1 编辑分片配置文件
#redis.host=192.168.126.129
#redis.port=6379
redis.nodes=192.168.126.129:6379,192.168.126.129:6380,192.168.126.129:63812 编辑配置类实现redis整合
@Configuration //我是一个配置类 一般都会与@Bean联用
@PropertySource("classpath:/properties/redis.properties")
public class RedisConfig {@Value("${redis.nodes}")private String redisNodes; //node,node,node/*整合分片实现Redis内存扩容*/@Beanpublic ShardedJedis shardedJedis() {String[] nodes = redisNodes.split(","); //节点数组//动态获取Redis节点信息.List<JedisShardInfo> list = new ArrayList<JedisShardInfo>();for (String node : nodes) { //node= host:port ---->[host,port]String host = node.split(":")[0];int port = Integer.parseInt(node.split(":")[1]);list.add(new JedisShardInfo(host, port));}//返回分片对象return new ShardedJedis(list);}/*** 单台测试@Value("${redis.host}")private String host;@Value("${redis.port}")private Integer port;//将返回值的结果交给spring容器进行管理,如果以后想要使用该对象则可以直接注入.@Beanpublic Jedis jedis() {return new Jedis(host, port);}*/
}3 修改RedisAOP中的注入

4 关于redis分片总结
1.当redis节点宕机之后,用户访问必然受到影响.
2.当redis服务宕机之后,该节点中的数据可能丢失
3.Redis分片可以实现内存数据的扩容.
4.Redis分片机制中hash运算发生在业务服务器中.redis只负责存取.不负责计算. 所以效率更高.
2 Redis属性说明
2.1 Redis持久化策略
2.1.1 Redis持久化策略说明
说明: Redis的数据都保存在内存中,如果断电或者宕机,则内存数据将擦除,导致数据的丢失.为了防止数据丢失,Redis内部有持久化机制.
当第一次Redis服务启动时,根据配置文件中的持久化要求.进行持久化操作.如果不是第一次启动,则在服务启动时会根据持久化文件的配置,读取指定的持久化文件.实现内存数据的恢复.
2.1.2 RDB模式
特点:
1.rdb模式是redis中默认的持久化策略.
2.rdb模式定期持久化.保存的是Redis中的内存数据快照.持久化文件占用空间较小.
3.rdb模式可能导致内存数据丢失
命令:
前提:需要在redis的客户端中执行.
- save 命令 立即持久化 会导致其他操作陷入阻塞.
- bgsave 命令 开启后台运行. 以异步的方式进行持久化. 不会造成其他操作的阻塞.
持久化周期:
save 900 1 900秒内,如果用户执行的1次更新操作,则持久化一次save 300 10 300秒内,如果用户执行的10次更新操作,则持久化一次save 60 10000 60秒内,如果用户执行的10000次更新操作,则持久化一次save 1 1 1秒内,如果用户执行的1次更新操作,则持久化一次 set 阻塞!!!!持久化文件:

持久化文件路径:

2.1.3 AOF模式
特点:
1). AOF模式默认条件下是关闭状态. 如果需要开启则需要修改配置文件.
2). AOF模式可以实现数据的实时持久化操作,AOF模式记录的是用户的操作过程.
3). 只要开启了AOF模式,则持久化方式以AOF模式为主.
配置:
开启AOF持久化方式

持久化文件格式:

持久化文件名称配置:

持久化文件策略说明
appendfsync always 只要用户执行一次操作,则持久化一次.**appendfsync everysec 每秒持久化一次 默认策略** 效率略低于RDBappendfsync no 不主动持久化.2.1.4 面试题
公司新入职一个员工,对于业务不熟,出于好奇在生产环境下执行了flushAll命令,问:如果你是项目经理,如何解决 ??
A: 暴打一顿 驱逐出公司
B: 冷嘲热讽 让其主动离职 ,并且承担后果
C: 予以安慰,告诉他你是最棒的 之后去甲方负荆请罪
D: 相视一笑,告诉他 你别管了 交给我处理吧 .
处理方式:修改AOF文件中的flushAll命令,之后重启即可.
2.1.5 持久化总结
1.如果用户允许少量的数据丢失,则可以选用RDB模式. 效率更高
2.如果用户不允许数据丢失,则选用AOF模式.
3.可以2种方式都选, 需要搭建组从结构 , 主机选用RDB模式, 从机选用AOF模式,可以保证业务允许.
2.1.6 配置多种持久化方式
1).设计 : 6379 当主机 7380当从机.
2).修改主机的配置文件:
要求: 主机使用RDB模式

从机使用AOF模式

3).检查默认模式的状态
命令: info replication

4).实现主从挂载
编辑从服务器向主机进行挂载

4).主从测试
1.主机中添加测试数据.
2.检查从机中是否有数据
3.检查持久化文件是否有数据.
总结: 一般条件下主机采用RDB模式,从机采用AOF模式,效率更高.
2.2.Redis内存策略
2.2.1 内存策略说明
redis服务器运行在内存中,数据也在内存中保存. 如果一直往里存,总有一天内存资源不够用,所以需要研究如何优化内存.
2.2.2 LRU算法
维度:T 时间
LRU是Least Recently Used的缩写,即最近最少使用,是一种常用的页面(数据)置换算法,选择最近最久未使用的页面(数据)予以淘汰。该算法赋予每个页面(数据)一个访问字段,用来记录一个页面(数据)自上次被访问以来所经历的时间 t,当须淘汰一个页面(数据)时,选择现有页面(数据)中其 t 值最大的,即最近最少使用的页面(数据)予以淘汰。
2.2.3 LFU算法
维度:引用次数
LFU(least frequently used (LFU) page-replacement algorithm)。即最不经常使用页置换算法,要求在页置换时置换引用计数最小的页,因为经常使用的页应该有一个较大的引用次数。但是有些页在开始时使用次数很多,但以后就不再使用,这类页将会长时间留在内存中,因此可以将引用计数寄存器定时右移一位,形成指数衰减的平均使用次数。
2.2.4 随机算法
随机算法: 灭霸的响指
2.2.5 TTL算法
说明: 将设定了超时时间的数据提前删除.
2.2.6 Redis中内存优化策略
- volatile-lru 设定超时时间的数据采用lru算法
- allkeys-lru .所有的数据采用lru算法
- volatile-lfu 设定超时时间的数据采用LFU算法
- allkeys-lfu 所有的数据才能lfu算法
- volatile-random 设定了超时时间的数据采用随机算法
- allkeys-random 所有数据采用随机算法
- volatile-ttl 设定超时时间的数据采用TTL算法
- noeviction 该配置为模式配置 表示内存满时 只报错,不删除数据.

修改配置文件之后,重启服务器即可.
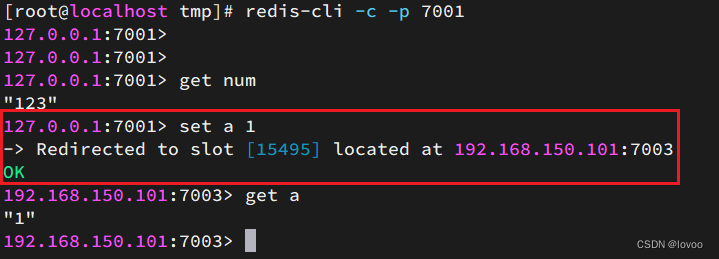
2.3 Redis集群
2.3.1 redis集群搭建问题解决方案
1.检查防火墙
2.检查配置文件
3.关闭所有的redis服务器 sh stop.sh
4.删除多余的文件 nodes.conf dump.rdb
[root@localhost cluster]# rm -rf 700*/dump.rdb
[root@localhost cluster]# rm -rf 700*/nodes.conf5.重新启动服务器,之后执行挂载命令
2.3.2 redis入门案例
public class TestCluster {/*** 通过程序操作redis 3主机 读写 3从机 数据备份 */@Testpublic void test01() {Set<HostAndPort> nodes = new HashSet<HostAndPort>();nodes.add(new HostAndPort("192.168.126.129", 7000));nodes.add(new HostAndPort("192.168.126.129", 7001));nodes.add(new HostAndPort("192.168.126.129", 7002));nodes.add(new HostAndPort("192.168.126.129", 7003));nodes.add(new HostAndPort("192.168.126.129", 7004));nodes.add(new HostAndPort("192.168.126.129", 7005));//利用程序操作redis集群JedisCluster jedisCluster = new JedisCluster(nodes);jedisCluster.set("AAAAA", "redis集群测试");System.out.println(jedisCluster.get("AAAAA"));}
}