目录
1、总体说明
1.1、采取redis的原因
1.2、平台总体架构
2、多协议支持方案
3、高可用(HA)方案
3.1、基础设施
3.2、故障检测
3.3、故障切换
4、分布式方案
4.1、垂直扩展
4.2、水平扩展
5、容量管理
6、安全
6.1、配置安全
6.2、访问安全
6.3、内置安全机制
7、运维和管理平台
7.1、集群和实例管理
7.2、监控
7.3、统计
7.4、管理工具
7.5、自监控
1、总体说明
以redis为底层存储设施,建设高性能、高可用、可扩展、易于运维和管理的缓存平台,以灵活满足各种缓存应用场景。

1.1、采取redis的原因
- 由VMWare支持,开发活跃。社区非常成熟,包括StackOverflow/暴雪/新浪微博/Flickr等公司广泛使用。
- 高性能:100k+TPS。
- 功能丰富。K/V存储的Value不仅仅支持string,还支持list、hash、set、sorted set。大量的原子操作。基本涵盖了memcached的功能。
- 支持经典的Master/Slave高可用部署架构,支持缓存内容的持久化。
redis提供的这些特性,便于达成我们的目标。在此之上,按照实际的业务需求,进行扩展和辅助工具的开发,建立完善的统一管理平台。
1.2、平台总体架构
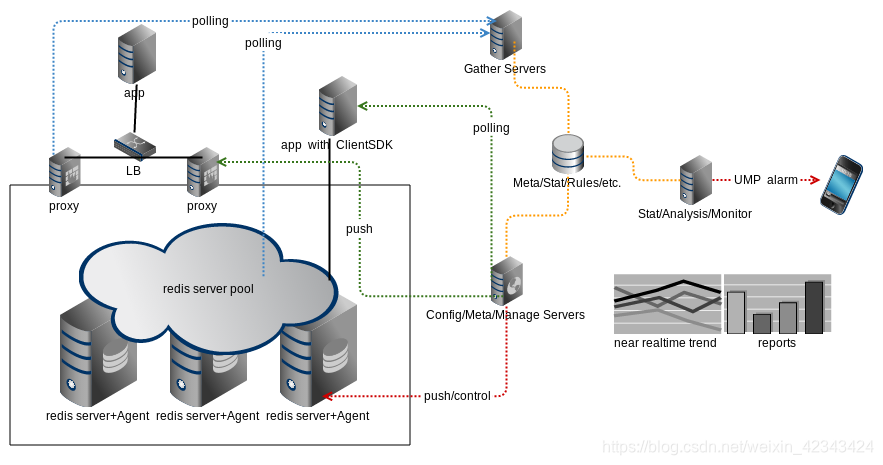
Redis server pool
独立部署一系列redis server或者将现有已经部署的redis server纳入管理,形成逻辑上统一的缓存资源池。
Gather servers
部署一系列分布式采集应用节点,分别对所有的redis server和redis proxy进行信息采集,存储的同时发送到实时监控服务。
监控服务
对采集传输的数据进行实时分析,使用预定义的一系列规则进行报警。
Stat/Analysis服务
部署一系列分布式统计应用节点,分别对原始采集数据进行准实时统计汇总并存储。原始采集信息统计完毕之后删除。集中存储所有的统计结果。统计节点本地系统同时存储本节点负责的统计结果,以便展现。
Config/Meta/Manage Servers
负责将变动的集群信息(节点拓扑、路由和读写策略等)push到相应的proxy。负责提供配置和元信息服务,以便应用端的Client SDK来polling变更。负责控制各个物理机上的Agent,对redis实例进行部署管理和配置文件同步。
Agent
部署在缓存资源池中各个物理机上,负责本机redis实例的部署和配置文件同步。
Client SDK
Client SDK为应用提供操作redis集群数据的API。利用polling到的集群配置元信息(节点拓扑、路由和读写策略等),访问后端的redis server节点。SDK负责监控配置信息变更(比如故障切换、服务节点迁移等),动态重启底层的连接池。对应用透明。
Proxy
Client SDK相对比较复杂,而且需要适应多种开发语言。因此可以把Client SDK的功能后移到中间的proxy层,通过proxy来对应用屏蔽这些复杂性。Redis proxy是实现了redis 协议的无状态的server,无论何种语言的redis客户端都可访问它。应用通过load balance设备来访问后端的多个proxy server。
管理平台
包括对以上各个组件的统一管理,以及一系列运维管理工具。
2、多协议支持方案
缓存平台对外提供的协议或接口,除了本身就支持的redis协议外,还可通过proxy中间件提供memcached、REST等协议。
虽然proxy方式比native直连方式性能要差,但也有优势:
- 底层实现可替换
- 满足多协议需求
- 屏蔽底层设施中复杂的分布式路由、故障切换、读写策略等
- 可以自由使用现成的多语言客户端
在性能完全满足业务需求的场景,可考虑使用proxy。否则,可使用专用的redis客户端SDK。
3、高可用(HA)方案
3.1、基础设施
底层支持:Master/Slave复制、AOF日志持久、RDB快照持久
扩展:jd-redis-dumper。
3.1.1、Master/Slave复制
典型部署场景
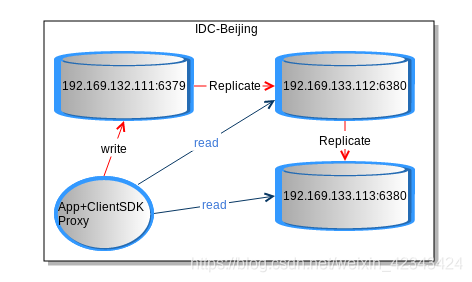
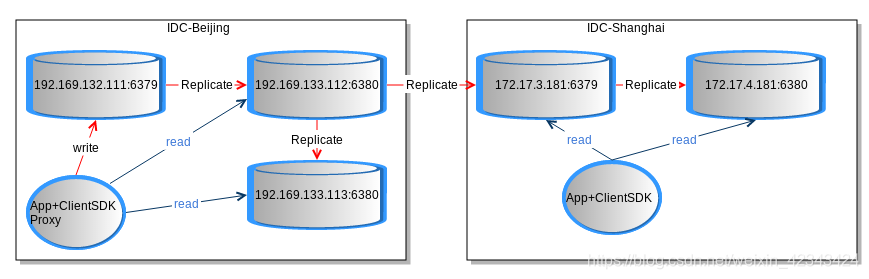
在运营经验上,链式复制优于1->n的复制方式。
通过跨机房复制,提高本地读性能。
复制机制
redis采用异步方式保证最大的复制效率,同时对master性能影响最小。不支持同步方式,而是通过复制的可靠性配置来保证数据的安全。
复制的可靠性(延时保证)
min-slaves-to-write <number of slaves> #最少需要存在slave数量才能允许写
min-slaves-max-lag <number of seconds> #slave落后master最大的秒数
一致性保证
slave-read-only true
3.1.2、AOF
将redis实例所有的写操作命令以redis协议文本格式追加到本机日志文件,通过replay日志来恢复数据。
可靠性保证
appendfsync always:每次追加日志同时都执行fsync持久到介质,最可靠,性能最差。
appendfsync no:只追加,不执行fsync。由操作系统保证高速缓存持久到介质,性能最高,可靠性依赖操作系统,有可能丢失尚未持久到介质的更新数据。
appendfsync everysec:每秒执行一次fsync,性能居中,最坏丢失的更新数据不超过2秒。
AOF整理
自动:auto-aof-rewrite-percentage <percent>,自动重新AOF以减少文件大小。
手动/定时:bgrewriteaof
3.1.3、RDB快照
将redis实例内存数据完整的持久到本机二进制快照文件,通过load快照文件恢复数据。
可靠性保证
stop-writes-on-bgsave-error no
策略
自动:save <after seconds> <if changes number>
手动/定期:bgsave
3.1.4、jd-redis-dumper
实现redis的复制协议的中间件。在跨机柜/交换机或者跨机房的主机上,将一个或多个实例的数据复制到jd-redis-dumper所在机器,并以AOF或RDB方式存储。通过远端的AOF和RDB来恢复数据。数据安全和Master/Slave一样,但是节约了内存资源,恢复速度要慢。
3.1.5、基础设施小结
从数据安全等级、故障恢复速度综合来看,优先级如下:
Master/Slave复制 > jd-redis-dumper > AOF > 快照
实践:
- 性能优先的关闭复制、AOF和快照;
- master关闭rdb/aof,使用slave replication
- slave上开启rdb+aof
- 读压力大的slave上关闭rdb+aof,通过jd-redis-dumper来备份
- 若开启复制或持久,预留一倍空闲内存
- 多实例时,由管理平台依次执行bgsave/bgrewriteaof,避免同时fork进程
3.2、故障检测
3.2.1、分布式采集器
zookeeper协调的多个采集器,定期收集所有集群和实例的info/config信息供准实时分析,同时发现故障实例,报告给故障决策组件。
3.2.2、存活报警策略
实例不存活报告次数,在某个时间范围内,到达指定值,则进行报警。
3.2.3、官方的Sentinel
分布式的故障检测组件,实践中不合适管理大量的集群。
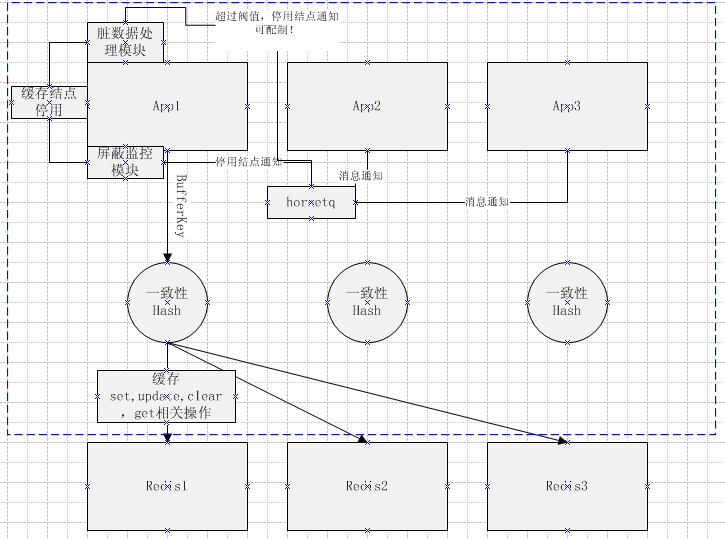
3.3、故障切换
当发生报警后,通过人工或者故障决策组件自动确认后,开始进行故障切换。只有AOF或者RDB的,通过Agent重启实例恢复数据。有Slave的,将Slave提升为主。
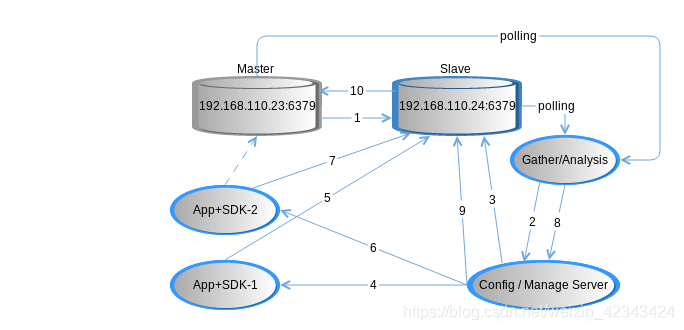
- 192.168.110.23:6379(Master)到192.168.110.24:6379(Slave)的连接故障;
- Gather/Analysis检测并分析到Master故障,Slave存活,将新的主从拓扑关系通知到Config Manage Server;
- Manage Server 更改192.168.110.24:6379(Slave)的slave-read-only false,并更新配置信息;
- App-1轮询到最新配置;
- App-1重启连接池连接到192.168.110.24:6379(Slave),发送读写请求;4
- App-2轮询到最新配置;
- App-2重启连接池连接到192.168.110.24:6379(Slave),发送读写请求;
- Gather/Analysis检测并分析到没有有效客户端连接到Master,通知Manage Server;
- Config/Manage Server同时确认客户端全都更新到最新配置(客户端心跳),则对192.168.110.24:6379(Slave)发送切换为Master的命令;
- 若192.168.110.23:6379(原Master)恢复存活,则设置为192.168.110.24:6379(新Master)的Slave,进行数据复制。
4、分布式方案
通过在本机或跨机部署多个实例形成一个逻辑上的集群,提高整体性能,减少单点故障。每个实例作为逻辑集群的一个分片(Sharding),承担部分数据的存储和读写请求。每个分片还可以配置对应的Slave,形成一个高可用分布式的集群方案。client/proxy按照key通过特定路由算法(比如一致性hash)请求特定的分片。
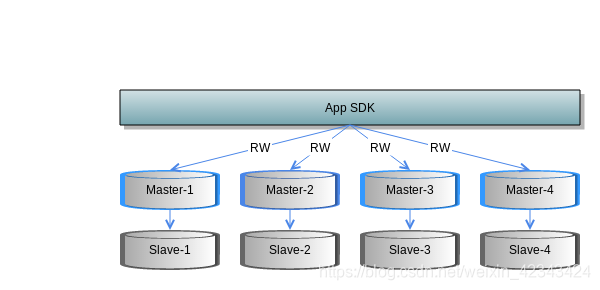
目前redis的最佳实践是pre-sharding + clientside routing来做分布式方案,其cluster方案还不成熟。
4.1、垂直扩展
pre-sharding,创建足够多的分片实例,部署在有限的几台物理机上。当缓存增长时,可通过扩大物理机内存,或将实例迁移到另外的物理机上,并扩大每个实例的最大内存设置,来达到整体扩容的目的。
故障切换流程同样适用于实例迁移。
4.2、水平扩展
当一个分片实例的内存容量增长到已经不合适放在一台物理机上时,势必要进行分片数量的增加。涉及到缓存数据的重新分布,可通过jd-redis-bridge来做。

5、容量管理
预先规划,合理配置。按照业务缓存数据增长量来提前规划分片数量,权衡成本和收益,配合垂直扩展和水平扩展来适应缓存的增长。
实践:
- 仔细设计数据结构和codec
- CPU不是瓶颈,内存和网络才是
- hash-max-zipmap-entries <n> / hash-max-zipmap-value <n>
- 设置maxmemory,设置预警规则
- 合理设置缓存项逐出策略
- 合理设置缓存项过期时间
6、安全
6.1、配置安全
屏蔽或修改危险命令:
- rename-command SHUTDOWN
- rename-command CONFIG youdontknow
6.2、访问安全
直连方式
ClientSDK通过token获取相应的集群拓扑配置。
Proxy方式
Redis的auth协议被用作client的token,proxy与后端server不需要认证。
6.3、内置安全机制
为redis实例配置passwd
7、运维和管理平台
7.1、集群和实例管理
- 集群/实例/应用元信息管理
- 可视化的集群拓扑图
- 访问令牌、配置管理
- Slowlog查看
- info/config信息查看
7.2、监控
- 针对集群实例、或者不同的角色(Master/Slave)的重点指标设置监控规则
- 全局规则/集群特有规则
7.3、统计
- 各集群重要指标的趋势
- 重要指标的TOPn
- 重要指标项按使用部分占比
- 重要配置项占比
7.4、管理工具
- 动态配置
- web端命令行
- 实时搜索特定指标或配置
- 实例迁移、故障切换、批量部署
- 可编排管理脚本(DSL风格)
7.5、自监控
缓存管理平台中各个组件的运行情况的监控。