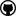JPEG中使用了量化、哈夫曼编码等,极大的压缩了图片占用的空间,那么是否可以进一步压缩呢?
从技术角度讲,是可以的。如DropBox开源的lepton,在目前的JPEG压缩基础上,可以再节省22%左右的空间。
lepton中使用算术编码(VP8)替换哈夫曼编码,以得到更高的压缩率。算术编码90年代已经出现,但是受限于专利,没有被广泛使用。同样由于专利限制没有广泛使用的还有gif中的压缩编码lzw。
下面介绍一下,算术编码的基本原理和过程。
算术编码( Arithmetic coding )发展历史
1948 年,香农就提出将信源符号依其出现的概率降序排序,用符号序列累计概率的二进值作为对信源数据的编码,并从理论上论证了它的优越性。
1960 年, Peter Elias 发现无需排序,只要编、解码端使用相同的符号顺序即可,提出了算术编码的概念。 Elias 没有公布他的发现,因为他知道算术编码在数学上虽然成 立,但不可能在实际中实现。
1976 年, R. Pasco 和 J. Rissanen 分别用定长的寄存器实现了有限精度的算术编码。
1979 年 Rissanen 和 G. G. Langdon 一起将算术编码系统化,并于 1981 年实现了二进制编码。
1987 年 Witten 等人发表了一个实用的算术编码程序,即 CACM87 (后用 于 ITU-T 的 H.263 视频压缩标准)。同期, IBM 公司发表了著名的 Q- 编码器(后用于 JPEG 和 JBIG 图像压缩标准)。从此,算术编码迅速得到了广泛的注意。
算术编码介绍
算术编码是一种无损数据压缩方法,也是一种熵编码的方法。
一般的熵编码方法通常是把输入的消息分割为符号,然后对每个符号进行编码。而算术编码将整个要编码的数据映射到一个位于 [0,1) 的实数区间中。利用这种方法算术编码可以让压缩率无限的接近数据的熵值,从而获得理论上的最高压缩率。
算术编码用到两个基本的参数:符号的概率和它的编码间隔。信源符号的概率决定压缩编码的效率,也决定编码过程中信源符号的间隔,而这些间隔包含在 0 到 1 之间。编码过程中的间隔决定了符号压缩后的输出。
算术编码可以是静态的或者自适应的。
在静态算术编码中,信源符号的概率是固定的。在自适应算术编码中,信源符号的概率根据编码时符号出现的频繁程度动态地进行修改,在编码期间估算信源符号概率的过程叫做建模。
需要开发动态算术编码的原因是因为事先知道精确的信源概率是很难的,而且是不切实际的。当压缩消息时,我们不能期待一个算术编码器获得最大的效率,所能做的最有效的方法是在编码过程中估算概率。因此动态建模就成为确定编码器压缩效率的关键。
算术编码思想
算术编码的基本原理是将编码的消息表示成实数 0 和 1 之间的一个间隔( Interval ),消息越长,编码表示它的间隔就越小,表示这一间隔所需的二进制位就越多。
算术编码进行编码时,从实数区间 [0,1) 开始,按照符号的频度将当前的区间分割成多个子区间。根据当前输入的符号选择对应的子区间,然后从选择的子区间 中继续进行下一轮的分割。不断的进行这个过程,直到所有符号编码完毕。对于最后选择的一个子区间,输出属于该区间的一个小数。这个小数就是所有数据的编码。
给定事件序列的算术编码步骤如下:
( 1 )编码器在开始时将 “ 当前间隔 ” [ L , H) 设置为 [0 , 1) 。
( 2 )对每一个输入事件,编码器按下边的步骤( a )和( b )进行处理
( a )编码器将 “ 当前间隔 ” 分为子间隔,每一个事件一个。一个子间隔的大小与将出现的事件的概率成正比
( b )编码器选择与下一个发生事件相对应的子间隔,并使它成为新的 “ 当前间隔 ” 。
( 3 )最后输出的 “ 当前间隔 ” 的下边界就是该给定事件序列的算术编码。
在算术编码中需要注意几个问题:
( 1 )由于实际计算机的精度不可能无限长,运算中出现溢出是一个明显的问题,但多数及其都有 16 位, 32 位或者 64 位的精度,因此这个问题可以使用比例缩放方法解决。
( 2 )算术编码器对整个消息只产生一个码字,这个码字是在间隔 [0,1) 中的一个实数,因此译码器在接受到表示这个实数的所有位之前不能进行译码。
( 3 )算术编码是一种对错误很敏感的编码方法,如果有一位发生错误就会导致整个消息译错。
算术编码伪代码
定义一些变量,设 Low 和 High 分别表示 “ 当前间隔 ” 的下边界和上边界;
CodeRange 为编码间隔的长度,即 " 当前间隔 " 的长度;
LowRange(symbol) 和 HighRange(symbol) 分别代表为了事件 symbol 的编码间隔下边界和上边界。
如果 symbol 的编码间隔固定不变,则为静态编码;
反之,如果 symbol 的编码间隔随输入事件动态变化,则为自适应编码。
算术编码的编码过程可用伪代码描述如下:
| set Low to 0 set High to 1 while there are input symbols do take a symbol CodeRange = High – Low High = Low + CodeRange *HighRange(symbol) Low = Low + CodeRange * LowRange(symbol) end of while output Low |
算术编码解码过程用伪代码描述如下:
| get encoded number do find symbol whose range straddles the encoded number output the symbol range = symbo.LowValue – symbol.HighValue substracti symbol.LowValue from encoded number divide encoded number by range until no more symbols |
静态的算术编码
算术编码器的编码解码过程可用例子演示和解释。
例 1 :假设信源符号为 { A , B , C , D} ,这些符号的概率分别为 { 0.1 , 0.4 , 0.2 , 0.3 } ,根据这些概率可把间隔 [0 , 1] 分成 4 个子间隔: [0 , 0.1] , [0.1 , 0.5] , [0.5 , 0.7] , [0.7 , 1] ,其中 [x , y] 表示半开放间隔,即包含 x 不包含 y 。上面的信息如下表。
表 信源符号,概率和初始编码间隔
| 符号 | A | B | C | D |
| 概率 | 0.1 | 0.4 | 0.2 | 0.3 |
| 初始编码间隔 | [0, 0.1) | [0.1, 0.5) | [0.5, 0.7) | [0.7, 1] |
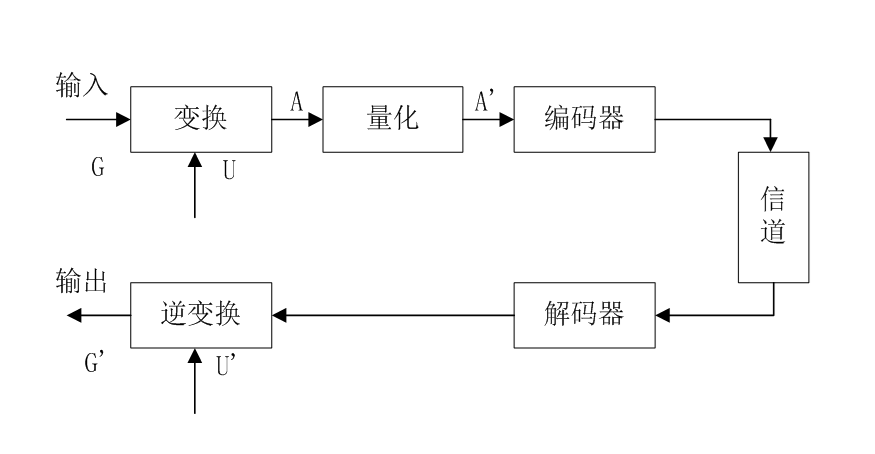
如果二进制消息序列的输入为: C A D A C D B 。
编码时首先输入的符号是 C ,找到它的编码范围是 [0.5 , 0.7] 。由于消息中第二个符号 A 的编码范围是 [0 , 0.1] ,因此它的间隔就取 [0.5 , 0.7] 的第一个十分之一作为新间隔 [0.5 , 0.52] 。
依此类推,编码第 3 个符号 D 时取新间隔为 [0.514 , 0.52] ,编码第 4 个符号 A 时,取新间隔为 [0.514 , 0.5146] , … 。
消息的编码输出可以是最后一个间隔中的任意数。整个编码过程如下图所示。
图 算术编码过程举例
取一个 (0.5143876~0.514402) 之间的数: 0.5143876
(0.5143876)D ≈ (0.1000001)B ,去掉小数点和前面的 0 ,得 1000001 。
所以: cadacdb 的编码 =1000001 ,长度为 7 。
十进制小数转换为二进制参考:点击打开链接
编码和译码的全过程分别表示如下。
表 编码过程
| 步骤 | 输入符号 | 编码间隔 | 编码判决 |
| 1 | C | [0.5, 0.7] | 符号的间隔范围[0.5, 0.7] |
| 2 | A | [0.5, 0.52] | [0.5, 0.7]间隔的第一个1/10 |
| 3 | D | [0.514, 0.52] | [0.5, 0.52]间隔的最后一个1/10 |
| 4 | A | [0.514, 0.5146] | [0.514, 0.52]间隔的第一个1/10 |
| 5 | C | [0.5143, 0.51442] | [0.514, 0.5146]间隔的第五个1/10开始,二个1/10 |
| 6 | D | [0.514384, 0.51442] | [0.5143, 0.51442]间隔的最后3个1/10 |
| 7 | B | [0.5143836, 0.514402] | [0.514384,0.51442]间隔的4个1/10,从第1个1/10开始 |
| 8 | 从[0.5143876, 0.514402]中选择一个数作为输出:0.5143876 | ||
表 译码过程
| 步骤 | 间隔 | 译码符号 | 译码判决 |
| 1 | [0.5, 0.7] | C | 0.51439在间隔 [0.5, 0.7) |
| 2 | [0.5, 0.52] | A | 0.51439在间隔 [0.5, 0.7)的第1个1/10 |
| 3 | [0.514, 0.52] | D | 0.51439在间隔[0.5, 0.52)的第7个1/10 |
| 4 | [0.514, 0.5146] | A | 0.51439在间隔[0.514, 0.52]的第1个1/10 |
| 5 | [0.5143, 0.51442] | C | 0.51439在间隔[0.514, 0.5146]的第5个1/10 |
| 6 | [0.514384, 0.51442] | D | 0.51439在间隔[0.5143, 0.51442]的第7个1/10 |
| 7 | [0.51439, 0.5143948] | B | 0.51439在间隔[0.51439,0.5143948]的第1个1/10 |
| 8 | 译码的消息:C A D A C D B | ||
在上面的例子中,我们假定编码器和译码器都知道消息的长度,因此译码器的译码过程不会无限制地运行下去。实际上在译码器中需要添加一个专门的终止符,当译码器看到终止符时就停止译码。
为什么说算术编码压缩率更高?
算术编码可以对一个二进制序列进一步编码,得到比原序列更小的编码结果。
例如,假设二进制序列信源符号为 { 1,0} ,如果消息序列的输入为 1101 。
则符号 1 和 0 的概率分别为 : 符号 1 的概率 3/4 ,符号 0 的概率 1/4 。整个编码过程如图所示。
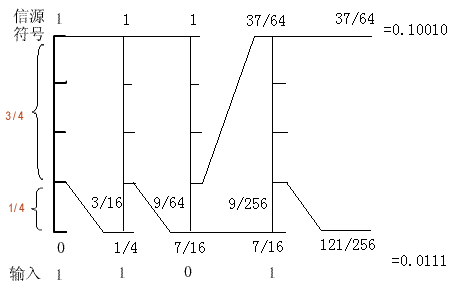
算术编码的结果:
下界 =121/256 ,即 0.47265625 或二进制 0.0111 ;
上界为 37/64 ,即 0.578125 或二进制 0.10010 。
在该区间范围内任取一个数,例如 0.5 (对应二进制 0.1 ),只取小数点后边的部分,即 1 。
这样,原来的 1101 序列就可以用编码 1 来代替。
自适应的算术编码
自适应模型中,在编码开始时,各个符号出现的概率相同,都为 1/n 。随着编码的进行再更新出现概率。另外,在计算时理论上要使用无限小数。这里为了说明方便,四舍五入到小数点后 4 位。
举个例子来说明自适应算术编码。
假设一份数据由 “A” 、 “B” 、 “C” 三个符号组成。现在要编码数据 “BCCB” ,编码过程如图所示。
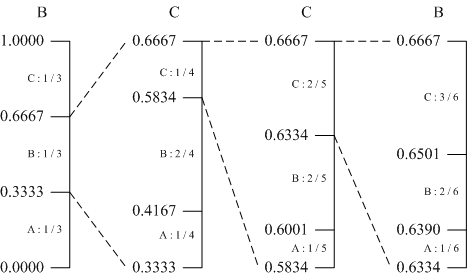
( 1 )算术编码是从区间 [0,1) 开始。这时三个符号的概率都是 1/3 ,按照这个概率分割区间。
( 2 )第一个输入的符号是 “B” ,所以我们选择子区间 [0.3333,0.6667) 作为下一个区间。
( 3 )输入 “B” 后更新概率,根据新的概率对区间 [0.3333,0.6667) 进行分割。
( 4 )第二个输入的符号是 “C” ,选择子区间 [0.5834,0.6667) 。
( 5 )以此类推,根据输入的符号继续更新频度、分割 区间、选择子区间,直到符号全部编码完成。
我们最后得到的区间是 [0.6390,0.6501) 。输出属于这个区间的一个小数,例如 0.64 。那么经过算 术编码的压缩,数据 “BCCB” 最后输出的编码就是 0.64 。
自适应模型的解码
算术编码进行解码时仅输入一个小数。整个过程相当于编码时的逆运算。解码过程是这样:
( 1 )解码前首先需要对区间 [0,1) 按照初始时的符号频度进行分割,然后观察输入的小数位于哪个子区间,输出对应的符号。
( 2 )之后选择对应的子区间,然后从选择的子区间中继续进行下一轮的分割。
( 3 )不断的进行这个过程,直到所有的符号都解码出来。
在我们的例子中,输入的小数是 0.64 。
( 1 )初始时三个符号的概率都是 1 / 3 ,按照这个概率分割区间。
( 2 )根据上图可以发现 0.64 落在子区间 [0.3333,0.6667) 中,于是可以解码出 "B" ,并且选择子区间 [0.3333,0.6667) 作为下一个区间。
( 3 )输出 “B” 后更新频度,根据新的概率对区间 [0.3333,0.6667) 进行分割。
( 4 )这时 0.64 落在子 区间 [0.5834,0.6667) 中,于是可以解码出 “C” 。
( 5 )按照上述过程进行,直到所有的符号都解码出来。
可见,只需要一个小数就可以完整还原出原来的所有数据。
自适应模型的整数编码方式
上边介绍的编码都是得到一个 [0,1) 内的小数,下面说明整数编码方式,以 8 位编码为例,阐述算术编码和解码过程 .
例如对字符串 "ababcab" 进行编解码,最终得到 8 位编码。
确定上下界:由于 8 位的取值范围是 [0,255] ,因此下界为 0 ,上界为 255 。
符号概率:编码开始时, a 、 b 、 c 的出现概率都是 1/3 。
编码过程
( 1 ) "ababcab" 第 1 个字符为 a ,初始化时三个字符出现概率相同,因此 a 的编码间隔为 [0,1/3] ,即 LowRange(a) = 0, HighRange(a) = 1/3
( 2 )更新上下界的值为 [0, 85] ,根据伪代码:
| CodeRange = High – Low High = Low + CodeRange *HighRange(symbol) Low = Low + CodeRange * LowRange(symbol) |
计算得到:
| CodeRange = 255 - 0 = 255 High = 0 + 255 * 1/3 = 85 Low = 0 + 255 * 0 = 0 |
此时各个符号的编码间隔动态调整为: a : [0, 2/4] , b : [2/4, 3/4] , c : [3/4, 1]
( 3 ) "ababcab" 第 2 个字符为 b ,取编码间隔 [2/4, 3/4] ,并更新上下界:
| CodeRange = 85 - 0 = 85 High = 0 + 85 * 3/4 = 63 (向下取整) Low = 0 + 85 * 2/4 = 43 (向上取整) |
( 4 )同理可得到 "ababcab" 第 3 、 4 个字符 a 、 b 的编码。
( 5 )计算 "ababcab" 第 5 个字符 c 的编码,此时 High=49 , Low=49 。因为是有限整数,每次又是取的上一区间的子区间 ,high 和 low 趋于相等是必然的。
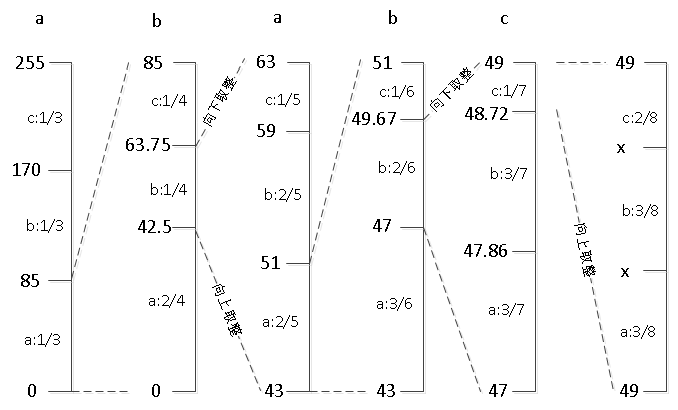
图 8 位编码过程
我们在此使用 High 和 L ow 向左移的方式进行扩大区间
极限情况:位移后 Low 的二进制首位为 0 ,其他位为全 1 ; High 的二进制首位为 1 ,其他位为全 0 。如 8 位时: Low=01111111B , High=10000000B 的情况。
出现这种情况时,我们可以规定,保留相同位,并将该区间扩展至原始区间,如 8 位是 [0, 255) , 32 位是 [0, 0xffffffff) 。
位移时遵循两个原则 :
(1) 设 Total 为字符表中的字符数 + 已出现的字符数(即编码间隔的分母),需保证 High-Low>=total ,否则继续位移
(2) 保证 [Low, High] 在上一个 [Low, High] 的子区间。 ( 实际上这条已经在取整运算时得到了保证 )
上下界左移 1 位后溢出位用新变量 out 存储,同时,用 bits 保存 out 到底存了几个位。 (0B 表示二进制 0)
| 位移轮数 | Total | Out | Bits | High | Low |
| 1 | 7 | 0 B | 1 | 98 (49<<1) | 94 (47<<1) |
| 2 | 7 | 00B | 2 | 196 (98<<1) | 188 (94<<1) |
此时满足两条 " 位移原则 " ,继续编码。
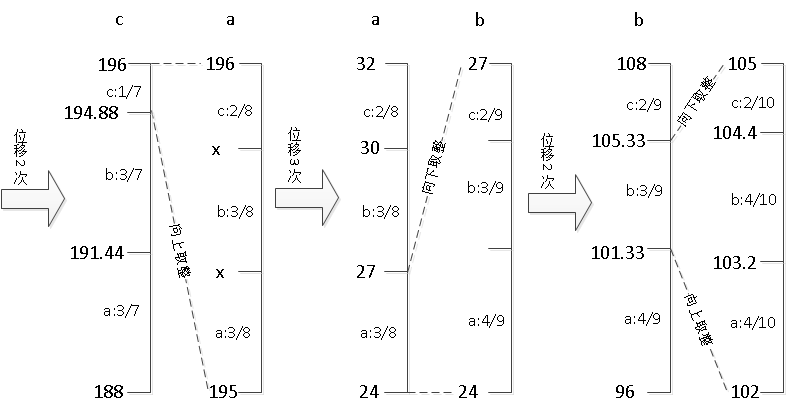
图 位移和继续编码
编码第 6 个字符 a 和第 7 个字符 b ,分别需要位移 3 次和 2 次。
表 编码第 6 个字符 a 时位移 3 次
| 位移轮数 | Total | Out | Bits | High | Low |
| 1 | 8 | 0 01B | 3 | 136 | 134 |
| 2 | 8 | 00 11B | 4 | 16 (136<<1) | 12 (134<<1) |
| 3 | 8 | 00110B | 5 | 32 | 24 |
表 编码第 7 个字符 b 时位移 2 次
| 位移轮数 | Total | Out | Bits | High | Low |
| 1 | 9 | 0 01100B | 6 | 54 | 48 |
| 2 | 9 | 00 11000B | 7 | 108 | 96 |
编码结束时最后的区间是 [102, 105] ,后面已经没有字符,不需要位移了。记下此区间的某一个数即可,这里选 magic=104 。
整个编码过程结束,得到编码结果:
out=0011000B , bits=7 , magic=104 。
编码全过程如图
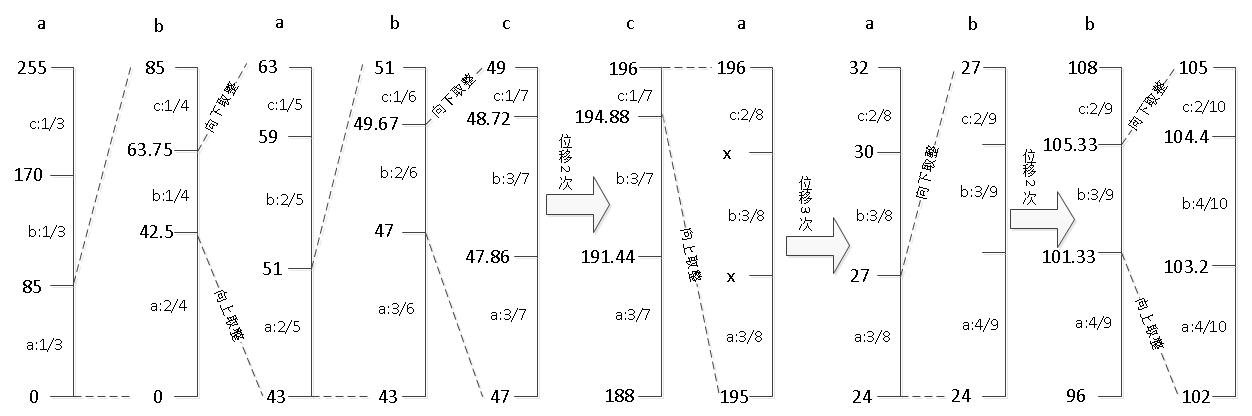
图 编码全过程
解码过程
根据编码结果: out=0011000B , bits=7 , magic=104 。( Total=9 可选)
将 magic 转换为 8 位二进制,拼在 out 后,得到 15 位数:
| X = out<<8 | magic = 0011000 01101000B |
( 1 )取 X 的高 8 位,令 z = 00110000B = 48;
( 2 ) 48 是 a 所在区间,于是解码得到字符 "a"
( 3 )更新上下界为 [0, 85] ,更新各符号的编码间隔 a : [0, 2/4] , b : [2/4, 3/4] , c : [3/4, 1]
( 4 )满足位移原则 1 ,不需要位移,继续解码。 48 是 b 所在区间,解码得到字符串 "ab" 。更新上下界和编码间隔;
( 5 )继续解码得到字符串 ”abab” ,此时上下界为 [47, 49] ,不满足位移原则 1 ,需要位移;
( 6 )去掉 z 的首位,即左边第一位;取 X 中下一位接到 z 右边,得到 z = 01100001B = 97 。
Total=7 ,上下界 [94, 98] ,不满足原则 1 ,继续位移得到 z = 11000011B = 195 ;
满足原则 1 ,继续解码;
Total=7 ,上下界 [94, 98] ,不满足原则 1 ,继续位移得到 z = 11000011B = 195 ;
满足原则 1 ,继续解码;
( 7 ) 195 是 c 所在区间,解码得到字符串 "ababc" ;
( 8 )此时需要位移,位移 3 次,得到 z = 00001101B = 25 ,解码得到字符串 "ababca" ;
( 9 )此时需要位移,位移 2 次, Total=9 ,上下界 [96, 108) ,满足位移原则 1 。
但是 z = 00110100B = 52 ,不在上下界范围内,于是 z 位移 z = 01101000B = 104 ( 到达 X 末尾 ) ;
解码得到字符串 "ababcab" ;
但是 z = 00110100B = 52 ,不在上下界范围内,于是 z 位移 z = 01101000B = 104 ( 到达 X 末尾 ) ;
解码得到字符串 "ababcab" ;
( 10 )此时需要位移,位移 1 次,上下界为 [152, 164) ,满足位移原则 1 。
但是 z = 01101000B = 104 ,不在上下界范围内, z 需要位移。此时 X 已经到达末尾, z 不能继续位移,此时编码结束。
(若编码结果中有 Total=9 信息,在上一步就可以结束)
但是 z = 01101000B = 104 ,不在上下界范围内, z 需要位移。此时 X 已经到达末尾, z 不能继续位移,此时编码结束。
(若编码结果中有 Total=9 信息,在上一步就可以结束)
JPEG 中为什么没有使用算术编码
因为算术编码的使用存在版权问题。
JPEG 标准说明的算术编码的一些变体方案属于 IBM , AT&T 和 Mitsubishi 拥有的专利。要合法地使用 JPEG 算术编码必须得到这些公司的许可。
像 JPEG 这种开源的标准,虽然传播广泛,但是大家都是免费在用,明显没有钱买那么贵的专利。
参考
http://blog.csdn.net/adam_tu/article/details/7696455
http://blog.sina.com.cn/s/blog_b2e97e5a01019p30.html
http://www.mdshnx.com/server/mmx/mmx_jpeg.htm