存将遵循单机的刷新策略。这意味着,本地缓存可能会有秒级或毫秒级的滞后,对于数据一致性非绝对敏感的场景,这种短时间的延迟下的脏数据是可以接受的,它只是会对用户侧的展示有所影响,而不会影响到服务端的数据状态。
当然,如果也可以引入消息队列进行缓存的更新,但这个项目中为了降低复杂度,没有选择这种方式。
分布式缓存的一致性问题
两个问题:
- 如何保证缓存与数据库数据的一致性?
- 如何保证本地缓存与分布式缓存的一致性?
这两个问题比较复杂,在这里很难讲清楚,有兴趣的话,后面可以单独写文章来讨论一下。
这里只介绍该项目中的作法,并分析其优点和劣势。
首先,我们需要理解一致性的概念。一致性分为“强一致性”和“弱一致性”,这两者有什么区别呢?
强一致性: 要求系统中的数据在任何时间点都具有一致的视图,即所有的读操作都会看到最新的写操作结果。
弱一致性:则允许系统中的数据在某些时刻出现不一致的状态,即不同节点之间的读操作可能看到不同的数据视图。
该项目中缓存部分使用的是缓存的弱一致性,就是接受不同节点的读操作可以看到不同的数据视图。
而把强一致性交给数据库约束+业务规则约束+补偿机制 。
为什么要这么做呢?
首先,由CAP理论指出,在分布式系统中,无法同时满足一致性(Consistency)、可用性(Availability)和分区容忍性(Partition Tolerance)这三个属性。
所以,我们必须在“鱼与熊掌之间”做选择,我们这里让缓存回归最初的目的,即保持高可用性。因此,在保证数据库最终一致的情况下,我们允许本地缓存和分布式缓存有秒级或毫秒级的延迟。当然,我们要尽可能地降低缓存的延迟,以提高用户体验。
如何实现上面所说的内容呢?
数据强一致性实现:
- 数据库约束
- 业务规则约束
- 补偿机制
首先,数据强一致性包含哪些方面呢?
-
实体完整性(Entity Integrity):确保数据表中每个实体(行)都具有唯一的标识符或主键,并且不存在重复的实体。这可以通过主键约束来实现。
-
引用完整性(Referential Integrity):确保数据表中的外键引用关系是有效的,即引用的数据存在于关联的表中。这可以通过外键约束来实现。
-
域完整性(Domain Integrity):确保数据表中的数据符合其定义的规定域(数据类型、取值范围等)。例如,日期字段只接受有效的日期值,数值字段只接受合法的数值等。
-
用户定义的一致性(User-Defined Consistency):根据具体业务需求,应用程序可以定义一些特定的一致性规则,以确保数据的逻辑正确性。例如,某个订单状态字段只能在特定的取值范围内变化。
-
数据约束的一致性(Consistency of Data Constraints):确保数据表中定义的各种约束条件得到满足,包括唯一性约束、非空约束、检查约束等。这些约束条件可以在数据库中定义,并由数据库管理系统进行强制执行。
-
时序一致性(Temporal Consistency):确保数据在时间上的一致性,即保证不同时间点的数据操作按照特定的顺序执行,以避免产生冲突或不一致的结果
-
数据库约束
那么数据库约束如何实现数据的强一致性呢?
数据库管理系统(DBMS)提供了一系列的约束和规范机制,可以帮助确保数据的一致性。
数据库管理系统提供的约束和规范机制包括:
- 主键约束(Primary Key Constraint):确保每个表中的主键列具有唯一性,避免数据重复和数据不完整。
- 外键约束(Foreign Key Constraint):确保表之间的关联关系有效,通过关联的主键和外键保持数据的引用完整性。
- 唯一性约束(Unique Constraint):确保某个列或一组列的值是唯一的,避免数据重复。
- 非空约束(Not Null Constraint):确保某个列不接受空值,保证数据的完整性。
- 检查约束(Check Constraint):定义列或表级别的检查规则,确保数据满足指定的条件,例如数值范围、字符串格式等。
通过在数据库表的定义中添加这些约束,DBMS会在数据插入、更新或删除操作时进行自动验证,并拒绝违反约束条件的操作。这样可以避免不一致、不完整或无效的数据进入数据库,提供数据的一致性保证。
此外,DBMS还提供了事务管理机制,例如ACID(原子性、一致性、隔离性和持久性)属性,确保在事务中的一系列操作要么全部成功提交,要么全部失败回滚,以保持数据的一致性状态。
秒杀系统中是如何做的?
CREATE DATABASE IF NOT EXISTS flash_saledefault charset = utf8mb4;CREATE TABLE IF NOT EXISTS flash_sale.`flash_activity` (`id` bigint(20) NOT NULL AUTO_INCREMENTCOMMENT '主键',`activity_name` varchar(50) NOT NULLCOMMENT '秒杀活动名称',`activity_desc` text COMMENT '秒杀活动描述',`start_time` datetime NOT NULLCOMMENT '秒杀活动开始时间',`end_time` datetime NOT NULLCOMMENT '秒杀活动结束时间',`status` int(11) NOT NULL DEFAULT '0'COMMENT '秒杀活动状态',`modified_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMPCOMMENT '更新时间',`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMPCOMMENT '创建时间',PRIMARY KEY (`id`),KEY `flash_activity_end_time_idx` (`end_time`),KEY `flash_activity_start_time_idx` (`start_time`),KEY `flash_activity_status_idx` (`status`)
)ENGINE = InnoDBDEFAULT CHARSET = utf8mb4COMMENT = '秒杀活动表';CREATE TABLE IF NOT EXISTS flash_sale.`flash_item` (`id` bigint(20) NOT NULL AUTO_INCREMENTCOMMENT '主键',`item_title` varchar(50) NOT NULLCOMMENT '秒杀品名称标题',`item_sub_title` varchar(50) NULLCOMMENT '秒杀品副标题',`item_desc` text COMMENT '秒杀品介绍富文本文案',`initial_stock` int(11) NOT NULL DEFAULT '0'COMMENT '秒杀品初始库存',`available_stock` int(11) NOT NULL DEFAULT '0'COMMENT '秒杀品可用库存',`stock_warm_up` int(11) NOT NULL DEFAULT '0'COMMENT '秒杀品库存是否已经预热',`original_price` bigint(20) NOT NULLCOMMENT '秒杀品原价',`flash_price` bigint(20) NOT NULLCOMMENT '秒杀价',`start_time` datetime NOT NULLCOMMENT '秒杀开始时间',`end_time` datetime NOT NULLCOMMENT '秒杀结束时间',`rules` text COMMENT '秒杀可配规则,JSON格式',`status` int(11) NOT NULL DEFAULT '0'COMMENT '秒杀品状态',`activity_id` bigint(20) NOT NULLCOMMENT '所属活动id',`modified_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMPCOMMENT '更新时间',`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMPCOMMENT '创建时间',PRIMARY KEY (`id`),KEY `flash_item_end_time_idx` (`end_time`),KEY `flash_item_start_time_idx` (`start_time`),KEY `flash_item_status_idx` (`status`)
)ENGINE = InnoDBDEFAULT CHARSET = utf8mb4COMMENT = '秒杀品';CREATE TABLE IF NOT EXISTS flash_sale.`flash_order` (`id` bigint(20) NOT NULL AUTO_INCREMENTCOMMENT '主键',`item_id` bigint(20) NOT NULLCOMMENT '秒杀品ID',`activity_id` bigint(20) NOT NULLCOMMENT '秒杀活动ID',`item_title` varchar(50) NOT NULLCOMMENT '秒杀品名称标题',`flash_price` bigint(20) NOT NULLCOMMENT '秒杀价',`quantity` int(11) NOT NULLCOMMENT '数量',`total_amount` bigint(20) NOT NULLCOMMENT '总价格',`status` int(11) NOT NULL DEFAULT '0'COMMENT '订单状态',`user_id` bigint(20) NOT NULLCOMMENT '用户ID',`modified_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMPCOMMENT '更新时间',`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMPCOMMENT '创建时间',PRIMARY KEY (`id`),UNIQUE KEY `flash_order_id_uk` (`id`),KEY `flash_order_user_id_idx` (`user_id`)
)ENGINE = InnoDBDEFAULT CHARSET = utf8mb4COMMENT = '秒杀订单表';GRANT ALL PRIVILEGES ON `flash_sale`.* TO 'thoughts-beta'@'%';
FLUSH PRIVILEGES;可以看到,上述的flash_order表的定义中,可以通过以下方式体现数据库层面对数据一致性的保证:
- 主键约束: id字段被定义为主键(PRIMARY KEY),保证了每个订单的唯一性。主键约束防止重复的订单记录被插入,并确保每个订单都具有唯一的标识。
- 非空约束: 所有的字段(除了自增主键字段id)都被定义为NOT NULL,确保了这些字段的值不能为空。非空约束要求这些字段在插入或更新时必须包含有效的值,避免了数据缺失或不一致的情况。如果字段输入了空,数据库层面会报错,在java程序层面可以捕获到SQLException。这样就保证数据的完整性。
- 默认值约束: 部分字段(如status、modified_time和create_time)使用了默认值约束。默认值约束定义了在未指定具体值时字段应该采用的默认值。通过为这些字段指定默认值,可以在插入数据时自动填充这些字段,确保每个订单都有默认的状态值和时间戳值。
- 索引约束: flash_order_user_id_idx索引被创建在user_id字段上,提高了查询效率。索引的使用可以加快查询速度,减少数据库的负载,并确保在根据用户ID进行查询时能够快速定位相关的订单记录。
这些数据库层面的约束和规范确保了数据的一致性。它们限制了允许插入或更新的数据的范围,并强制执行一些业务规则,例如非空字段和默认值。通过遵守这些约束,数据库层面可以保证数据的一致性和完整性,减少了数据错误和不一致的可能性。
- 业务规则约束
业务规则约束是指在应用程序中定义和实施的规则,用于确保数据的一致性和完整性。这些规则基于具体的业务需求和业务逻辑,用于限制和验证数据的合法性。
以下是一些常见的业务规则约束示例:
- 数据关联约束:确保相关数据之间的关联关系是有效的。例如,在订单项中,确保订单项关联的订单ID存在于订单表中,并且与正确的订单相关联。
- 唯一性约束:保证某些字段的唯一性,避免重复的数据。例如,确保用户表中的电子邮件字段是唯一的,每个电子邮件地址只能关联一个用户。
- 数据范围约束:限制字段的取值范围,确保数据在合理的范围内。例如,限制年龄字段的取值范围在18到65岁之间,以符合业务规定的年龄要求。
- 数据完整性约束:确保数据满足特定的完整性要求。例如,确保订单表中的必填字段都有值,以避免不完整的订单记录。
- 业务逻辑约束:基于特定的业务逻辑要求来验证数据。例如,对于电子商务网站的购物车功能,确保商品数量大于0且不超过库存量,以避免无效的购物车操作。
业务规则在该项目的代码中出现的就比较多了,举个比较典型的例子。数据库中一般为了性能不使用物理外键,因此需要在业务规则上进行约束。比如说创建秒杀品时,必须绑定已存在的秒杀活动,这种情况就需要在业务规则上进行约束。
- 补偿机制
在分布式系统中,为了保证数据的一致性,可以采用以下几种常见的补偿机制:
事务回滚(Rollback):在分布式事务中,如果某个操作失败或发生错误,可以通过事务回滚来撤销之前已经执行的操作,将数据恢复到之前的状态。这种补偿机制可以保证数据的一致性,但可能会带来性能损失和操作的重复执行。
重试(Retry):当某个操作失败时,可以通过重试操作来尝试重新执行该操作,直到成功或达到最大重试次数。重试机制可以处理临时性的错误,例如网络中断或资源繁忙,从而保证数据操作的完成和一致性。
补偿事务(Compensating Transaction):当分布式事务中的某个操作失败时,可以通过执行补偿事务来撤销已经执行的操作,以恢复数据的一致性。补偿事务通常是针对某个操作的逆向操作,通过执行逆向操作来消除之前操作的影响。
消息队列(Message Queue):通过将操作请求发送到消息队列中,然后由消费者异步处理请求,可以实现数据操作的解耦和异步处理。如果操作失败,可以将错误信息重新放回消息队列中,以便后续重试或进行补偿操作。
日志和重放(Log and Replay):将操作请求和结果记录在日志中,当发生错误或失败时,可以通过回放日志来重新执行操作,确保数据的一致性。通过日志记录和重放,可以实现数据操作的可靠性和一致性。
回到主线上,我们看一下这部分的分布式缓存时怎么设计的。
源码解读

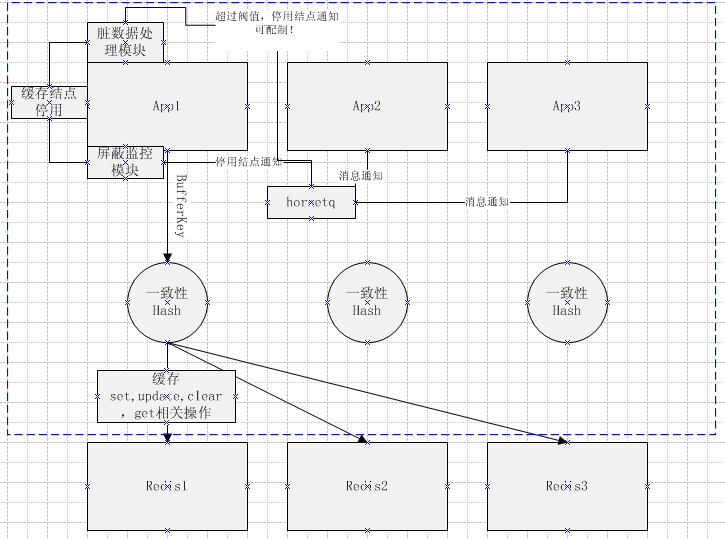
从上图中,我们可以看到应用层通过FlashItemCacheService读取秒杀品的缓存。FlashItemCacheService依赖于分布式缓存服务(DistributedCacheService)、秒杀品领域服务(FlashItemDomainService)和分布式锁服务(DistributedLockFactoryService),并最终返回FlashItemCache对象作为查询结果,FlashItemCache中包含了领域对象FlashItem以及相关的辅助字段,而FlashItemAPPService则通过接口的形式依赖FlashItemCacheService。
从缓存中获取秒杀品
- 先从本地缓存获取
- 本地缓存存在,比较传入版本和本地缓存
- 本地缓存大于传入缓存,则本地缓存有效,返回结果
- 相反,则本地缓存无效,需要获取分布式缓存,并更新本地缓存
- 本地缓存存在,比较传入版本和本地缓存
public FlashItemCache getCachedItem(Long itemId, Long version) {// 检查本地缓存中是否存在该商品FlashItemCache flashItemCache = flashItemLocalCache.getIfPresent(itemId);if (flashItemCache != null) {if (version == null) {logger.info("itemCache|命中本地缓存|{}", itemId);return flashItemCache; // 返回本地缓存中的商品数据}if (version.equals(flashItemCache.getVersion()) || version < flashItemCache.getVersion()) {logger.info("itemCache|命中本地缓存|{}|{}", itemId, version);return flashItemCache; // 返回本地缓存中的商品数据}if (version > flashItemCache.getVersion()) {return getLatestDistributedCache(itemId); // 返回最新的分布式缓存中的商品数据}}return getLatestDistributedCache(itemId); // 返回最新的分布式缓存中的商品数据
}
- 从分布式缓存中获取
- 如果分布式缓存存在
- 则尝试获取本地缓存锁,获取锁成功后
- 进行本地缓存商品信息的更新,完成后释放锁。
- 则尝试获取本地缓存锁,获取锁成功后
- 分布式缓存不存在,则需要更新分布式缓存
- 如果分布式缓存存在
private FlashItemCache getLatestDistributedCache(Long itemId) {logger.info("itemCache|读取远程缓存|{}", itemId);
// 从分布式缓存中获取商品信息
FlashItemCache distributedFlashItemCache = distributedCacheService.getObject(buildItemCacheKey(itemId), FlashItemCache.class);
if (distributedFlashItemCache == null) {// 如果分布式缓存中不存在该商品信息,则尝试通过锁更新缓存distributedFlashItemCache = tryToUpdateItemCacheByLock(itemId);
}
if (distributedFlashItemCache != null && !distributedFlashItemCache.isLater()) {boolean isLockSuccess = localCacheUpdatelock.tryLock();if (isLockSuccess) {try {// 使用最新的商品信息更新本地缓存flashItemLocalCache.put(itemId, distributedFlashItemCache);logger.info("itemCache|本地缓存已更新|{}", itemId);} finally {localCacheUpdatelock.unlock();}}
}
return distributedFlashItemCache;
}
- 更新分布式缓存
- 缓存更新的分布式锁
- 再次确认分布式缓存中是否已经存在商品
- 从领域服务中获取商品信息
- 如果商品存在,则将商品信息加进分布式缓存
- 如果商品不存在,则需要缓存一个空对象,避免缓存穿透。
- 缓存更新的分布式锁
public FlashItemCache tryToUpdateItemCacheByLock(Long itemId) {logger.info("itemCache|更新远程缓存|{}", itemId);// 获取分布式锁,用于更新缓存DistributedLock lock = distributedLockFactoryService.getDistributedLock(UPDATE_ITEM_CACHE_LOCK_KEY + itemId);try {boolean isLockSuccess = lock.tryLock(1, 5, TimeUnit.SECONDS);if (!isLockSuccess) {return new FlashItemCache().tryLater();}// 检查分布式缓存中是否已存在该商品信息FlashItemCache distributedFlashItemCache = distributedCacheService.getObject(buildItemCacheKey(itemId), FlashItemCache.class);if (distributedFlashItemCache != null) {return distributedFlashItemCache;}// 从领域服务中获取商品信息FlashItem flashItem = flashItemDomainService.getFlashItem(itemId);FlashItemCache flashItemCache;if (flashItem == null) {flashItemCache = new FlashItemCache().notExist();} else {// 创建商品缓存对象,并设置版本号为当前时间戳!flashItemCache = new FlashItemCache().with(flashItem).withVersion(System.currentTimeMillis());}// 将商品缓存对象放入分布式缓存中distributedCacheService.put(buildItemCacheKey(itemId), JSON.toJSONString(flashItemCache), FIVE_MINUTES);logger.info("itemCache|远程缓存已更新|{}", itemId);return flashItemCache;} catch (InterruptedException e) {logger.error("itemCache|远程缓存更新失败|{}", itemId);return new FlashItemCache().tryLater();} finally {lock.unlock();}}
其他部分的缓存获取也是类似的,这里就一一讲了。
分布式锁
最后补充一个分布式锁,可以看到在每次更新缓存的时候都需要获取对应的锁,无论是更新本地缓存还是分布式缓存。这部分也是比较重要的,面试常问的地方。
为什么呢?
在更新缓存的场景中,使用分布式锁是为了确保多个并发请求不会同时对同一个缓存进行更新,以避免以下问题:
- 缓存击穿:当缓存中的数据失效,并发请求同时到达时,如果没有加锁机制,每个请求都会穿透缓存直接查询数据库或其他数据源,导致大量的请求同时访问后端资源,可能引发性能问题甚至雪崩效应。通过使用分布式锁,只有一个请求能够获得锁并更新缓存,其他请求会等待或返回旧的缓存数据,从而有效地避免缓存击穿。
- 缓存雪崩:当缓存中的大量数据同时失效或由于某种原因导致不可用时,所有的请求都会直接访问后端资源,给后端系统带来巨大的负载压力。使用分布式锁可以在缓存失效时,只允许一个请求去更新缓存,其他请求继续使用旧的缓存数据,分散了对后端资源的访问压力,避免了缓存雪崩现象的发生。
- 数据不一致:在并发更新缓存的情况下,如果没有加锁机制,多个请求可能同时更新缓存,导致数据不一致的问题。使用分布式锁可以确保在同一时间只有一个请求能够更新缓存,避免了数据不一致性的风险。
通过在更新缓存的关键代码段加上分布式锁,可以保证在多个并发请求中只有一个请求能够获取锁并执行缓存更新操作,而其他请求则会等待或直接使用旧的缓存数据,从而保证了数据的一致性、避免了缓存击穿和缓存雪崩问题。
总结
好啦,以上就是关于秒杀项目缓存的所有问题了,主要向大家介绍了两种缓存方式,本地缓存和分布式缓存。其中,分布式缓存中出现的几个问题,比如说一致性问题、缓存穿透、缓存击穿等,都是值得我们关注的。如果大家有兴趣的话,欢迎大家和我一起来学习这个项目https://github.com/jacky-curry/flash-sale
如果大家还有什么问题,欢迎私信或者在评论区提出来,让我们一起学习进步!!!

参考链接
https://juejin.cn/book/7008372989179723787/section/7016981104028712973