观看王树森老师的课程之后的一些记录,视频地址如下:
ShusenWang的个人空间_哔哩哔哩_BilibiliShusenWang,Educator;ShusenWang的主页、动态、视频、专栏、频道、收藏、订阅等。哔哩哔哩Bilibili,你感兴趣的视频都在B站。 https://space.bilibili.com/1369507485?spm_id_from=333.788.b_765f7570696e666f.1讲解清晰透彻,推荐给大家(#^.^#)
https://space.bilibili.com/1369507485?spm_id_from=333.788.b_765f7570696e666f.1讲解清晰透彻,推荐给大家(#^.^#)
基本概念
小样本学习与传统的监督学习有所不同,其目标不是让机器识别训练集里的图片并泛化到测试集,而是让机器自己学会学习。也就是说需要让机器学会理解事物间的异同,区分不同的事物。比如输入两张图片,不需要让模型识别出来两张图片是什么,而是要区分出这两张图片是相同的东西还是不同的东西。


(训练集中没有松鼠这个类别,训练后模型并不知道识别出来的东西是松鼠,但是可以判断这两张图片很可能是相同的东西)

support set是meta learning中的概念,将这些带标签的图片称作support set。
training set和support set的区别:training set的规模很大,每一个类别下面都有很多图片。由于训练集足够大,所以可以用来训练一个深度神经网络;相比之下,support set很小,每一个类别下面只有一张或者几张图片,不足以训练一个大的神经网络,因此support set只能在预测时提供一些额外信息。
用足够大的数据集来训练一个大模型,训练目的不是用来识别出目标类别,而是要知道事物间的异同。现在靠support set提供的少量信息,模型就可以判断出query图片是水獭,尽管训练集里没有水獭这个类别。
Few-shot Learning and Meta Learning
· 小样本学习可以看做是元学习的一种
· 元学习的目标是“学会学习”

Supervised Learning vs. Few-shot Learning
监督学习:

小样本学习:


k-way support set 中有k各类别; n-shot 每个类别有n个样本
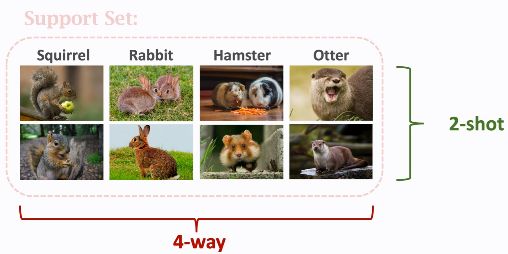
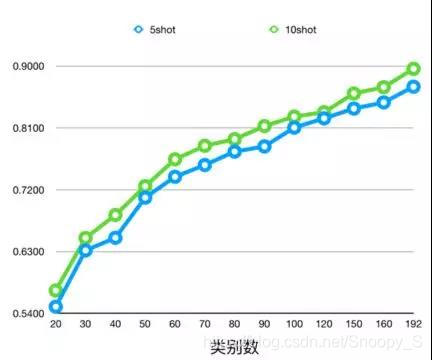
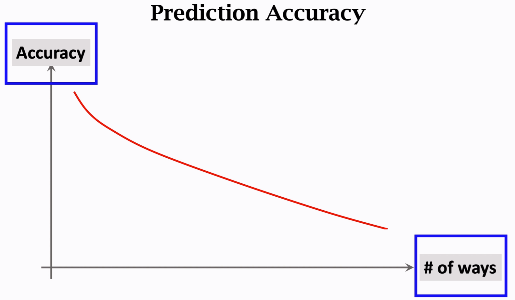
通常来说,类别数越多,样本数越少,分类准确度越低
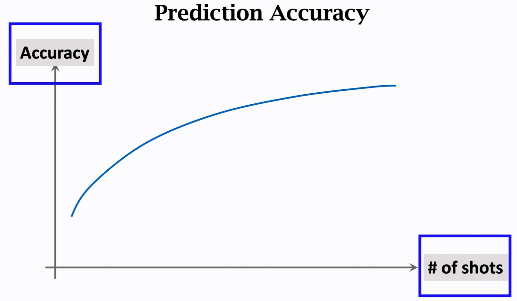
Idea:Learn a Similarity Function

1. 在大数据集上学习一个相似度函数
2.用学习的相似度函数做预测,给一个query图片,与support图片逐一做对比计算相似度,扎弄出相似度最高的作为计算结果

Siamese Network
训练方法1:每次取两个样本,比较它们的相似度
每次取两张图片作为训练样本,标签为0(不同类)或1(同类),孪生网络输出一个介于0~1之间的相似度数值,把标签与预测之间的差别作为损失函数。训练目标是让预测尽量接近标签,这样训练出的网络可以判别两个样本间的相似度。两个图片越相似,神经网络的输出值越接近于1。
 选取数据
选取数据
 搭建神经网络
搭建神经网络

(相同类别输出接近1,不同类别输出接近0)将标签与预测的差别作为损失函数

训练方法2:Triplet Loss
每次选取三张图片作为输入样本,一个锚点(anchor) xa,正样本x+和负样本x-,用神经网络提取特征得到三个特征向量,将锚点与正样本间的距离记做d+,锚点与负样本之间的距离记做d-,训练目标是让d+尽量小,d+尽量大。有了这种神经网络就可以提取特征,比较图片在特征空间上的距离,从而做出小样本分类。
 选取数据
选取数据


使d+尽量小,d-尽量大(使d-比d+大至少α)

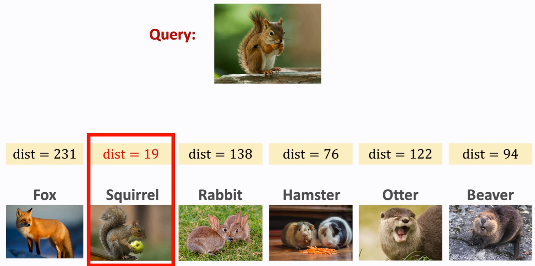
使用神经网络提取特征得到每个类别的特征向量,给一个query图片,比较特征向量之间的距离。
总结:
①用一个大的数据集来训练孪生网络,让网络知道事物间的异同
②训练结束后,可以用孪生网络做预测,解决小样本问题
③由于query的类别不在训练集中,所以还需要额外的信息来识别图片,也就是support set。将query与support set中的样本做对比,将距离最小或相似度最高的作为分类结果。
Pretraining and Fine Tuninig
在大规模数据集上预训练,在小数据集上微调
Cosine Similarity


softmax 函数
将向量映射成概率分布,让最大的值变大,最小的值变小。


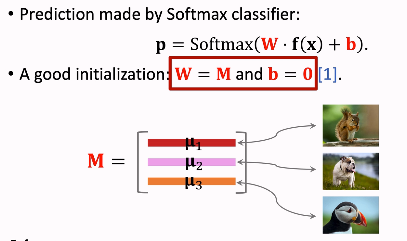
softmax分类器:全连接层+softmax函数

(k是类别数量,d是特征数量)W的每一行对应一个类别
Few-shot Prediction Using Pretrained CNN
Pretraining

搭建一个神经网络用来提取特征,输入是一张图片x,输出是提取的特征向量f(x)
可以用传统的监督学习训练网络,训练完成后去掉全连接层;也可以使用孪生网络。
用训练的神经网络做小样本预测

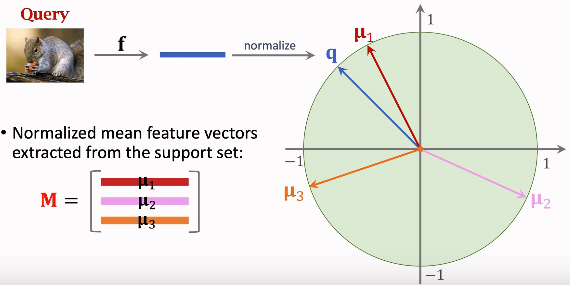
分类时,将query的特征向量分别与μ1μ2μ3做对比

Fine-Tuning


yj是真实标签,pj是分类器做出的预测
Trick
1.初始化设置 W=M ; b=0
2.正则化防止过拟合 Entropy Regularization

3.Cosine Similarity + Softmax Classfier
在求w与q的内积之前做一个归一化,把两个向量的二范数变为1

总结: