简单说明下,写此文章算是对自己近一段工作的总结,希望能对你有点帮助,同时也是自己的一点小积累。
一.为什么选择redis
在项目中使用redis做为缓存,还没有使用memcache,考虑因素主要有两点:
1.redis丰富的数据结构,其hash,list,set以及功能丰富的String的支持,对于实际项目中的使用有很大的帮忙。(可参考官网redis.io)
2.redis单点的性能也非常高效(利用项目中的数据测试优于memcache).
基于以上考虑,因此选用了redis来做为缓存应用。
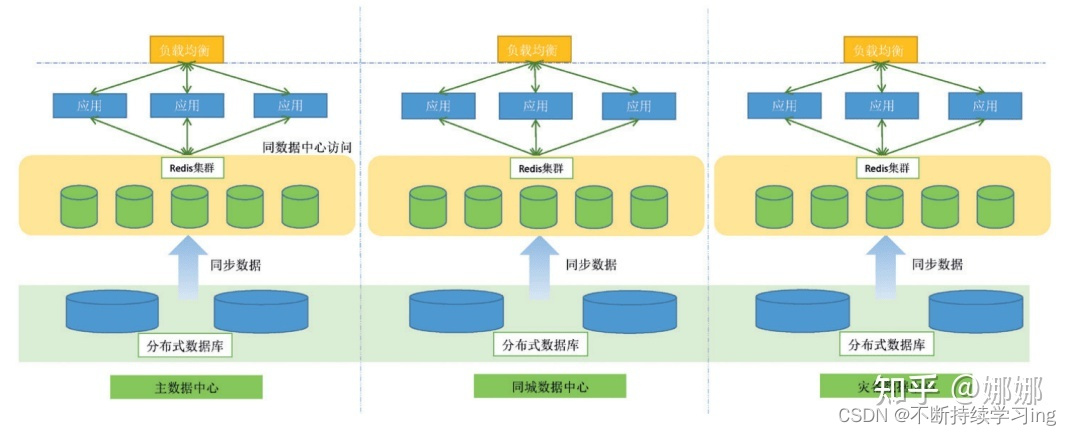
二.分布式缓存的架构设计
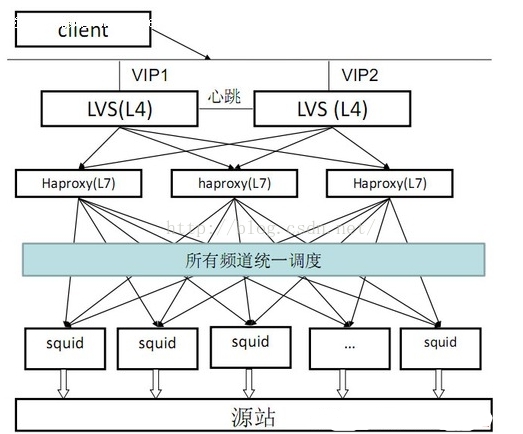
1.架构设计
由于redis是单点,项目中需要使用,必须自己实现分布式。基本架构图如下所示:
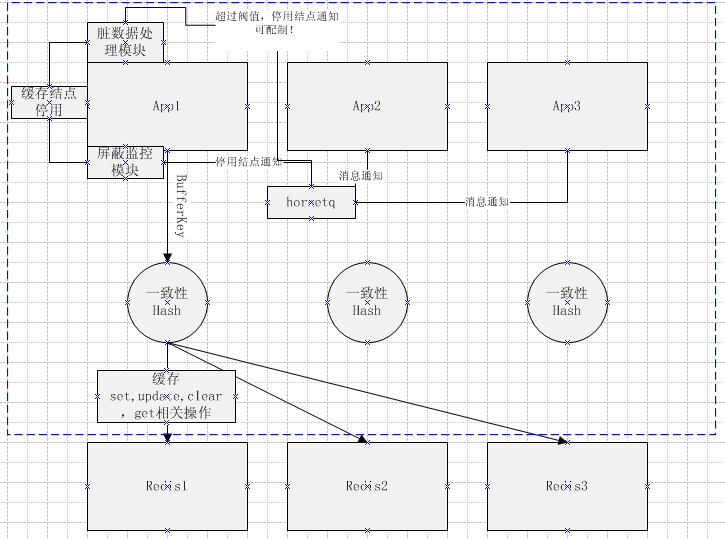
2.分布式实现
通过key做一致性哈希,实现key对应redis结点的分布。
一致性哈希的实现:
l hash值计算:通过支持MD5与MurmurHash两种计算方式,默认是采用MurmurHash,高效的hash计算。
l 一致性的实现:通过java的TreeMap来模拟环状结构,实现均匀分布
3.client的选择
对于jedis修改的主要是分区模块的修改,使其支持了跟据BufferKey进行分区,跟据不同的redis结点信息,可以初始化不同的ShardInfo,同时也修改了JedisPool的底层实现,使其连接pool池支持跟据key,value的构造方法,跟据不同ShardInfos,创建不同的jedis连接客户端,达到分区的效果,供应用层调用
4.模块的说明
l 脏数据处理模块,处理失败执行的缓存操作。
l 屏蔽监控模块,对于jedis操作的异常监控,当某结点出现异常可控制redis结点的切除等操作。
整个分布式模块通过hornetq,来切除异常redis结点。对于新结点的增加,也可以通过reload方法实现增加。(此模块对于新增结点也可以很方便实现)
对于以上分布式架构的实现满足了项目的需求。另外使用中对于一些比较重要用途的缓存数据可以单独设置一些redis结点,设定特定的优先级。另外对于缓存接口的设计,也可以跟据需求,实现基本接口与一些特殊逻辑接口。对于cas相关操作,以及一些事物操作可以通过其watch机制来实现。(参考我以前写的redis事物介绍)
以上是基于redis分布式架构的介绍!但是应用中读写都是在一起的。相关写是在应用操作后flush或者update的,有一定的耦合。为了使读写分离,以及缓存模块跟应用的耦合更小,考虑使用mysql binlog来刷新缓存。以下是基于binlog刷新可性行分析以及实现过程中需要注意的地方。
1.Mysql日志格式介绍可参考我以前的的介绍。
2.对于使用MIXED日志格式,此日志格式,记录的是对应数据库操作的SQL语句,采用此日志方式存在的问题:
l 对于一些未任何更新操作的SQl语句,像条件不满足,对应的sql也会记录到binlog日志中。
l SQL语句记录的未必包括所有的更新操作。
l 对于一些分布式数据库,对于SQL中的where条件指定的是非均衡字段,也许会存在多条SQL,跟设计有关!
基于以上考虑,采用MIXED的日志格式进行binlog解析是行不通的。(官网给出的指示是failed statementsare not logged ,但不包括语法没错误,更新条件不符合对应的SQL)
3.采用ROW日志格式
对于此日志格式,每行变化都有对应的记录,此日志格式,对于解析及采集数据都是非常方便的,也只有采用此日志格式,才能基于binlog修改,做刷新缓存相关方案的设计。但是基于此日志格式也存在一些问题:
l 需要考虑项目中是否有大量的批量的update操作,如果采用此日志格式,批量操作每一行修改都会记录一条日志,大量的批量操作所产生的日志量,以及所带来的IO开销是否可以接受。
通过以上分析,最终项目中还是考虑基于ROW日志格式进行缓存刷新,还有一个问题需要考虑,在应用层DB进行了相应的update操作后,所产生的Binlog是会带来一定的延迟,如果Binlog处理模块正常运行,数据是的延迟会非常少,MS级别以内,对用户体验是没有感知的,但是Binlog模块是多点,异常,以及相应的延迟肯定会是存在的,这样,缓存数据肯定会存在脏数据。
不过通过以上方案,数据能达到最终一致性,因此how to权衡,需要考虑。
通过以上分析,是否采用Binlog来做缓存数据刷新相信大家有一个基本概念了
四.基于binlog刷新缓存的实现时注意的地方
1.如果是采用java做相关开发,可以使用开源的tungstenAPI
2.Binlog日志解析是按照mysql 的master/slave同步流程来实现,即一个线程同步,一个线程解析。
3.设计是可分Binlog处理模块以及缓存处理SqlEvent两部分,其中Binlog处理解析好对应的SqlEvent,然后对应的缓存刷新处理SqlEvent,一个简单的生产者-消费者模式。
4.对于多个Binlog处理模块可以是单点,也可以是通过一些协同工具来管理,看需求。可以使用ZooKeeper等。
5.对于分布式缓存中的数据,对于Binlog来刷新的缓存数据会存在load数据的问题,为了减轻DB的额外压力,flush操作可在get缓存数据处完成。看需求,如果读写完全分享的话此DB的额外压力可以接收的话也可行。
6.对于缓存数据性一致性要求比较高的,可以通过版本号来控制,即在应用层引入一定的耦合,在DB操作时带mark ,缓存刷新是也mark,另外get操作时比较双版本号来达到数据的一致性。(此跟5谈论的一定的联系,读写是否完全分离,以及相应一致性实现的一些方法)
五.一点心得前前后后,对redis完成调研,以及相关的一些使用,分布式缓存的实现,基于binlog方式的修改等,接触有一年多了,这段时间下来,学了很多,以上算是一点小记,这部分工作的一点小记。实现过程中存在更多的问题。
对于调研相关的一些工作,一定要做的仔细,相应的细节一定要了解透彻,否则也许一此小问题会导致整个方案的不可行,甚至更大的的问题。连锁反应!
接下来有时间会写一篇关于BloomFilter的的文章 ,以及D-Left_BloomFilter,在此说明,只为自己有更大的动力去完成它。项目中实现了D-Left_BloomFilter,但在网上没有相关实现,在对其优化后,会在博文上做一些小小的记录。
以上如果有什么不对的地方请指正,有什么相关问题也可以跟我联系,可以一起交流学习!