一、ORM是什么?优势?
ORM:中文翻译为
对象关系映射。
模型类名对应数据库表名
类属性对象数据库表字典
类属性中的字段对应数据库中的约束条件
模型类的多个实例对应于实例
优势:
orm的技术特点,提高了开发效率,可以自动将模型对象与数据库中的Table进行字段与属性的映射;
不用直接写SQL,能够像操作对象一样从数据库中获取数据
二、get请求和post请求的区别
1、GET提交的数据会放在URL之后,以?分割URL和传输数据,参数之间以&相连,如EditBook?name=test1&id=123456. POST方法是把提交的数据放在HTTP包的Body中.
2、GET提交的数据大小有限制(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制.
3、GET与POST请求在服务端获取请求数据方式不同。
4、GET方式提交数据,会带来安全问题,比如一个登录页面,通过GET方式提交数据时,用户名和密码将出现在URL上,如果页面可以被缓存或者其他人可以访问这台机器,就可以从历史记录获得该用户的账号和密码.
三、简述django请求的生命周期?(非常重要)
整个流程是一个线程在处理的,线程结束了,httprequest请求才结束的;并不是有响应结果了,代表请求就结束了;
中间件:例如请求进来的时候记录下日志,请求出去的时候记录下中间件;
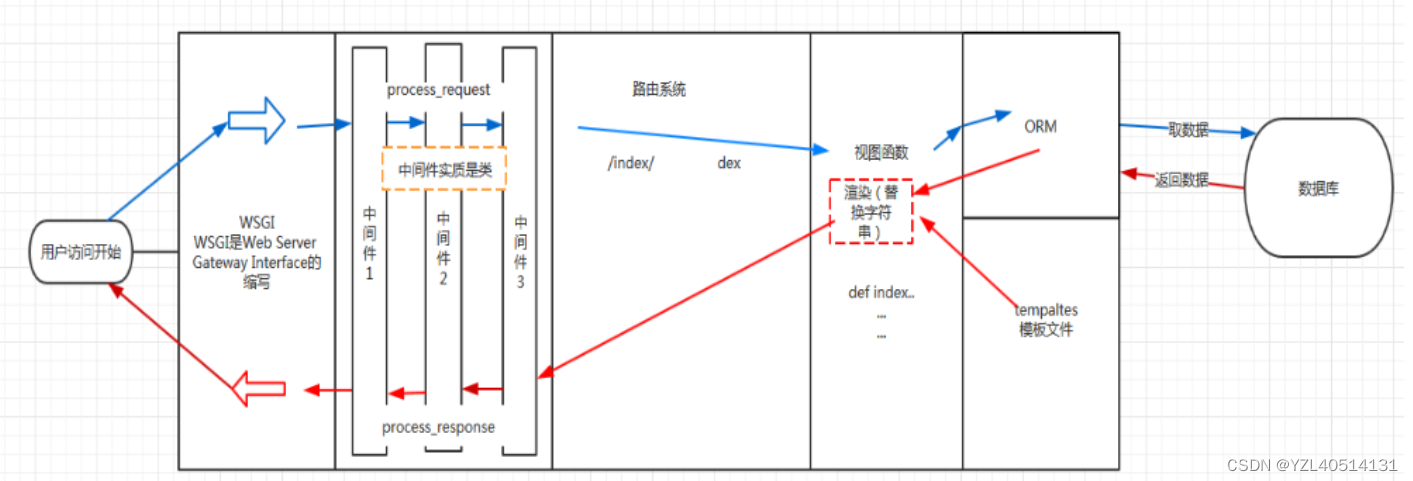
1、用户请求进来先走到 wsgi
2、wsgi作为桥梁将请求交给 django框架,首先到中间件(请求之前做什么事情,请求之后做什么事情)
3、穿过django中间件(方法是process_request) 后进行路由匹配
4、路由匹配成功之后就进入相应的 :视图函数或者类视图中
5、在视图函数中可以调用orm做数据库操作
6、将数据库返回的数据经过drf框架做相应的处理,转换为json格式的数据
7、将json格式或者html文件都将会封装成一个响应httpresponse
8、再把这个响应结果经过所有中间件(先进后出)和wsgi 返回给用户
四、Django重定向你是如何实现的?用的什么状态码?
path('project/',views.ProjectView)
path('interface/',views.InterfaceView,name='kobe')def ProjectView(request):url=reverse('kobe')return HttpResponseRedirect('')def InterfaceView(request):return Response('')
五、django中csrf的实现机制?
Django预防CSRF攻击的方法是在用户提交的表单中加入一个csrftoken的隐含值,这个值和服务器中保存的csrftoken的值相同,这样做的原理如下:
1、在用户访问django的可信站点时,django反馈给用户的表单中有一个隐含字段csrftoken,这个值是在服务器端随机生成的,每一次提交表单都会生成不同的值
2、当用户提交django的表单时,服务器校验这个表单的csrftoken是否和自己保存的一致,来判断用户的合法性
3、当用户被csrf攻击从其他站点发送精心编制的攻击请求时,由于其他站点不可能知道隐藏的csrftoken字段的信息这样在服务器端就会校验失败,攻击被成功防御
六、cookie和session的区别:
客户端请求服务器,如果服务器需要记录用户状态,就使用response向客户端浏览器颁发一个Cookie,客户端保存起来。
当浏览器再次请求网站时,浏览器把请求信息连同Cookie一同提交到服务器,服务器检查Cookie,以此来辨认用户得状态
session是记录客户状态得机制,不同的是Cookie保存在客户端,session保存在服务端。客户端浏览器访问服务器的时候,服务器把客户端信息保存在服务器上。客户端再次访问时只需要从Session中查找客户得状态就可以了。
七、什么是wsgi?(非常重要)
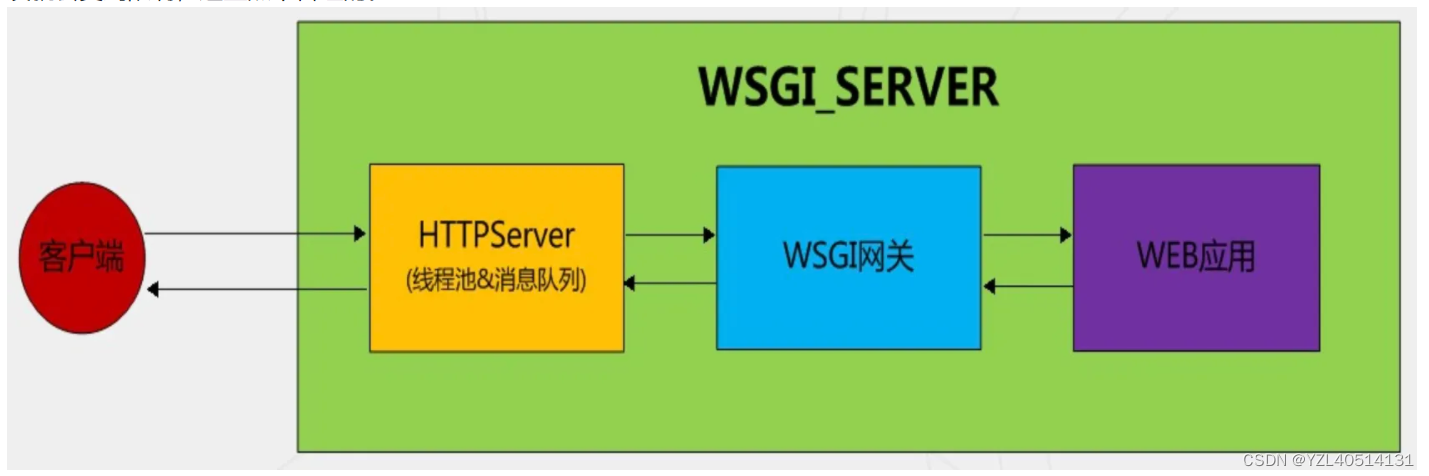
全称 Python Web Server Gateway Interface,指定了web服务器(nginx)和web框架之间的标准接口,以提高web应用在一系列web服务器间的移植性。
详细的说:
1、WSGI是一套接口标准协议/规范;
2、是作用在Web服务器和Python Web应用程序之间,用于通信;
3、目的是制定标准,以保证不同Web服务器可以和不同的Python框架之间相互通信
为什么需要wsgi呢?
当请求时Web服务器需要和web应用程序进行通信,但是web服务器有很多种啊,例如最新的是nginx,专门提供http服务的;Python web开发框架也对应多种啊,例如django、flask,专门开发web应用的;它们之间需要一个桥梁,所以WSGI应运而生,定义了一套通信标准。试想一下,如果不统一标准的话,就会存在Web框架和Web服务器数据无法匹配的情况,那么开发就会受到限制,这显然不合理的。
为什么pycharm中能直接运行django、flask项目呢?
因为内置了http服务
八、什么是中间件并简述其作用? 列举django中间件的5个方法?以及django中间件的应用场景?
中间件是一个用来处理Django的请求和响应的框架级别的钩子。它是一个轻量、低级别的插件系统,用于在全局范围内改变Django的输入和输出。每个中间件组件都负责做一些特定的功能。
中间件是介于request与response处理之间的一道处理过程,相对比较轻量级,并且在全局上改变django的输入与输出。
1、
process_request(self,request)先走request 通过路由匹配返回 ,例如做权限的验证,将权限的验证代码写到process_request(self,request) 中。验证不通过就不会执行视图函数了。
2、process_view(self, request, callback, callback_args, callback_kwargs)process_request(self,request) 函数之后,视图函数之前调用,再返回执行view ;
3、process_exception(self, request, exception)这个方法只有在视图函数中出现异常了才执行,它返回的值可以是一个None也可以是一个HttpResponse对象。
4、process_response(self, request, response)响应完毕,在传给客户端之前调用的方法;例如资源的回收,关闭日志文件
九、谈谈django的orm优化操作(非常重要)
1、尽可能的使用only与defer:Defer方法的用途是查询数据库时跳过指定的字段,only方法是指定需要载入的字段。从而节省空间。一行数据可能没啥关系,但数据很多时,节省的内存空间不可忽视。
2、select_related和prefetch_related都是做连表查询的:prefetch_related是查询了每个表,然后在语言层面进行连接,而select_related是通过join方法进行数据库的连接,所以select_related在查询的时候是比prefetch_related效率要高的,但是prefetch_related可以进行多对多的查询。
总结:可以理解为外键使用select_related,多对多使用prefetch_related。
3、在任何位置使用QuerySet.exists()或者QuerySet.count()都会导致额外的查询。
4、不要做无所谓的排序,排序并非没有代价,每个排序的字段都是数据库必须执行的操作。
5、如果要插入多条数据,则使用bulk_create来批量插入,减少sql执行的数量。
6、使用QuerySet.Iterator迭代大数据,要么使用分页。
7、复杂的查询(子查询),尽量采用原生SQL查询。
# 一、原生SQL ---> connection
from django.db import connection, connections
cursor = connection.cursor() # cursor = connections['default'].cursor()
cursor.execute("""SELECT * from auth_user where id = %s""", [1])
row = cursor.fetchone() # fetchall()/fetchmany(..) # 二、extra
def extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None) # 构造额外的查询条件或者映射,如:子查询 Entry.objects.extra(select={'new_id': "select col from sometable where othercol > %s"}, select_params=(1,)) Entry.objects.extra(where=['headline=%s'], params=['Lennon']) Entry.objects.extra(where=["foo='a' OR bar = 'a'", "baz = 'a'"]) Entry.objects.extra(select={'new_id': "select id from tb where id > %s"}, s elect_params=(1,), order_by=['-nid']) # 三、 raw函数
def raw(self, raw_query, params=None, translations=None, using=None): # 执行原生SQL models.UserInfo.objects.raw('select * from userinfo') # 如果SQL是其他表时,必须将名字设置为当前UserInfo对象的主键列名 models.UserInfo.objects.raw('select id as nid,name as title from 其他表') # 为原生SQL设置参数 models.UserInfo.objects.raw('select id as nid from userinfo where nid>%s', params=[12,]) # 将获取的到列名转换为指定列名 name_map = {'first': 'first_name', 'last': 'last_name', 'bd': 'birth_date', 'pk': 'id'} Person.objects.raw('SELECT * FROM some_other_table', translations=name_map) # 指定数据库 models.UserInfo.objects.raw('select * from userinfo', using="default")
十、django中如何实现orm表中添加数据时创建一条日志记录?(非常重要)
Django 中的一些常用内置信号。与Model 相关的信号,这些信号由各个 Model 的方法发送,如 save、__init__等,且通常都是成对出现的,如下所示:
1、django.db.models.signals.
pre_init与 django.db.models.signals.post_init:实例化模型之前与之后发送的信号,即在__init__方法执行的前后。
2、django.db.models.signals.pre_save与 django.db.models.signals.post_save:模型实例保存(执行save方法)前后发送的信号。
3、django.db.models.signals.pre_delete与 django.db.models.signals.post_delete:模型实例或 QuerySet 的 delete() 方法执行前后发送的信号。
4、django.db.models.signals.m2m_changed:模型实例中的ManyToManyField(多对多)字段被修改(add,remove,clear)的前后发送的信号。
十一 Django的MVT模式与MVC模式
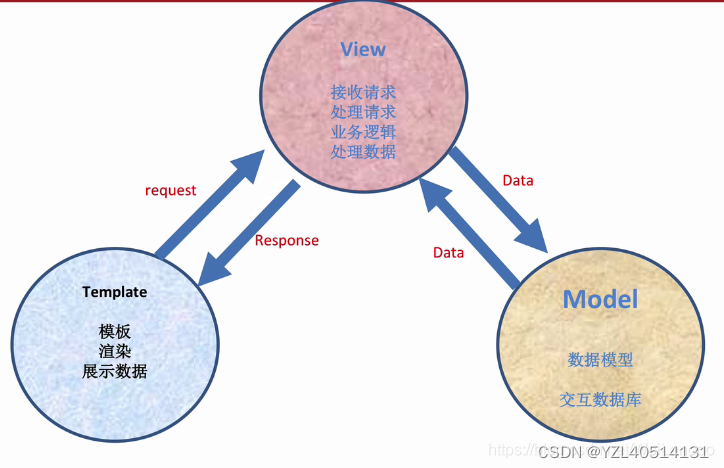
MVT
M全拼为Model,与MVC中的M功能相同,负责和数据库交互,进行数据处理。
V全拼为View,与MVC中的C功能相同,接收请求,进行业务处理,返回响应。
T全拼为Template,与MVC中的V功能相同,负责封装构造要返回的html。
MVT执行顺序
1,客户端发出请求,与关系型数据库进行交互
2,路由接收请求,根据请求地址查找视图
3,视图接收,处理 找到相应的Model(数据交互)
4, 与关系型数据库进行交互 取得数据
5,将取到的数据返回给Model
6,将数据交给view进行处理
7,将数据套入到需要的template,封装相对应的html,css,js编写的模板语言
8,将封装好的模板语言返回给view进行处理
9,客户端接受结果进行渲染html和css 执行js
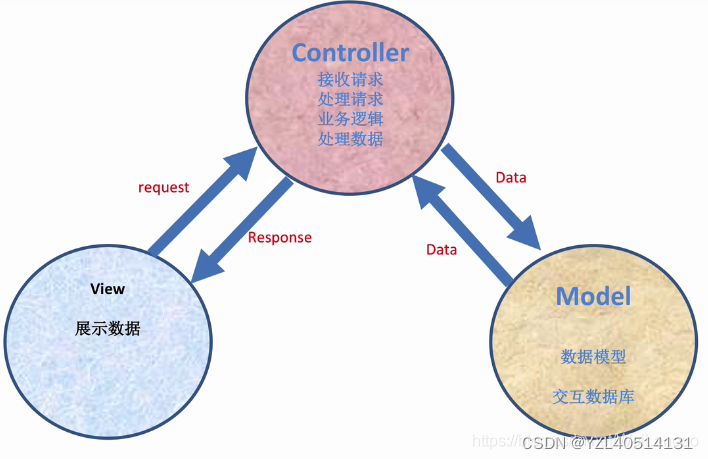
MVC
M全拼为Model(模块),主要封装对数据库层的访问, 数据处理,对数据库中的数据进行增、删、改、查操作。
V全拼为View(视图),界面显示,用于封装结果,生成页面展示的html内容。
C全拼为Controller(控制器),逻辑处理,用于接收请求,处理业务逻辑,与Model和View交互,返回结果。
MVC执行流程
1,客户端发出请求
2,controll,接收请求,进行业务处理 发送给Model
3, 与关系型数据库进行交互 取得数据
4,将取到的数据返回给Model
5,将数据交给controller.进行处理
6,将数据给view进行响应response封装
7,返回封装好response给controll
8,controll返回给客户端进行渲染HTML和css执行js
十二、django中怎么写原生SQL(非常重要)
使用extra:
queryset=NewsChannel.objects.filter(name__contains='美').extra(where=['id>4'])queryset=NewsChannel.objects.extra(where=["name='美女' OR name='体育'","url='/sport/'"])
使用raw
queryset=NewsChannel.objects.raw('select id from app3_news_channel where id>%s',params=[3])# 一、原生SQL ---> connection
from django.db import connection
cursor = connection.cursor()
cursor.execute("SELECT * from auth_user where id = %s", [1])
row = cursor.fetchone() # fetchall()/fetchmany(..)
十三、如何使用django orm批量创建数据(非常重要)
如果要插入多条数据,则使用bulk_create来批量插入,减少sql执行的数量。
postman上传excel文件
读取excel数据,并使用bulk_create批量插入数据
from openpyxl import load_workbook
from rest_framework.decorators import action
from rest_framework.response import Response
from rest_framework.viewsets import ModelViewSet
from app3.serializers import *class NewsChannelsAPIView(ModelViewSet):queryset = NewsChannel.objects.all()serializer_class = NewsChannelSerializer@action(methods=['POST'],detail=False)def create1(self,request):file_obj = request.FILES.get("file")cases = [] # 用来存储所有用例titles = [] # 保存标题excel_obj=load_workbook(file_obj) # 获取工作簿对象ws = excel_obj.worksheets[0]print(ws.rows)for i ,row in enumerate(ws.rows):if i == 0:for cell in row:titles.append(cell.value)else:cases.append(dict(zip(titles, [cell.value for cell in row])))querysetList=[]for i in cases:querysetList.append(NewsChannel(id=i['id'],name=i['name'],url=i['url']))NewsChannel.objects.bulk_create(querysetList)print(querysetList)data={'msg':'success'}return Response(data)
十四、Django中当用户登录到A服务器进入登陆状态,下次被nginx代理到B服务器会出现什么影响
如果用户在A应用服务器登陆的session数据没有共享到B应用服务器,那么之前的登录状态就没有了。
十五、跨域请求Django是如何处理的(非常重要)
什么是同源?
url由协议、域名、端⼝和路径组成;如果两个url的协议、域名和端⼝相同,则这两个url是同源的。
同源目的?
同源政策的⽬的,是为了保证⽤户信息的安全,防⽌恶意的⽹站窃取数据。
例如:
前端和后端分别是两个不同的端⼝
前端:127.0.0.1:8081
后端:192.168.17.129:8880
现在,前端与后端分别是不同的端⼝,不同的ip,这就涉及到跨域访问数据的问题,因为浏览器的同源策略,默认是不⽀持两个不同域名间相互访问数据,⽽我们需要在两个域名间相互传递数据,这时我们就要为后端添加跨域访问的⽀持。
步骤:
1 安装 :
pip install django-cors-headers
2 注册子应用 ```corsheaders
INSTALLED_APPS = [
…
‘corsheaders’,
…
]
3 中间件配置
MIDDLEWARE = [
‘corsheaders.middleware.CorsMiddleware’,
…
]
4 添加⽩名单
CORS_ORIGIN_WHITELIST = ( 'http://127.0.0.1:8081','http://127.0.0.1:8080', 'http://localhost:8080', 'http://www.nagle.cn:8080', 'http://api.nagle.cn:8083',
)
CORS_ALLOW_CREDENTIALS = True # 允许携带cookie
凡是出现在⽩名单中的域名,都可以访问后端接⼝CORS_ALLOW_CREDENTIALS 指明在跨域访问中,后端是否⽀持对cookie的操作。
十六、urlpatterns中的name与namespace有什么作用?你是如何使用的?

十七、如何设置一个带有枚举值的字典?
class NewsChannel(models.Model):GENDER_CHOICE=[(1,'体育频道'),(2,'音乐频道'),(3,'科技频道')]'''新闻频道'''id=models.AutoField(primary_key=True)name=models.CharField(max_length=30,unique=True,verbose_name='频道名称')url=models.CharField(default='',null=True,blank=True,max_length=50,verbose_name='频道页面链接')status=models.SmallIntegerField(max_length=5,choices=GENDER_CHOICE,default=1)class Meta:db_table='app3_news_channel'verbose_name='新闻频道'verbose_name_plural=verbose_name
十八、DateTimeField类型中的auto_now与auto_now_add有什么区别
auto_now:用于更新时间;这个参数的默认值为false,设置为true时,能够在保存该字段时,将其值设置为当前时间,并且每次修改model,都会自动更新。
如果使用django再带的admin管理器,那么该字段在admin中是只读的。
auto_now_add:用于创建时间,这个参数的默认值也为False,设置为True时,会在model对象第一次被创建时,将字段的值设置为创建时的时间,以后修改对象时,字段的值不会再更新。
auto_now_add也具有强制性,一旦被设置为True,就无法在程序中手动为字段赋值,在admin中字段也会成为只读的。
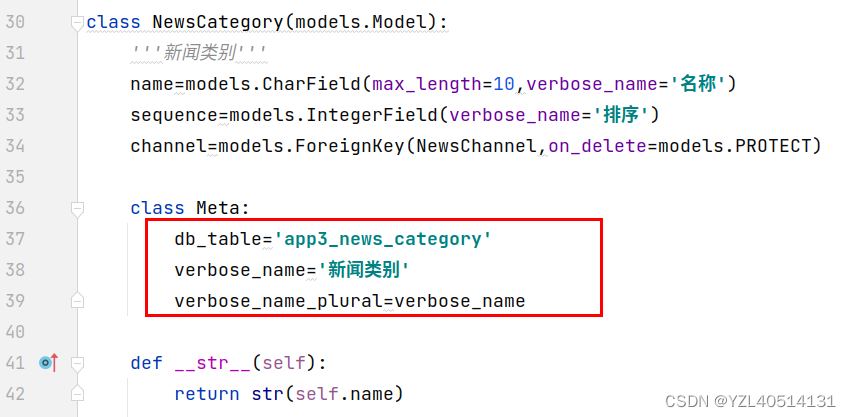
十九、class Meta中的元信息字段有哪些
二十、Django 本身提供了 runserver,为什么不能用来部署?
runserver 方法是调试 Django 时经常用到的运行方式,它使用 Django 自带的 WSGI Server 运行,主要在测试和开发中使用,并且 runserver 开启的方式也是单进程 。