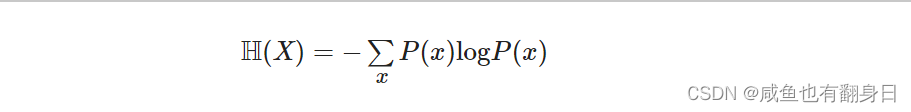融合零样本学习和小样本学习的弱监督学习方法综述
人工智能技术与咨询

来源:《系统工程与电子技术》,作者潘崇煜等
摘 要: 深度学习模型严重依赖于大量人工标注的数据,使得其在数据缺乏的特殊领域内应用严重受限。面对数据缺乏等现实挑战,很多学者针对数据依赖小的弱监督学习方法开展研究,出现了小样本学习、零样本学习等典型研究方向。对此,本文主要介绍了弱监督学习方法条件下的小样本学习和零样本学习,包括问题定义、当前主流方法以及实验设计方案,并对典型模型的分类性能进行对比。然后,给出零-小样本学习的问题描述,总结研究现状和实验设计,并对比典型方法的性能。最后,基于当前研究中出现的问题对未来研究方向进行展望,包括多种弱监督学习方法的融合与理论基础的探究,以及在其他领域的应用。
关键词: 弱监督学习; 小样本学习; 零样本学习; 零-小样本学习
0 引 言
近年来,深度学习模型在诸多领域取得了引人瞩目的成就,如图像分类、语音识别、棋类对弈等。然而,包括深度学习在内,以大数据为基础的传统监督学习模型严重依赖于大量人工标注的高质量标签数据,在很多领域内,由于数据缺乏,使得这些模型很难取得应有成效。针对数据缺乏的现实情况,当前很多研究[1-2]关注数据依赖性小的弱监督学习方法,如小样本学习、零样本学习等。
小样本学习试图在有限样本条件下实现对新类别或新概念的有效认知。通过度量学习、样本生成等途径,已有一些方法在少量支持样本情况下实现了新概念识别。尽管取得了一定成效,但每个新类别中的几个支持样本仍然难以准确表征整个类别的特征分布,这使得小样本学习任务仍然充满了挑战性。
相对于小样本学习,零样本学习试图识别训练过程中从未见过的新类别概念。这需要额外的语义特征辅助信息,如训练集和待分类的测试集类别语义特征描述向量,借此实现从训练集向测试集类别的知识迁移。由于其内在固有的域适应及枢纽度问题[3],零样本学习也面临着识别精度不高等问题。
基于零样本学习和小样本学习面临诸多的问题,正如文献[3]指出,在当前小样本学习中融合额外的语义文本信息是一个重要的研究方向,即零-小样本学习。零-小样本学习既包含了小样本学习中若干支持样本特征,同时考虑了语义特征辅助信息,可以有效提高弱监督机器学习的识别性能,同时也更加符合人类对新概念、新事物举一反三、多方融合的认知原理。
本文从小样本学习和零样本学习入手,重点开展了问题描述、典型方法介绍、实验设计以及性能对比。基于小样本学习和零样本学习之间的信息互补,本文介绍了零-小样本学习这一新问题。在此基础上,本文指出了多种弱监督学习方法融合发展、基础理论探索以及多领域上扩展等重要发展方向。
1 小样本学习
小样本学习旨在通过有限样本对新的类别或者概念进行识别,本节首先给出明确问题描述,之后回顾目前主流方法和模型,最后介绍具体的实验设计和部分基准结果。
1.1 问题描述
给定由Ns个训练样本构成的训练集
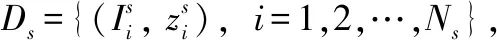
其中是第i个样本图像;是其类别标签,Cs是训练集标签集合;Ds通常由大量训练样本构成。
在测试阶段,对于新的类别Ct (测试类别与训练集类别不同,即Cs∩ Ct=∅),每个类别给定几个支持样本
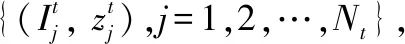
小样本识别的任务是对新的测试样本图像进行识别,确定其对应的类别标签
1.2 当前主流模型
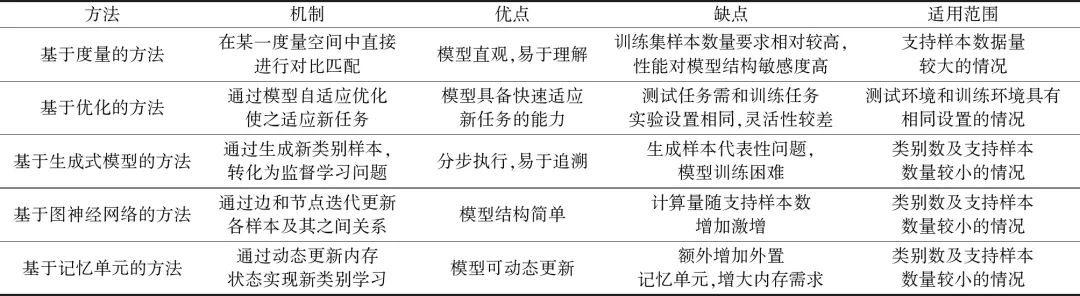
小样本学习领域目前已经出现很多方法和模型,这些方法可以概括为基于度量的方法、基于优化的方法、基于生成式模型的方法、基于图神经网络的方法以及基于记忆单元的方法。表1对这几种主流方法进行了简要列举和分析。
表1 不同的小样本学习方法对比分析
Table 1 Comparision analysis of the different methods for few-shot learning
(1) 基于度量的方法
基于度量的方法核心思想是学习样本之间的相似度。孪生网络[4]是最早的基于度量学习的小样本学习模型,该模型通过卷积神经网络(convolutional neural network, CNN)直接学习两个样本之间的相似度。之后,文献[5]提出了基于元学习的匹配网络,元学习是一种训练策略,具体算法流程如表2所示。
表2 元学习训练范式
Table 2 Training paradigm of the meta-learning

匹配网络利用了双向长短时记忆(long short-term memory, LSTM)网络模型以及注意力机制来学习样本之间的度量函数。原型网络[6]也是一种典型的度量学习模型,将图像特征映射到一度量空间中,在该空间中,将同类多个样本均值作为代表该类别的原型样本点,对于待识别的样本,通过在多类的原型样本点之间进行最近邻距离实现分类,该方法直接用欧氏距离作为距离度量,仅学习图像编码网络。值得一提的是,文献[7-8]提出了包含图像编码模块及关系度量模块的关系网络,原始图像经过CNN编码模块形成图像特征向量,之后待测试样本与支持样本连接形成图像对,经过关系网络度量每一图像对的相似度。如图1所示[7],该模型同时学习编码网络和度量函数,与以往使用某一固定度量函数不同,该模型通过训练学习了一个非线性的度量函数,提高了模型的适应性。
基于度量的小样本学习方法模型通常较为直观,易于理解,具备较强的可解释性,但往往需要大量训练数据,对于训练集样本数量要求较高,且最终性能对模型结构敏感度较高,模型细节设计对性能影响较大。
(2) 基于优化的方法
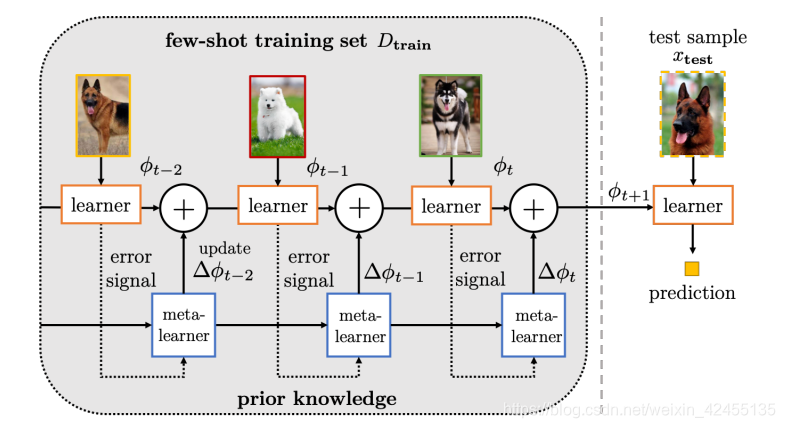
基于优化的方法依据元学习的思想,旨在学习一组元分类器,这些分类器可以在新的任务上通过参数微调实现较好的分类性能。最典型的优化方法是模型无关元学习(model-agnostic meta-learning, MAML)算法[9],如图2所示,该方法通过大量训练数据学习到一组好的初始化参数,在新任务测试时,仅通过很少的参数迭代步数,模型即可自适应到该新任务上。基于元学习思想,之后又出现了很多基于优化的小样本学习方法,包括meta network[10]、meta-SGD[11]、meta-learner LSTM[12]以及其他变种[13]。
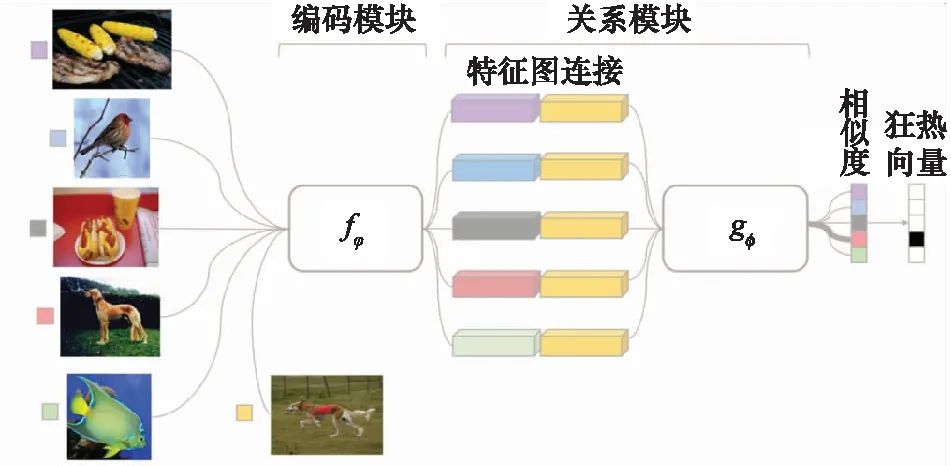
图1 基于度量的小样本学习模型-关系网络
Fig.1 Metric based model for few-shot learning-relation network
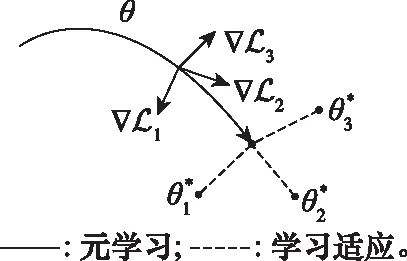
图2 基于优化的小样本学习方法-MAML算法
Fig.2 Optimization based method for few-shot learning-MAML algorithm
基于优化的小样本学习模型具备快速适应新任务的能力,但却存在明显的缺陷,即模型只能在固定任务上预训练和迁移,如在5-way 1-shot分类任务上训练的模型只能适应5-way 1-shot的任务,缺乏灵活性。
(3) 基于生成式模型的方法
基于大量训练数据以及少量的支持样本,生成式模型期望生成大量新类别数据样本,进而将小样本学习转化为传统的监督学习。生成式模型通常由自动编码器以及其他学习模型构成[14]。典型的生成式模型如图3所示[15]。

图3 基于生成式模型的小样本学习方法
Fig.3 Generative model based method for few-shot learning
通过类比训练集中多个样本之间的特征差异,在少量支持样本的基础上,生成器试图在新类别上生成更多样本。随后,在生成样本基础上训练常规分类器进行新类别识别。近年来,随着生成对抗网络(generative adversarial network, GAN)[16]的出现,基于GAN的小样本学习模型[17]也层出不穷。
基于生成式模型的方法通常分为样本生成和分类器训练两部分分步进行,易于追溯,但却存在生成样本可信度不高、模型训练困难等问题。
(4) 基于图神经网络的方法
在图神经网络模型[18]中,以单个样本作为节点(Node),以样本间相似度作为边(Edge),通过神经网络模型迭代计算图模型的连接矩阵。如图4所示,以所有样本的特征向量作为节点状态,以样本间关系为边,迭代更新节点状态向量和邻接矩阵,最终推断出待识别样本与所有支持样本的相似度[19]。
由于将每个样本作为一个高维向量节点进行动态更新,基于图神经网络的方法[19-20]在模型训练过程中会消耗大量内存空间,同时计算量会随着样本数量增加而激增。
![]()
图4 基于图神经网络的小样本学习方法
Fig.4 Graph neural network based method for few-shot learning
(5) 基于记忆单元的方法
基于外挂的记忆单元模块,一些方法试图通过在学习过程中持续更新内存状态来实现小样本学习甚至持续学习[21],典型方法包括记忆增强网络(memory augmented neural network, MANN)[22]、记忆匹配网络(memory matching network, MMN)[23]等。
基于记忆单元的小样本学习方法模型,如图5所示,可动态更新,但需额外增加外置记忆单元,增大了内存需求,同时也增加了如读写控制器等复杂模型组件[22]。
![]()
图5 基于记忆单元的小样本学习-MANN
Fig.5 Memory unit based method for few-shot learning-MANN
1.3 实验设计
(1) 数据集
当前,小样本学习的公共数据集主要是Omniglot以及miniImagenet。其中,Omniglot[24]是手写字符符号数据集,包含50个大类,共1 623个类别符号,每个类别只有20个样本图像。miniImagenet[5]是图像领域公共数据集ImageNet的一部分,包含100个类别,每个类别包含600个图像样本,在小样本学习中具体划分为64类用于训练集,16类用于验证集,其余20类用于测试集。
(2) 实验设置
如表2所示,小样本学习普遍采用元学习训练范式,在训练阶段和测试阶段构建分类子任务,称为M-way N-shot Q-query分类子任务,即每一个实验轮次中,对于M类分类类别,每一类别提供N个支持样本,同时提供Q个测试样本用于参数调整(训练阶段)或准确率评估(测试阶段)。在模型训练阶段,通过多个轮次迭代,实现模型参数的调整。在模型测试阶段,采用多个轮次分类准确率取平均值的方法,评估模型最终的分类准确率。当前研究通常在Omniglot数据集上采用5/20-way 1/5-shot的分类子任务,在miniImagenet数据集上采用5-way 1/5-shot的分类子任务。
表3 几种典型小样本学习模型在miniImagenet数据集上的性能对比
Table 3 Performance evaluations of the several typical models for few-shot learning on miniImagenent data sets
![]()
(3) 典型方法性能对比
表3列出了小样本学习领域当前几种典型模型在miniImagenet数据集上的识别准确率对比。可以看出,大部分方法在5-way 1-shot分类识别中都取得了超过50%的准确率,表明仅依靠少量标签样本识别新类具有一定的实践性。同时,随着支持样本的增加(由1-shot增加为5-shot),识别率取得了明显的提高,表明支持样本数量对最终识别效果有决定性作用。最后,不同模型不仅设计思想及模型构成不同,而且在图像处理中最基本的特征提取器结构也存在很大区别(如表3特征提取器所列),因此模型性能之间存在较大差异。
2 零样本学习
零样本学习[29-30]旨在通过文本描述信息对新的类别或者概念进行识别,本节首先给出明确问题描述,之后回顾目前主流方法和模型,最后介绍具体的实验设计和部分基准结果。
2.1 问题描述
给定由Ns个训练样本构成的训练集,![]() 其中
其中![]() 是第i个样本图像,
是第i个样本图像,![]() 是其类别标签,Cs是训练集标签集合。零样学习的任务是对测试样本
是其类别标签,Cs是训练集标签集合。零样学习的任务是对测试样本![]() 进行识别,将其划分到新的类别Ct中,即确定其对应的类别标签
进行识别,将其划分到新的类别Ct中,即确定其对应的类别标签![]() 其中测试类别与训练集类别不同,即Cs∩Ct=∅。除此之外,零样本学习为所有类别提供了额外的文本信息作为特征描述,即为Cs和Ct中的每个类别
其中测试类别与训练集类别不同,即Cs∩Ct=∅。除此之外,零样本学习为所有类别提供了额外的文本信息作为特征描述,即为Cs和Ct中的每个类别![]() 提供了一个类别特征描述向量
提供了一个类别特征描述向量![]()
借助于通用的类别特征描述向量,零样本学习期望实现从已知的训练样本类别到新的测试样本类别之间的知识迁移。在零样本学习中,类别描述向量作为知识迁移的桥梁,通常是由人工标注的属性向量构成,如形状、颜色、尺寸、材质等训练集和测试集类别通用属性,也有一些研究使用文本理解领域成熟的词向量作为特征描述向量[3]。
2.2 当前主流模型
针对零样本学习问题,国内外学者提出了很多方法,整体上可分为度量学习方法、相似度学习方法、基于流形结构的方法以及基于生成式模型的方法。表4对这几种主流方法进行了简要列举和分析。
表4 不同零样本学习方法对比分析
Table 4 Comparisions of the different methods for zero-shot learning

(1) 度量学习方法
度量学习方法旨在找到一个度量空间,在该空间中样本的图像特征和其对应的语义向量在某种度量下距离最小。最基本的方法是直接将语义向量空间作为度量空间[31-33],将图像特征映射到语义向量空间,在该空间中进行最近邻分类,直接使用欧氏距离或者余弦距离作为度量函数。有研究表明[34],将图像特征空间作为度量空间,能够有效减轻零样本学习中固有的域适应以及枢纽度问题[3]。在此基础上,以图像特征空间作为度量空间的深度嵌入模型(deep embedding model, DEM)[35-36]等模型被提出,如图6所示[35],原始图像经过CNN网络编码到图像特征空间,语义向量经多层感知机(multi-layer perceptron, MLP)映射到同一特征空间,在该度量空间中基于最近邻分类。除了图像特征以及语义特征空间本身,一些方法探索了寻找隐空间作为度量空间,如EXEM[37]、隐性属性字典(latent attribute dictionary, LAD)[38]学习、耦合字典学习(coupled dictionary learning, CDL)[39]、公共嵌入空间[40-41]以及共享特征相对属性空间[42]。在这些方法中,除了度量空间不同,空间映射函数也各有不同,包括线性变换[31,38-39,43]以及非线性变换,如支持向量回归(support vector regression, SVR)[37]以及神经网络模型[35]。度量学习方法中最重要的问题是设计目标(损失)函数,关系到模型的整体性能。
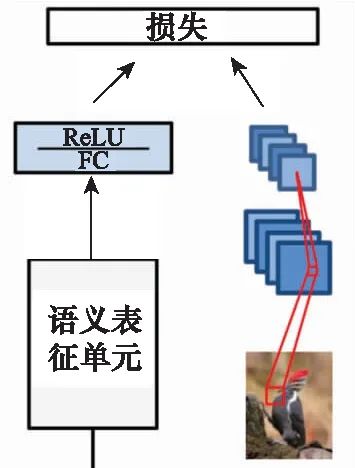
图6 基于度量的零样本学习
Fig.6 Metric based zero-shot learning
基于度量学习的方法在某一特征空间中基于最近邻规则进行分类,模型直观、易于理解,然而模型性能因度量空间选择而变化较大,适用于训练集数量较大的情况。
(2) 兼容性学习方法
与学习空间映射函数不同,兼容性学习方法直接学习图像空间和语义空间向量的相似度。最基本的方法是直接利用双线性函数将图像空间和语义空间向量转换为相似度标量,如极端零样本学习采样方法(embarrassingly sample approach to zero-shot learning, ESZSL)[44]、 深度图像-嵌入语义(deep visual-semantic embedding, DeViSE)模型[45]、 结构化联合嵌入(structured joint embedding,SJE)[46]以及属性标签嵌入(attribute label embedding, ALE)[47]。其他一些方法利用了非线性的函数转换,如隐形嵌入(latent embedding, LatEm)[48]以及关系网络[7]。
基于兼容性学习的方法模型如图7所示[46],较为简单,计算量较小,但对训练集数据量要求较高。

图7 基于兼容性的零样本学习
Fig.7 Compatibility based zero-shot learning
(3) 基于流形结构的方法
一些研究从流形学习[49]的角度出发,探索语义空间与图像特征空间的流形结构,企图通过学习训练集中的流形结构,迁移到新的测试类别中去。如图8所示,模型在语义空间中学习各个类别特征向量间的流形结构,基于流形学习思想,将该结构迁移到视觉特征分类器模型空间中。典型方法包括跨模态迁移(cross-modal transfer, CMT)[50]、数据遗失问题(missing data problem, MDP)[51]、语义嵌入凸组合(convex combination of semantic embeddings, CONSE)[52]、双向隐形嵌入(bidirectional latent embedding, BiDiLEL)[53]、相关知识迁移(relational knowledge transfer, RKT)[54]、生成分类器(synthesized classifiers, SYNC)[49]以及局部敏感的流形保持方法[55]。
基于流形结构的零样本学习方法[49],如图8所示,能够考虑到类别间的关联关系,但不同特征空间的流形结构存在异构性,通常难以迁移。
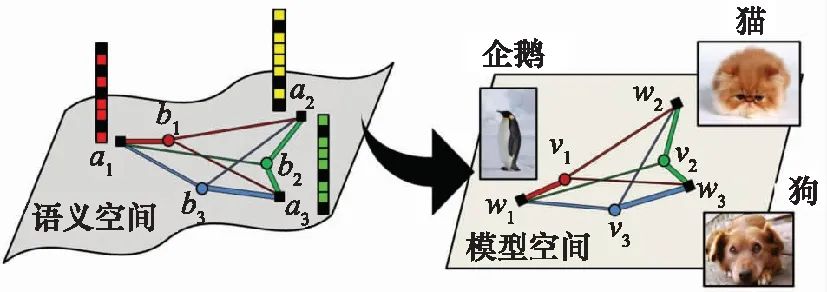
图8 基于流形结构的零样本学习
Fig.8 Manifold structure based zero-shot learning
(4) 基于生成式模型的方法
最近一些研究基于生成样本的思想,借助于生成式网络,经训练集训练,在新类别上生成图像特征样本甚至原始二维图像,将零样本学习转化为监督学习分类问题加以解决。典型方法包括未知类别样本生成(unseen visual data synthesis, UVDS)[56]、ZSL对抗生成式方法(generative adversarial approach for ZSL, GAZSL)[57]、特征生成网络(feature generating networks, FGN)[58]、ZSL样本生成方法(synthesized examples ZSL, SE-ZSL)[59]、保留语义的对抗式嵌入网络(semantics-preserving adversarial embedding networks, SP-AEN)[60]等。
基于生成式模型的方法[61],如图9所示。
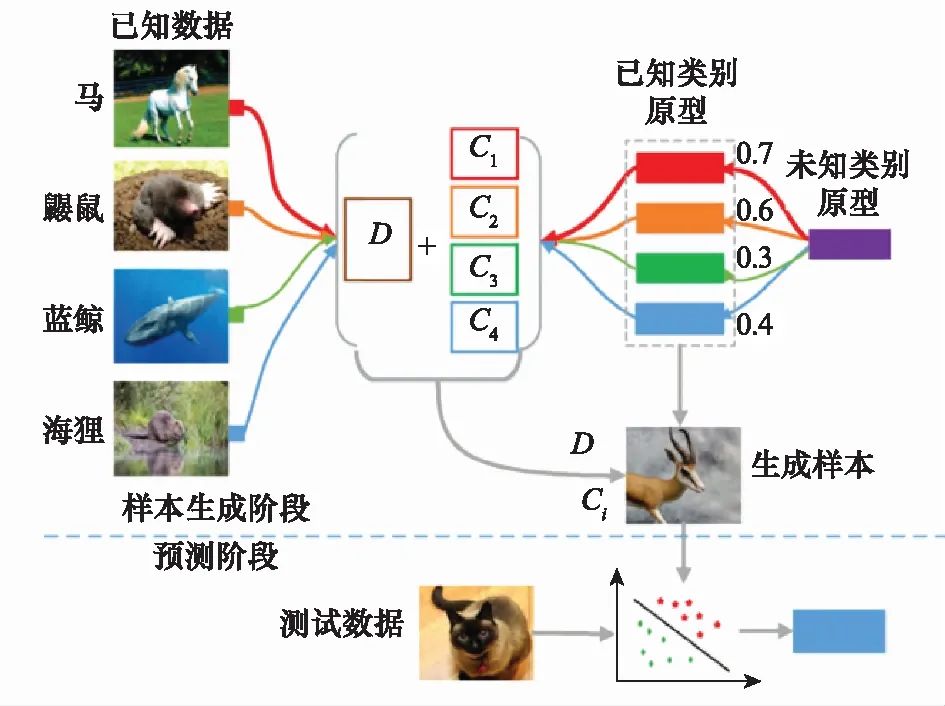
图9 基于生成式模型的零样本学习
Fig.9 Generative model based zero-shot learning
该方法通常分为样本生成和分类器训练两部分。在样本生成阶段,基于训练样本及其对应的文本描述信息,在新类别文本描述向量条件下,生成新类别的图像样本。在分类器训练阶段,基于生成的样本训练分类器并对测试样本进行在线识别。基于生成式模型的方法分步进行,易于追溯,但同样存在生成样本代表性不高、模型训练困难等问题。
2.3 实验设计
(1) 数据集及实验设置
当前零样本学习研究中常用的数据集包括动物属性标记(animals with attributes, AWA)[62]数据集、CUB(CUB-200-2011)[63]以及ImageNet 2010[64]等。表5详细列出了这些数据集统计信息以及在零样本学习中的固定测试集/训练集类别数划分。
表5 零样本学习常用数据集
Table 5 Data sets for zero-shot learning
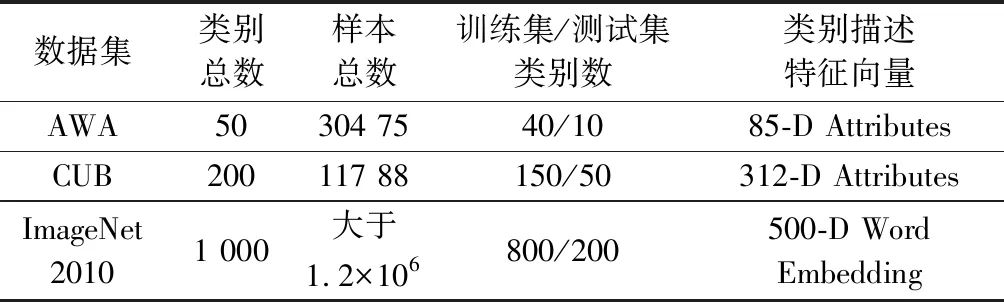
关于类别描述特征向量,AWA和CUB数据集分别包含85维和312维的类别属性描述向量(Attributes),对于ImageNet 2010大型数据集,当前研究多采用大规模无标签文本训练词向量(Word Embedding)的方式,为每个类别生成高维的词向量表征[49]。
值得注意的是,在零样本学习中,由于缺少大量标签数据训练图像特征提取网络,当前研究中,图像特征通常采用预训练的CNN图像特征,即调用在miniImageNet数据集上预训练的CNN模型,在训练集/测试集图像上直接提取特征,常用的预训练模型包括GoogLeNet[65]以及VGGNet[66]等。
零样本学习中,训练集和测试集类别不同,在训练集上训练模型,在测试集类别中进行性能评估,通常采用分类任务,以分类准确率作为模型评估指标。
(2) 典型方法性能对比
表6列出了零样本学习领域当前几种典型模型的分类性能对比。可以看出,在仅有新类别语义特征描述的情况下,模型能够实现新概念识别分类,在AWA数据集10分类问题上取得了高达约90%的准确率,在CUB数据集50分类问题上取得了高达60%的准确率,甚至在ImageNet大型数据集200分类问题上取得了超过60%的Top 5准确率。与小样本学习类似,不同方法不仅模型设计思想不同,而且底层图像特征提取器结构也有所不同,因此各方法之间存在较大性能差异。
表6 几种典型零样本学习模型的分类性能对比
Table 6 Classification performance comparisons of the several typical models for zero-shot learning
![]()
3 零-小样本学习
与小样本学习和零样本学习类似,零-小样本学习借助于通用的类别特征描述,在少量支持样本条件下实现对新类别或概念的识别,本节首先给出明确问题描述,其次介绍当前的研究现状,最后介绍具体的实验设计和部分基准结果。
3.1 问题描述
给定由Ns个训练样本构成的训练集![]() 其中,
其中,![]() 是第i个样本图像,
是第i个样本图像,![]() 是其类别标签,Cs是训练集标签集合,
是其类别标签,Cs是训练集标签集合,![]() 是类别
是类别![]() 对应的类别特征描述向量。Ds通常由大量训练样本构成。
对应的类别特征描述向量。Ds通常由大量训练样本构成。
基于上述训练集,零-小样本学习旨在分类识别新类别样本。在测试阶段,对于每一个新类别提供了少量支持样本

且所有的新类别的特征描述向量是已知的。对于给定的测试样本零-小样本学习的任务是识别其类别标签
3.2 研究现状
为了更好地识别训练过程中未见过的新类别,一些学者在小样本学习的基础上增加类别属性特征描述向量,探索了文本信息辅助的小样本学习问题,即本文所述的零-小样本学习。
文献[47]最早提出融合零样本学习和小样本学习是提高机器智能的有效途径。之后,零-小样本学习问题逐渐被关注[56],并且出现了初步的研究工作。其中,文献[48]设计了多注意力网络,借助语义特征描述,利用图像局部特征,研究了语义信息辅助的小样本学习。基于生成式模型的思想,文献[47]提出对偶三角网络,基于类别语义信息生成新的样本特征;文献[70]在变分自编码器模型中增加多模态交叉配准损失函数,在新的隐特征空间中生成更多新样本,提出跨模态分布式变分自编码器(cross-modal and distribution aligned variational autoencoder, CADA-VAE), 实现了零-小样本条件下的数据增强。尽管出现了很长时间,但零-小样本学习领域尚未被充分研究。以上部分工作仍然依赖于预训练的CNN图像特征,在一些特定领域内,标签数据有限,难以开展预训练工作,这些方法的可行性较差。
值得一提的是,最近的研究工作[71]为零-小样本学习提供了有益探索。自适应模态混合机制(adaptive modality mixture mechanism, AM3)模型如图10所示。
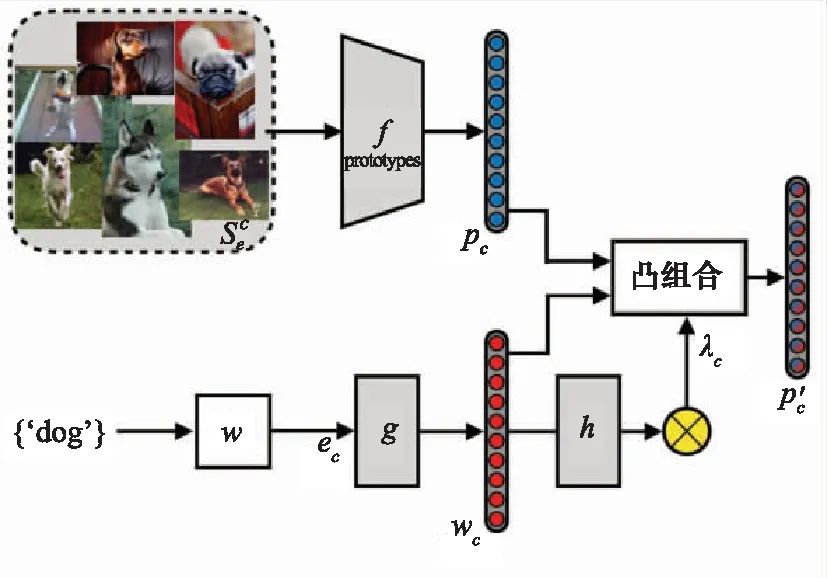
图10 零-小样本学习模型(AM3)
Fig.10 Model (AM3) for zero-to-few shot learning
包含图像流和文本流两条路径,上部分表示图像信息流,下部分表示文本信息流,通过可自适应调整的权重因子加权,形成最终的类别原型。该模型提出了多模态信息自适应利用机制,可以在文本特征和图像特征中自适应调节权重因子,借助于跨模态信息来增强小样本学习性能。
3.3 实验设计
(1) 数据集及实验设置
当前零-小样本学习仍处于初始探索阶段,相关的研究十分有限。在零-小样本学习中,除了若干新类别支持样本外,还需要额外的类别语义特征描述向量作为辅助信息。当前研究主要是在miniImageNet[6]以及tieredImageNet[72]数据集上展开,其类别语义信息是通过预训练词向量提取得到的。
与小样本学习类似,零-小样本学习也采用表1所列的元学习训练范式。在训练阶段,通过已知类别的训练样本图像、类别标签以及类别描述向量训练模型参数。在测试阶段,在少量新类别支持样本及其类别描述向量信息辅助下,对大量测试样本进行分类识别,并统计识别正确率,作为最终的模型评价指标。当前常用的实验设置为5-way 1/5-shot 图像分类子任务。
(2) 典型方法性能对比
表7列出了零-小样本学习典型方法的分类性能。可以看出,在语义特征信息辅助下,仅提供1个支持样本就可以在miniImageNet数据集上取得65%的识别率。除各方法使用的图像特征提取器结构不同之外,值得一提的是,DeViSE, 鲁棒半监督视觉语义嵌入(robust semi-supervised visual-semantic embeddings, ReViSE)以及CADA-VAE模型使用了预训练的CNN图像特征,而AM3系列方法是端到端的模型参数训练,无需使用预训练图像特征。
表7 几种典型零-小样本学习模型在miniImagenet及tieredImageNet数据集上的分类性能
Table 7 Classification performance evaluations of the several typical models for zero-to-few-shot learning on the data sets of miniImagenet and tieredImageNet

4 未来研究方向
4.1 多种弱监督学习方法融合发展
当前弱监督机器学习研究主要集中在零样本学习以及小样本学习上,而对于文本信息辅助的零-小样本学习研究还很薄弱。零-小样本学习既包含了少量支持样本,同时又融合了文本信息,具备跨模态学习的独特优势,相对于零样本学习和小样本学习,性能获得了显著提升[71,73]。从人类认知角度看,人类识别新类别或者新概念会通过少数样本归纳总结,同时结合多种认知模式进行综合理解,如“未见其人,先闻其声”“字如其人”等都是多种认知模式综合作用的结果。综合实际需求和学术研究,零-小样本学习将是弱监督学习和人类认知结合的重要研究方向。
除此之外,零样本学习可以和主动学习相结合,提升主动学习效果。零样本学习可以融入到终身学习系统中,在仅有相关信息描述的情况下,持续学习新的任务。当前,强化学习迅速发展,结合弱监督机器学习,强化学习系统可以更好地应对新任务、新场景,甚至新领域。
4.2 弱监督机器学习的理论基础探究
当前,弱监督机器学习领域内研究大多在统一数据集下展开,甚至训练集/测试集的划分都是固定的。如零样本学习实验中,绝大多数研究在AWA数据集采用固定40类训练,指定10类测试;在CUB上固定150类训练,指定50类测试。实验数据相对固定,在这种数据设置下训练的模型在其他数据上的有效性,即模型的泛化能力值得考究。可考虑使用传统大规模数据集训练的有效方式,如5折交叉验证等方式来进行弱监督机器学习实验验证,充分测试模型在多种数据条件下的综合性能。
同时,实验设置应当更加切合实际应用,如当前小样本和零样本学习大多只在未见过的新类别上进行分类性能测试,然而在实际应用中,往往测试样本来源于新类别以及训练集中的类别,如何提升这种广义分类问题上的性能也是重要的研究方向。
另一方面,尽管零样本和小样本学习对于训练数据的数目要求很低,但是前期的模型预训练直接影响其最终性能,当前大多数模型繁琐复杂,如何在保证正确率的前提下,尽量降低模型复杂度也是非常值得研究的工作。
当前的研究主要是启发式探索和验证性实验,缺乏足够的理论基础,对于一些关键问题需要开展更多的理论分析,如零样本学习中如何选择辅助性信息,从训练集向未见过的测试样本迁移过程中,什么信息和知识更有效,在学习过程中,如何抑制不相关信息,避免负向迁移等。科学的理论分析和充足的实验证明将更有益于弱监督机器学习发展。
4.3 弱监督机器学习在其他领域任务上的应用
当前的弱监督机器学习研究主要集中在计算机视觉领域,包括字符识别、图像分类等。这主要得益于视觉信息易于获取,且在传统深度学习领域已有大量研究,很多成熟的技术可直接迁移到弱监督学习中来。当前针对几个主流的实验数据集,如miniImageNet等,已经取得了很高的识别率,性能提升空间很小。因此,应当开发更广泛的任务应用,如图像检索、目标跟踪、手势识别、图像标注、视觉问答、视频事件检测等。例如,如何将从粗粒度的动物分类任务中学习到的知识迁移到细粒度的狗品种分类任务中去。另外,应当从多种数据源获取大规模度多样化数据集,设置更加切近现实应用的实验基准。
除了计算机视觉,弱监督机器学习应当逐步扩展到其他领域。在自然语言处理中,可针对文本翻译、语言建模等开展研究;在推荐系统方面,依据少量样本进行相关推荐是一个值得研究的课题;在医学研究中,罕见药品发现将为医药研制提供创新途径。尤其是在机器人控制领域,依靠少量人工指导甚至依靠传统经验进行增强学习的智能学习方法将为机器人复杂运动规划与控制提供有效途径,当前典型的应用包括小样本模仿学习、视觉导航、机器人运动连续控制等。
5 结束语
本文从弱监督机器学习方法入手,主要介绍了小样本学习、零样本学习的问题定义,当前主流方法以及实验设计方案,之后给出了零-小样本学习问题描述及当前研究现状,最后对下一步研究方向进行了总结展望。

我们的服务类型
公开课程
人工智能、大数据、嵌入式
内训课程
普通内训、定制内训
项目咨询
技术路线设计、算法设计与实现(图像处理、自然语言处理、语音识别)